
やること
皆様におかれましては、テキスト生成AIをすでに活用していることと思います。
AIが学習していない特殊な情報を聞きたい場合、あらかじめ資料を与えておいてそれを参照して回答してもらう必要があります。このような枠組みをRetrieval-Augmented Generation(RAG、検索拡張生成)と呼びます。
RAGはネット上にない専門知識を回答してもらうのに有効ですし、企業の内部資料を秘匿したまま構築するクローズドなAIとしての需要も多いです。
このシリーズでは、AWSのサービスの1つであるAmazon Bedrockを使ってClaude3のRAG(検索拡張生成)を構築し、さらにAPI化して外部から呼び出すところまでを詳しく紹介します。
そもそもClaude3はAnthropic社が開発しているLLMモデルです。Claude3のAPIを使うだけであれば、Anthropicで有料プランに登録すれば利用できますが、Amazon Bedrockの中で使えばインフラを気にすることなく様々なAWSのソリューションに統合することができます。
さっそく構築していきましょう。
前提
あらかじめAWSのアカウントを作成し、IAMユーザーを作成しているものとします。
また、AWSのBedrock、S3、Lambda、API Gatewayなどの仕組みについては説明しません。いつも言っていることですが、AWSは百戦錬磨のサーバー担当者でもボロボロ躓くくらい分かりにくく作られています。これはAWSエンジニアという職業ブランドを守るための企業戦略です。
一部、かなりお金のかかるサービスを利用します。数週間、数カ月放置すると何万円、何十万円と請求される可能性があるので、記事に従って必ず削除(停止)してください。しかしながら、AWSはサービスの停止が非常にしにくいシステムであるため、これでも完全に停止できることを保証しません。本記事を参考にしたことによる損害については一切責任を負いません。
Bedrockの開始
まずAWSのトップページに入ります。検索欄に「Amazon Bedrock」と入力し、出てきた「Amazon Bedrock」をクリックします。
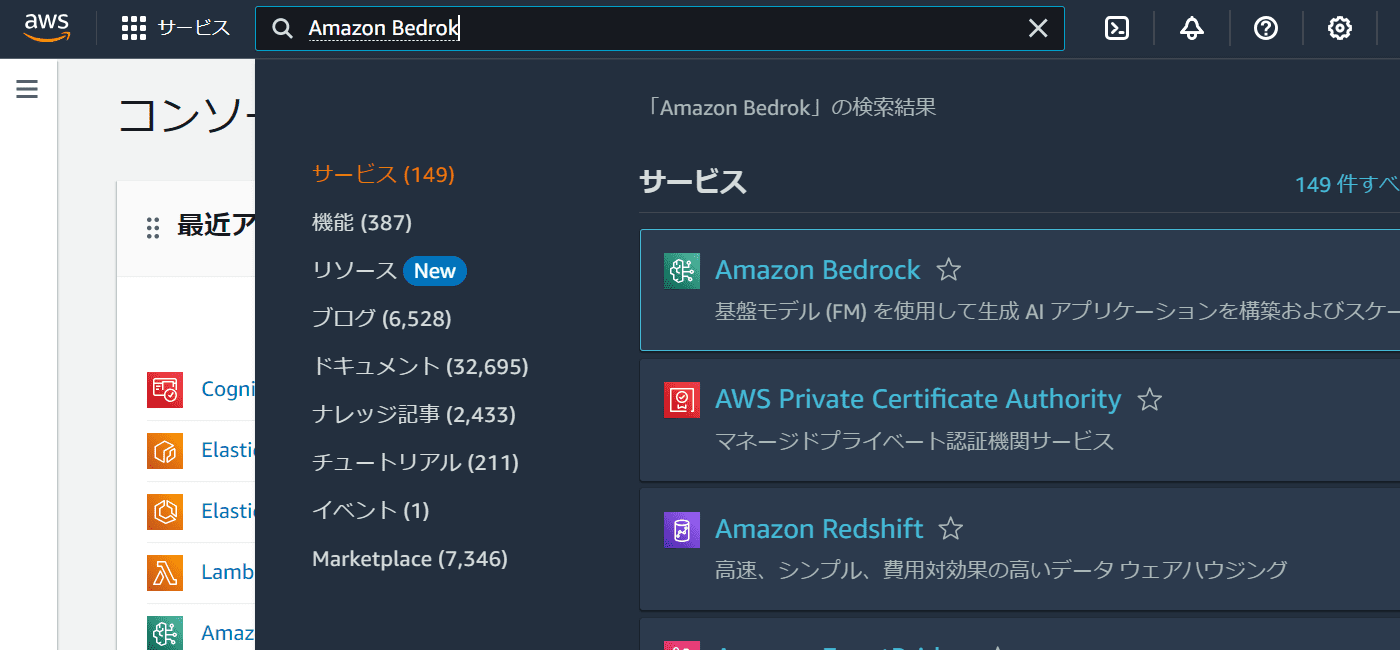
次のような画面に遷移します。東京リージョンでは使えるモデルの種類に制限があるので、リージョンを「バージニア北部」に変更します。右上の「東京」をクリックし、「米国東部(バージニア北部)」をクリックします。
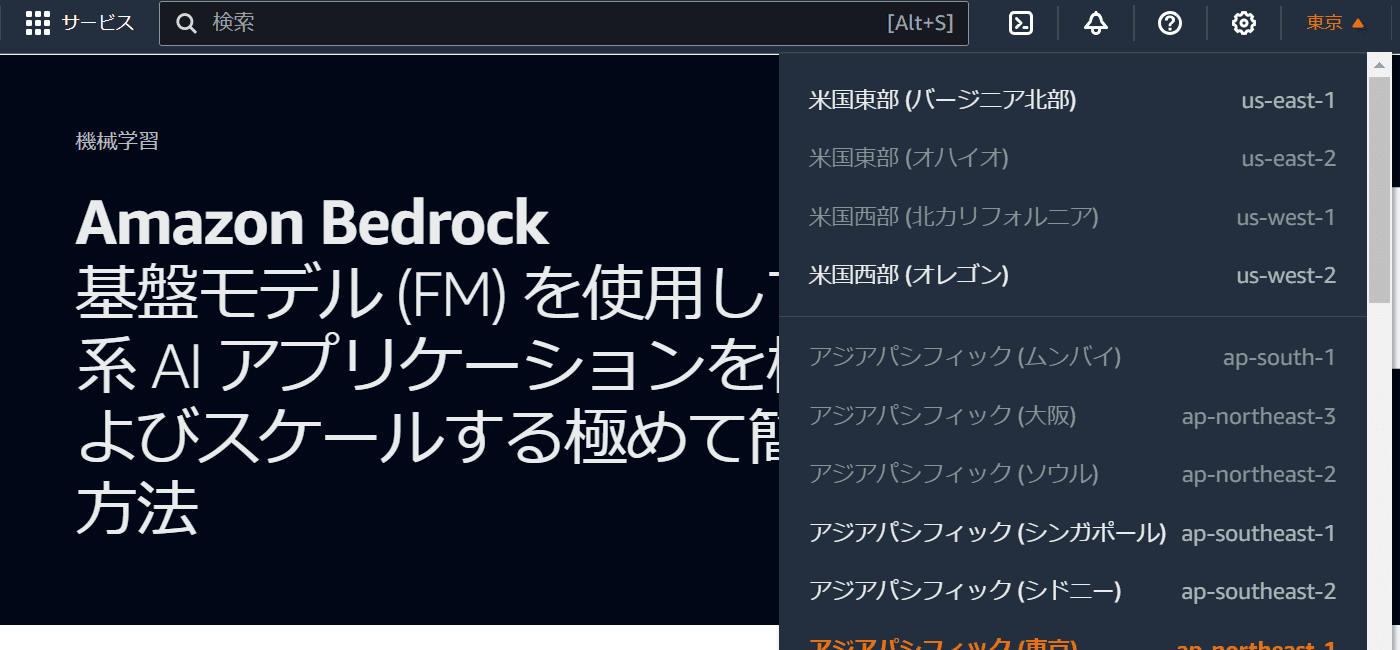
バージニア北部になっていることを確認したら「使用を開始」をクリック。
モデルの選択
AnthropicのCloude3を使用します。「モデルアクセスを管理」をクリック。
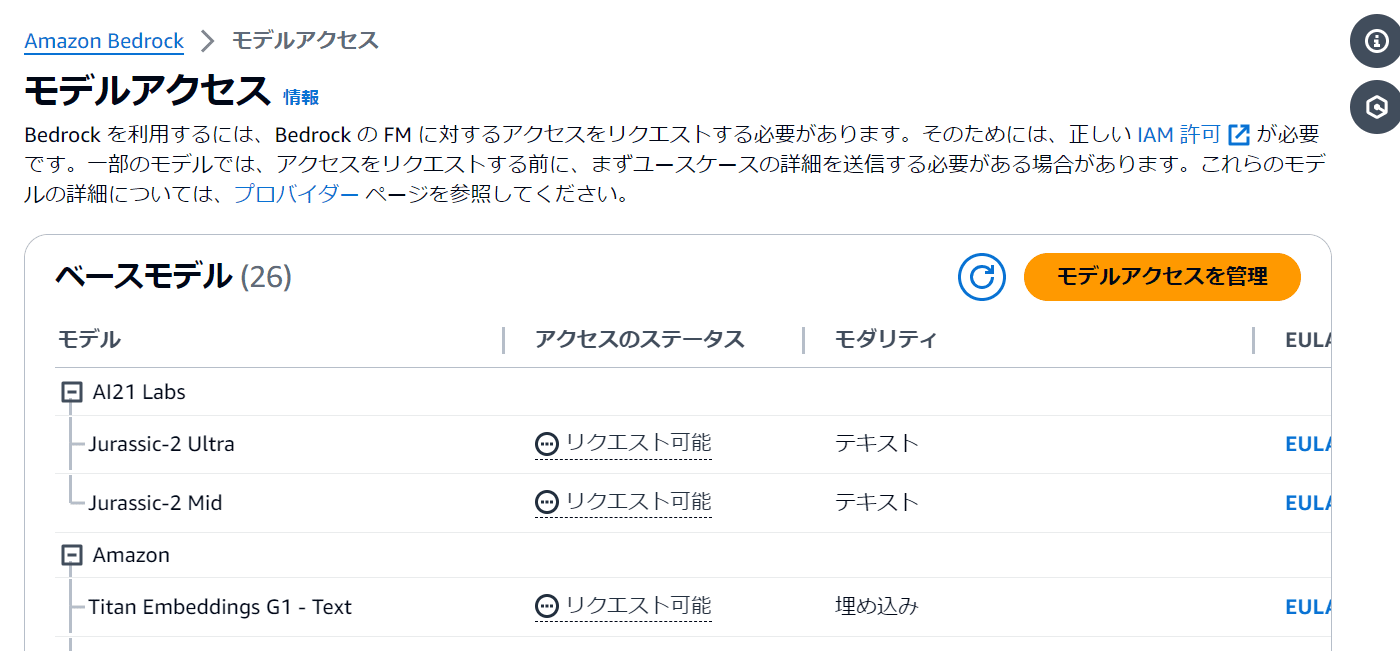
初期状態ではAnthropicのモデルは「ユースケースの詳細は必須です」になっています。そのため、Anthropicに対してリクエストを送る必要があります。「ユースケースの詳細を送信」をクリック。
いくつかの質問があるので入力します。会社名や会社URLは自身の情報を入力し、それ以外の部分は以下の通りです。「送信」をクリック。


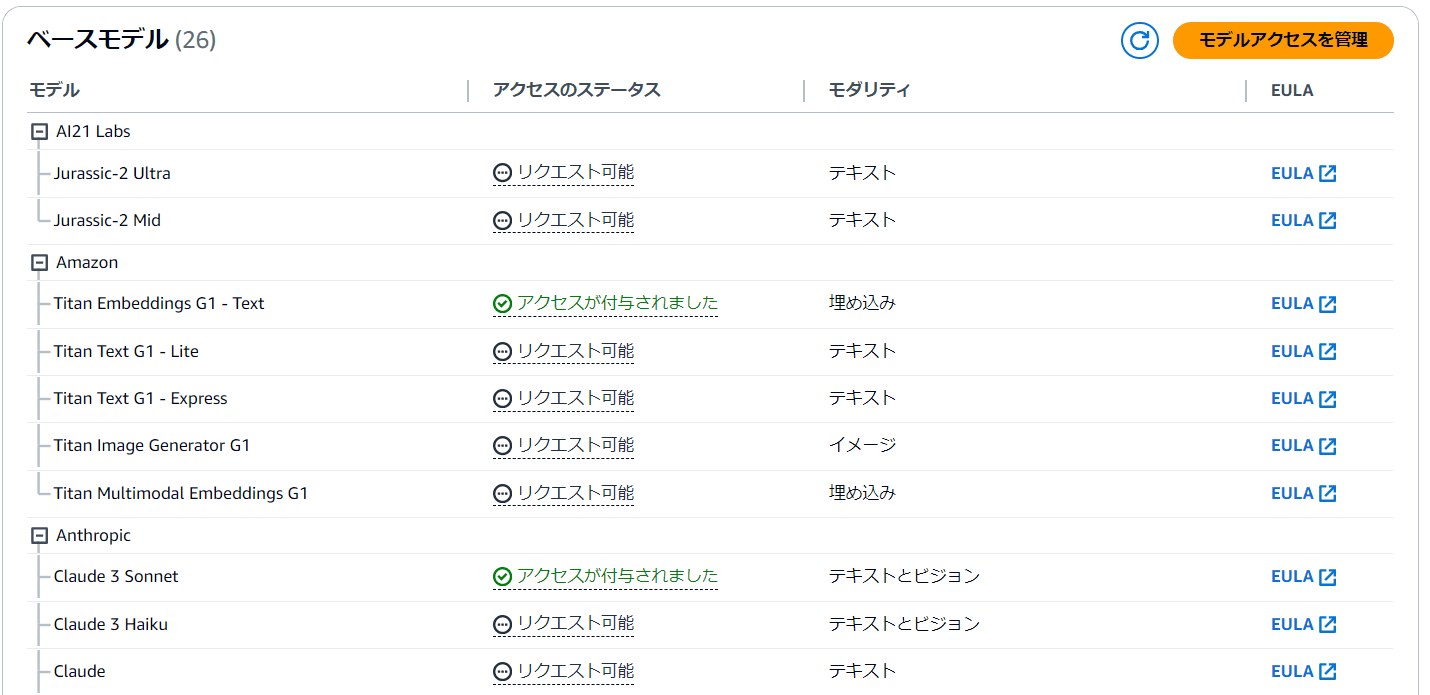
しばらくするとAnthropicのモデルが「リクエスト可能」な状態になります。
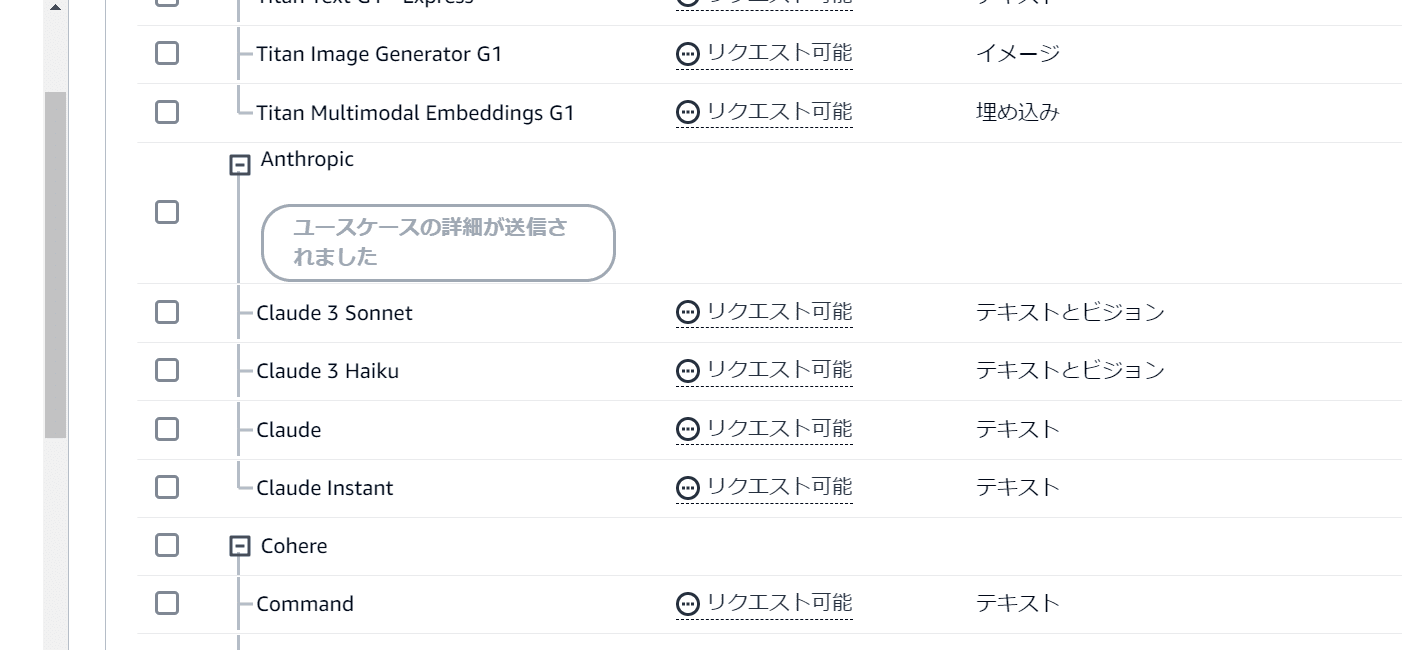
モデルを選択します。次の画像の2つのモデルを選択します。その後、ページの一番下までスクロールし、「モデルアクセスをリクエスト」をクリック。
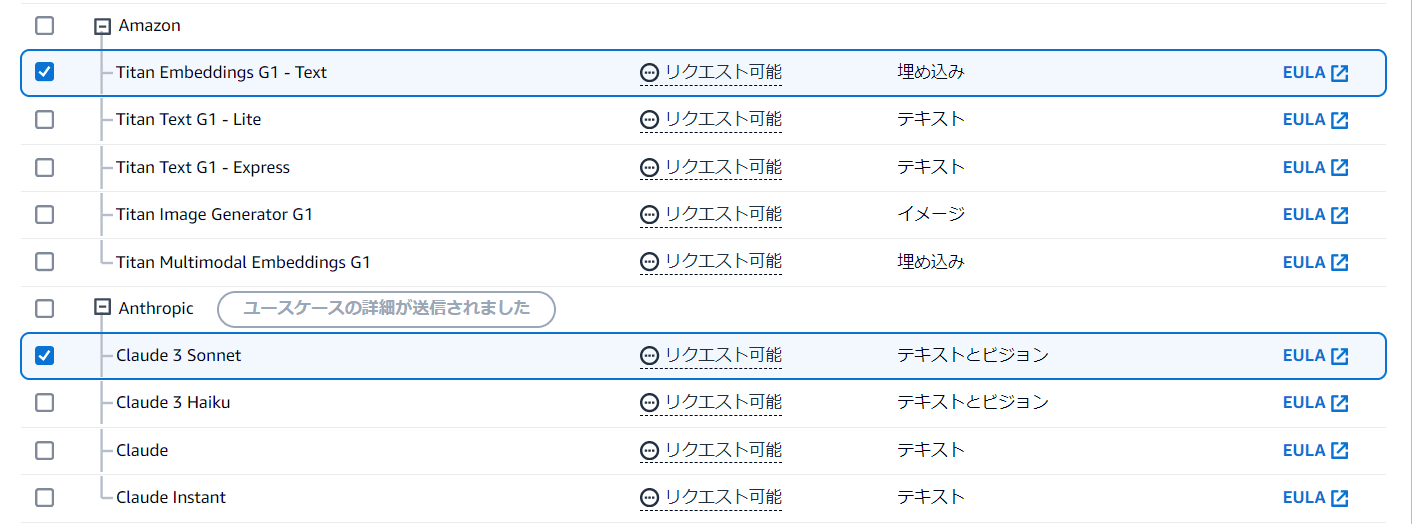
モデルが使用可能になると、アクセスのステータスが「アクセスが付与されました」になります。AmazonのTitanシリーズはすぐに「アクセスが付与されました」になりますが、Anthropicは少し時間がかかります。
モデルの使用
アクセスが付与されるとClaude3が使用できる状態になっています。早速、通常のClaude3を使ってみます。
サイドバーの「プレイグラウンド」から「チャット」をクリック。中央の「モデルを選択」をクリック。
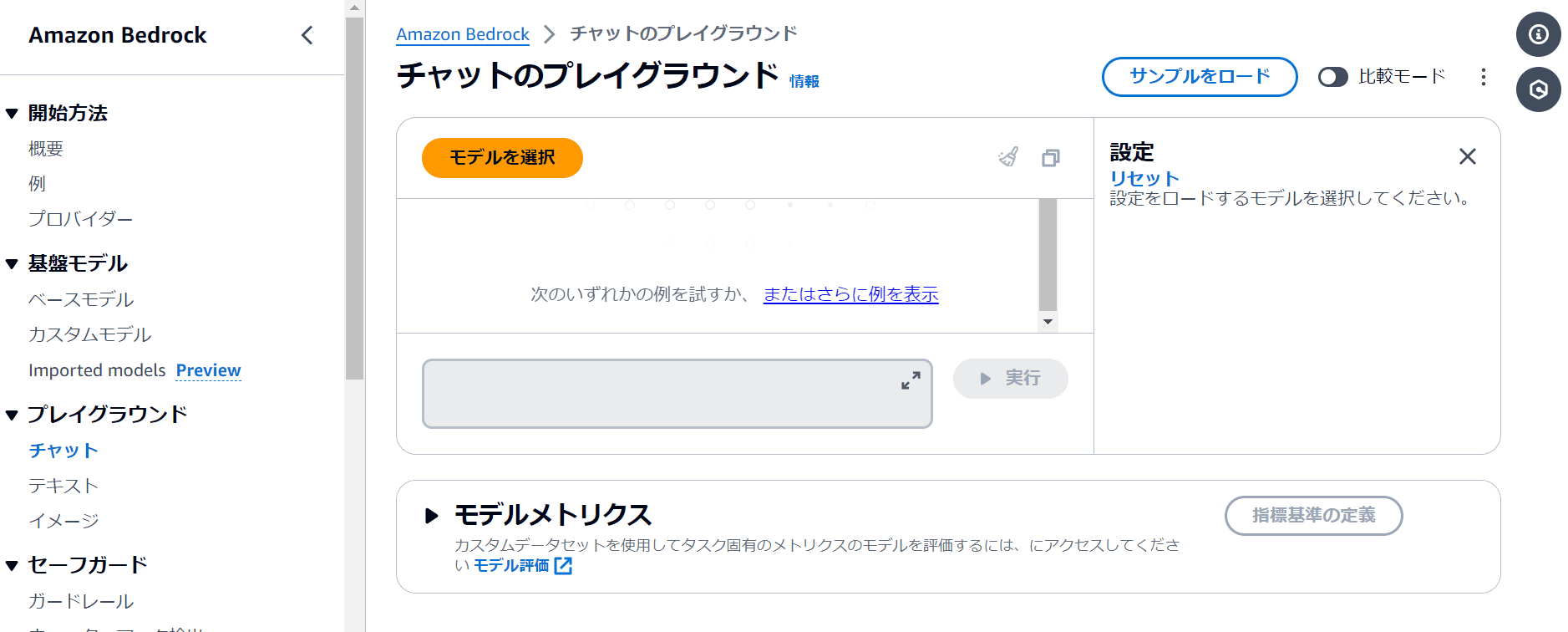
次のようなウィンドウが表示されるので、「Anthropic」、「Claude3 Sonnet」を順番に選択し「適用」をクリック。
後ほどRAGで「食べログの書き込みガイドライン」を記憶させるのですが、記憶させる前の状態で質問をしてみましょう。

この回答は一般論としては妥当ですが、食べログガイドラインに記載されている例ではありません。このように不正確なことを自信満々に回答する現象はハルシネーションと呼ばれます。
つづく
今回はClaude3に普通に質問するところまでできました。
次回は、この回答がRAGによってどのように変わるか見ていきましょう。


