やること
DQNのプログラムは非常に高度ですが、勉強会で配布されたコードは比較的シンプルで読み解きやすいです。今日は、DQNで地雷原を進むゲームを解いてみましょう。
環境とコード
Google Colaboratoryが利用可能です。


ゲームのルール
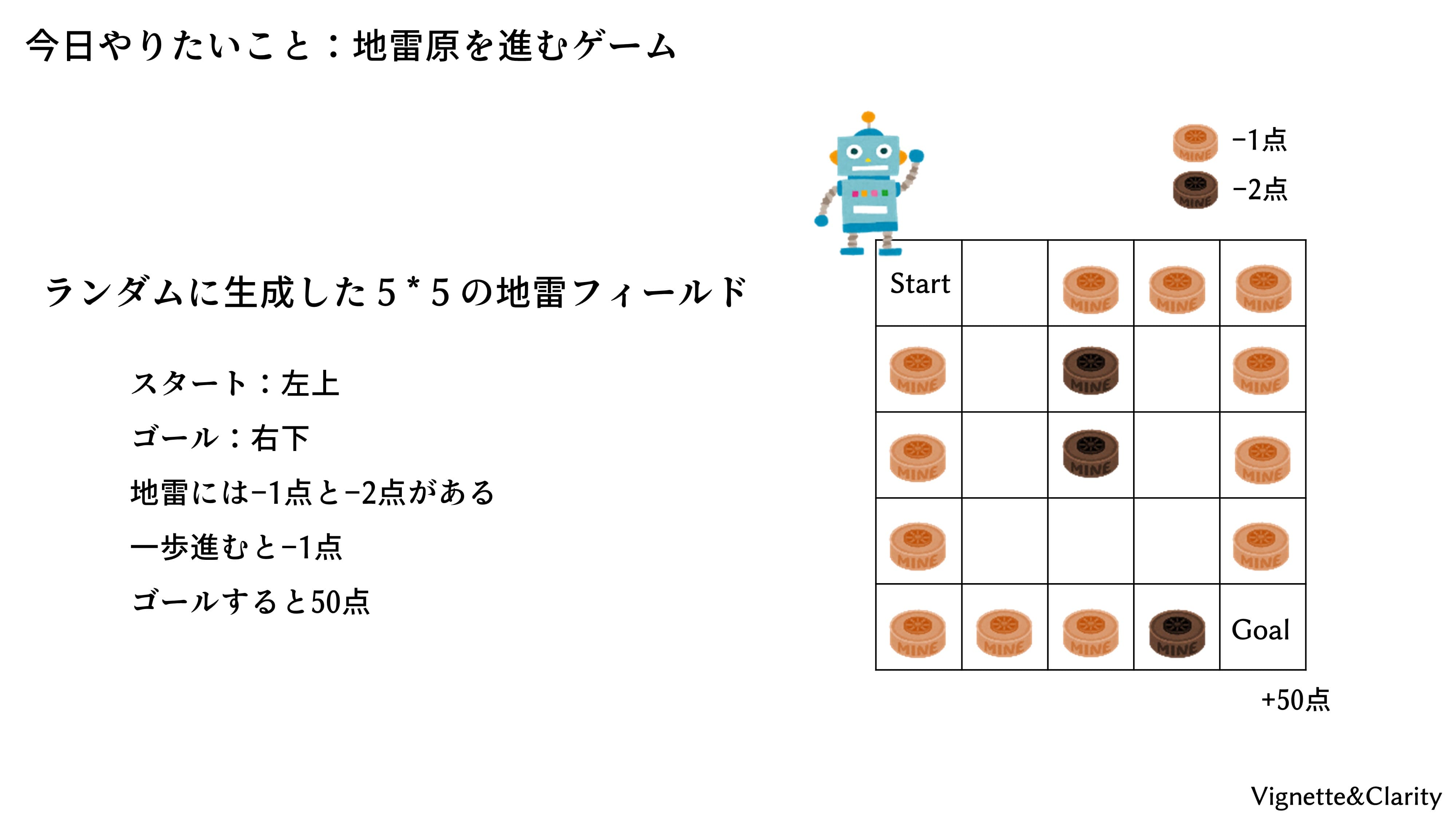
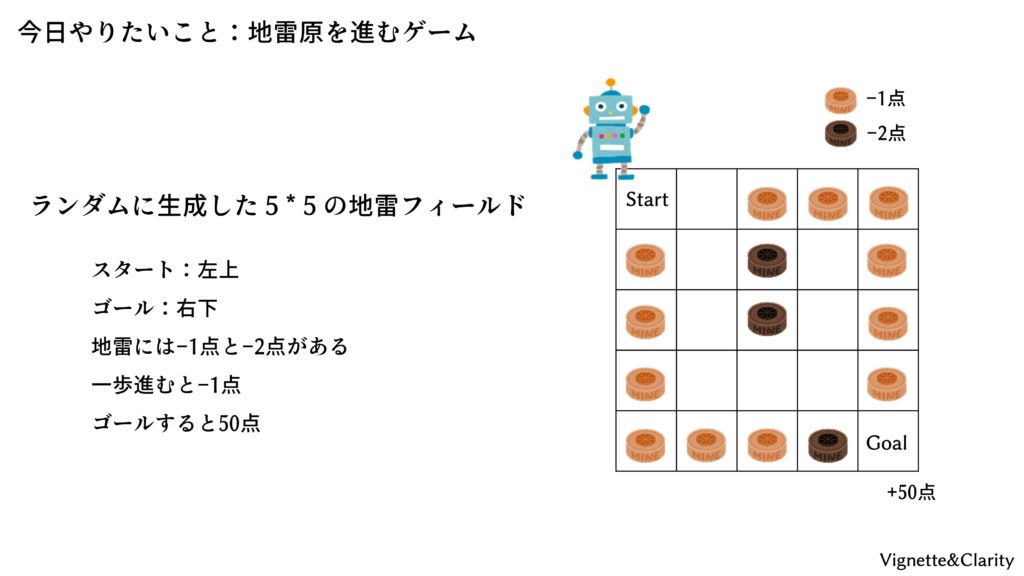
できるだけ地雷を踏まないように、左上から右下のゴールを目指すゲームです。一歩進むごとに-1点、地雷には-1点と-2点のものがあり、繰り返し踏むことができます。ゴールすると+50点もらえます。盤面はランダムに自動生成されますので、臨機応変な判断が必要です。
ニューラルネットモデル
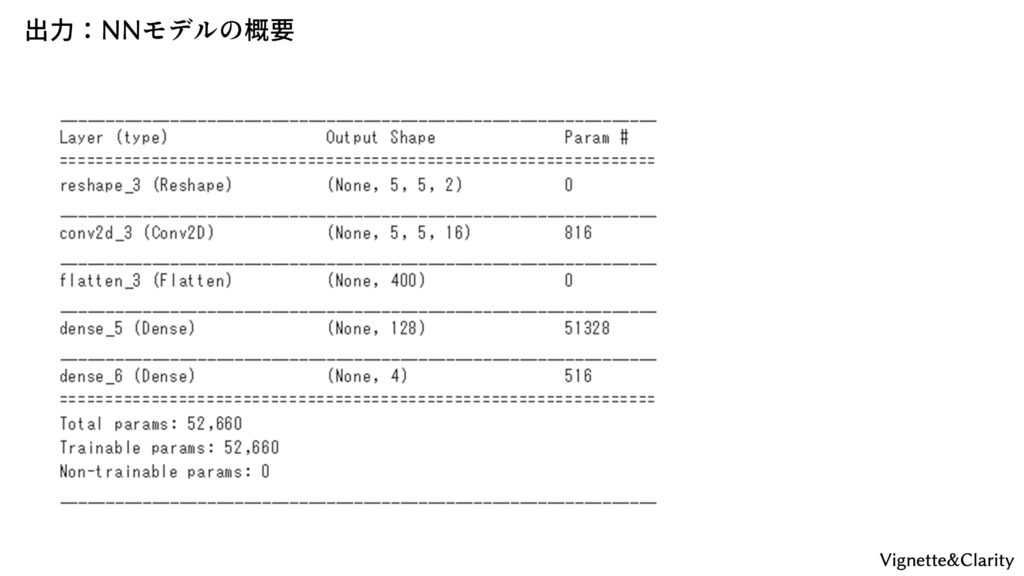
ニューラルネットは「状態」を入力とし、「行動」を出力します。入力は5*5*2chで、1ch目は地雷情報、2ch目はエージェントの位置情報を含んでいます。これを畳み込んだり全結合したりし、最終的に4ユニットのOne-hotな出力とします。例えば、(1, 0, 0, 0)であれば「上移動」、(0, 1, 0, 0)であれば「下移動」 といった感じです。




プログラムを実行する
配布されたプログラムは、ゲームの定義(上半分)とDQN(下半分)から成ります。オンライン実行環境であるGoogle Colaboratoryは、Kerasは初期装備ですが、ゲーム環境を記述するための「gym」や、強化学習用のパッケージ「Keras-rl」は追加でpipインストールしなければいけません。
- !pip install gym
- !pip install keras-rl

学習の結果
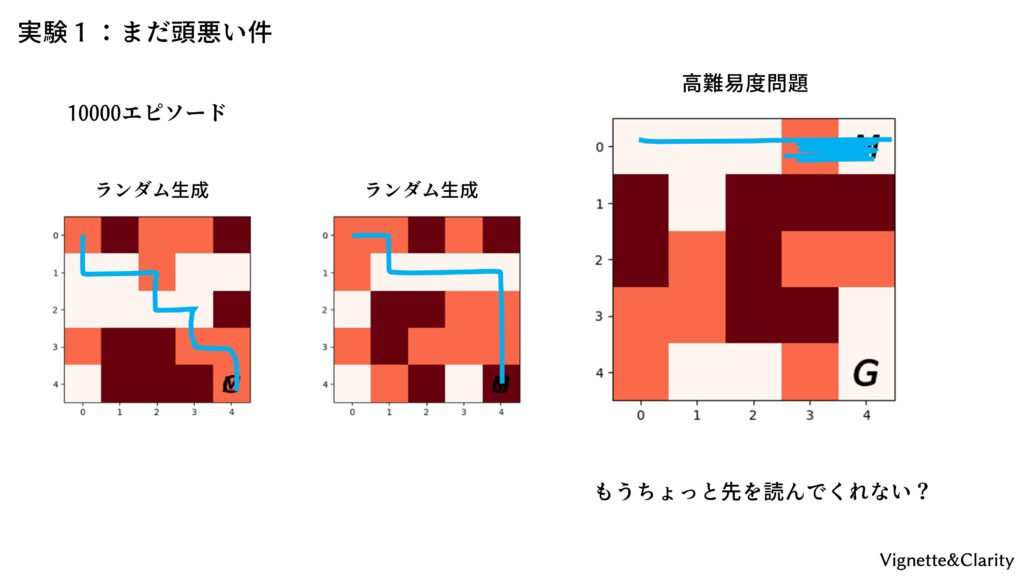
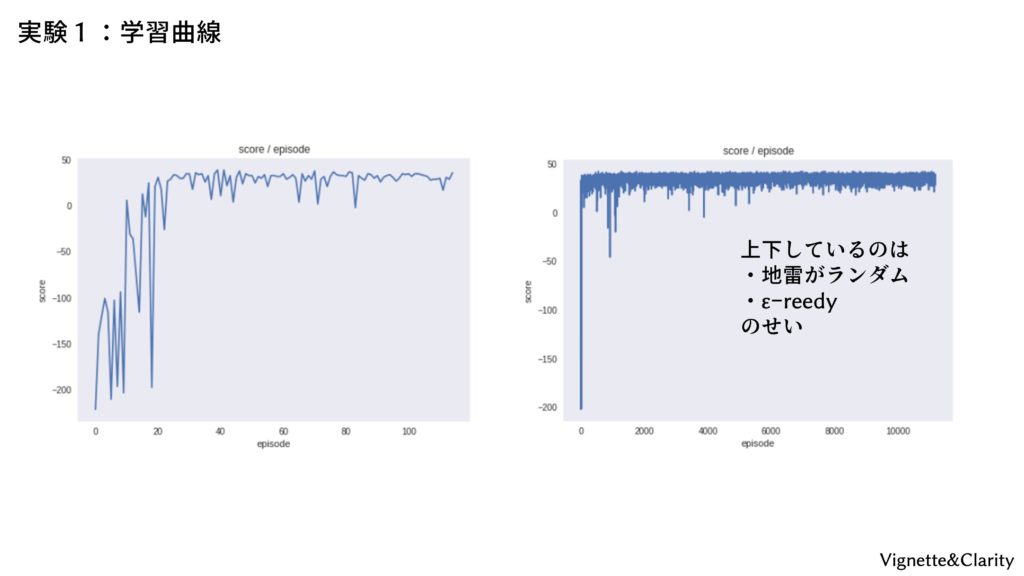
実行すると、1エピソード(ゴールするか100回行動したら終了)ごとに1行の出力が出ます。はじめのうちは闇雲に動き回るため、上限の100回まで行動して-100点未満を連発していますが、たまたまゴールを見つけると行動基準が大幅に改善され、以降はスコアが改善していきます。20エピソードにもなると、最短距離である「8ステップでゴール」を連発するようになり、以降はできるだけ地雷を踏まないように学習が進んでいきます。

スコアを縦軸に取った学習曲線を見ると、安定して30~40点を取れるようになっています。+50点(ゴール時)-8点(最短で8歩)-地雷分なので、ちょうどこれくらいの点数になります。
地雷原を進む
指定したエピソードごとに重みとバイアスを保存するようになっているので、固定した盤面でニューラルネットの成長を見てみます。
- 0エピソード・・・ゴールできない
- 100エピソード・・・ゴールできる
- 1000エピソード・・・地雷を避けてゴールできる
- 10000エピソード・・・賢く地雷を避けてゴールできる
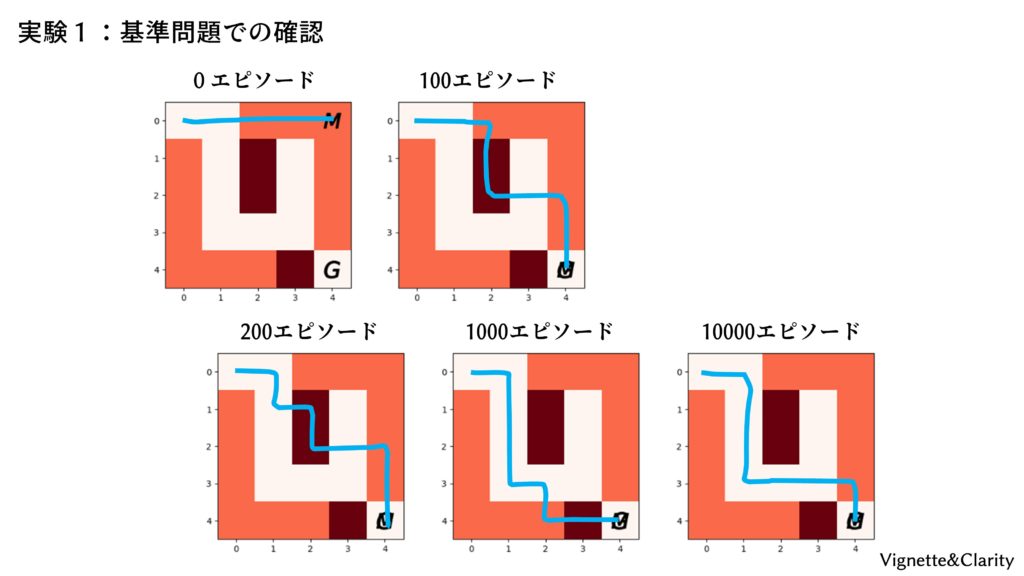
しかし、10000エピソード学習したエージェントでも、盤面をランダム生成して何度か試してみると、まだ賢くないことが分かります。次回はニューラルネットを工夫して、右側の難しい問題にリベンジしてみましょう。