
やること
このシリーズでは、AWSのサービスの1つであるAmazon Bedrockを使ってClaude3のRAG(検索拡張生成)を構築し、さらにAPI化して外部から呼び出すところまでを詳しく紹介しています。前編からご覧ください。
今回はRAG(検索拡張生成)の構築です。
おさらい
前回、「食べログの書き込みガイドライン」の文書を与えずに質問をしました。

この回答は一般論としては妥当ですが、食べログガイドラインに記載されている例ではありません。堂々たるハルシネーションです。
正解はこちらです。(実際にガイドラインに記載されている例)
例)ここのお肉を食べると必ず腹痛になる。(NG:料理が原因でおきた症状に関する口コミ)
https://tabelog.com/help/review_guide/
例)経費削減のためエアコンをつけていない。(NG:お店の経営方針・内部事情に関して、決め付けた口コミ)
例)化学調味料を使っている。(NG:お店の調理方法や材料に関して、決め付けた口コミ)
例)常連になると料金をタダにしてくれることがあるそうです。(NG:一般に公開されていないサービスに関して、決め付けた口コミ)
RAGによってこれがきちんと回答されるかが今回の注目点です。
検索拡張用のデータのアップロード
検索欄に「S3」と入力し、出てきた「S3」をクリック。
「バケットを作成」
任意のバケット名を入力します。
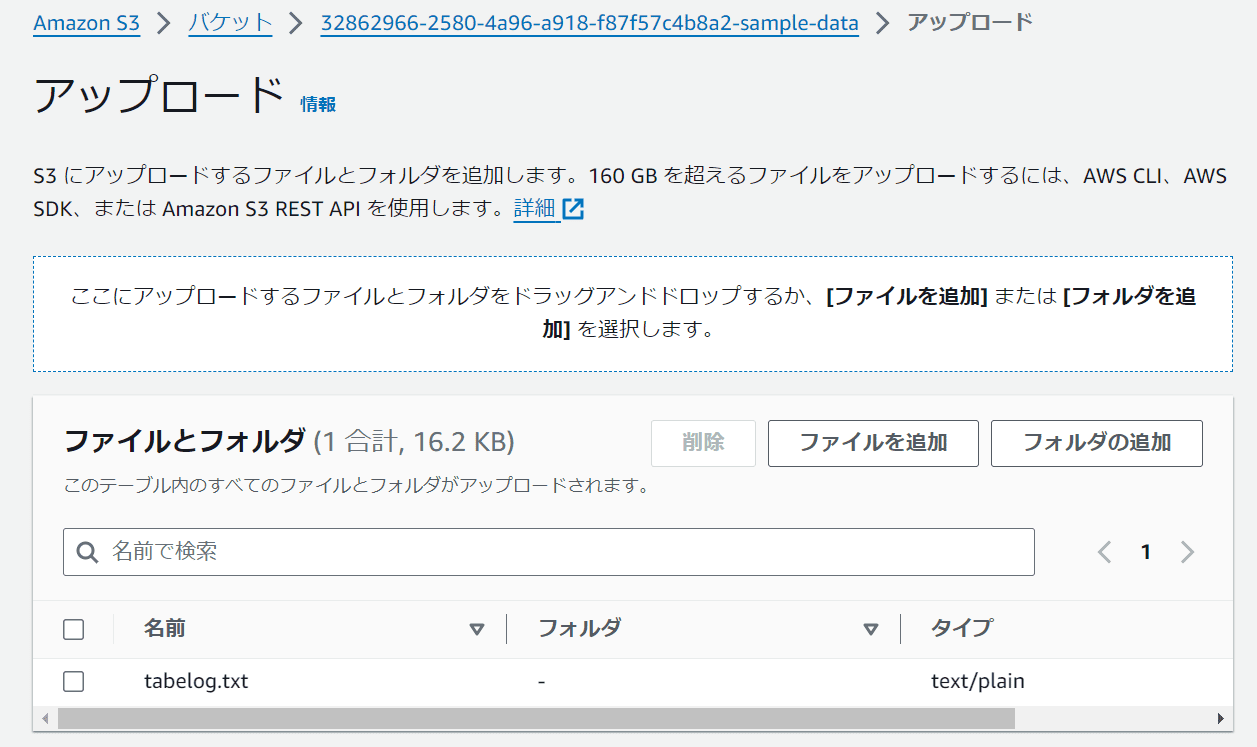
次ような画面になるので「アップロード」をクリック。
ここでは「食べログの口コミガイドライン」を使用します。テキストをコピーして「tabelog.txt」にしました。

ローカルPCにある「tabelog.txt」を選択すると、画面にファイル名が表示されます。画面の下までスクロールし「アップロード」をクリック。
ナレッジベースの作成
Amazon Bedrockのページに移動し、サイドバーの「オーケストレーション」の中の「ナレッジベース」をクリック。
ページを少しスクロールして「ナレッジベースを作成」をクリック。
任意のナレッジベース名を入力します。デフォルト名のままでも問題ありません。

画面下までスクロールし「次へ」。

画面をスクロールし「S3を参照」をクリック。
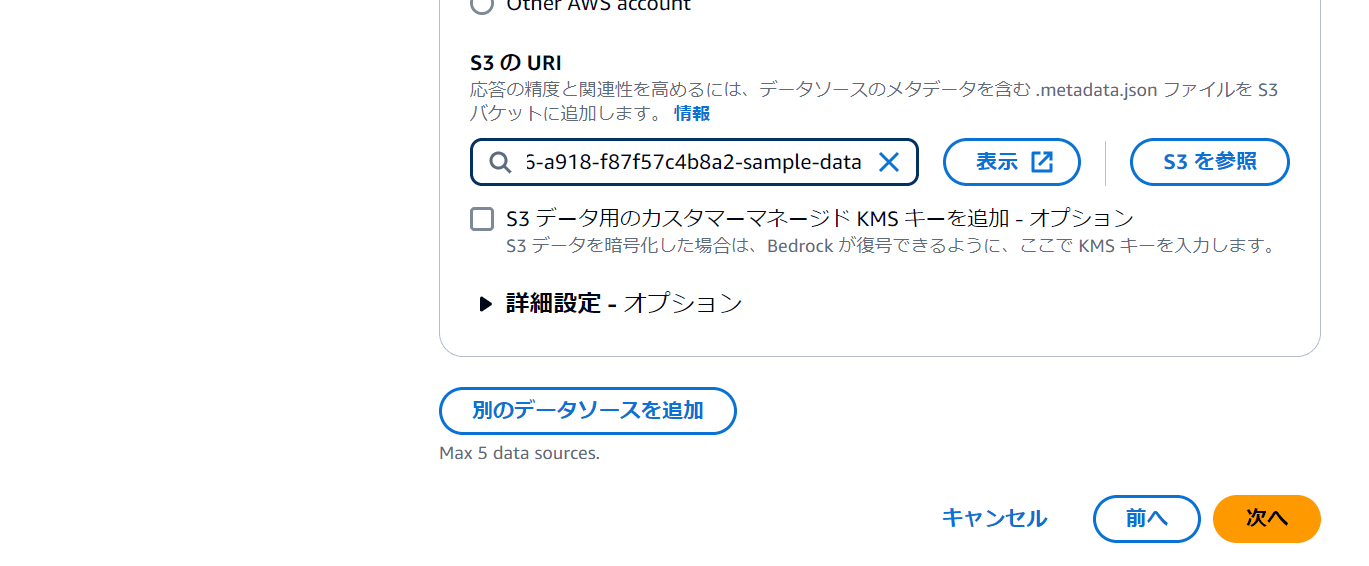
先ほど作成したバケットにチェックを入れ、「選択」をクリック。
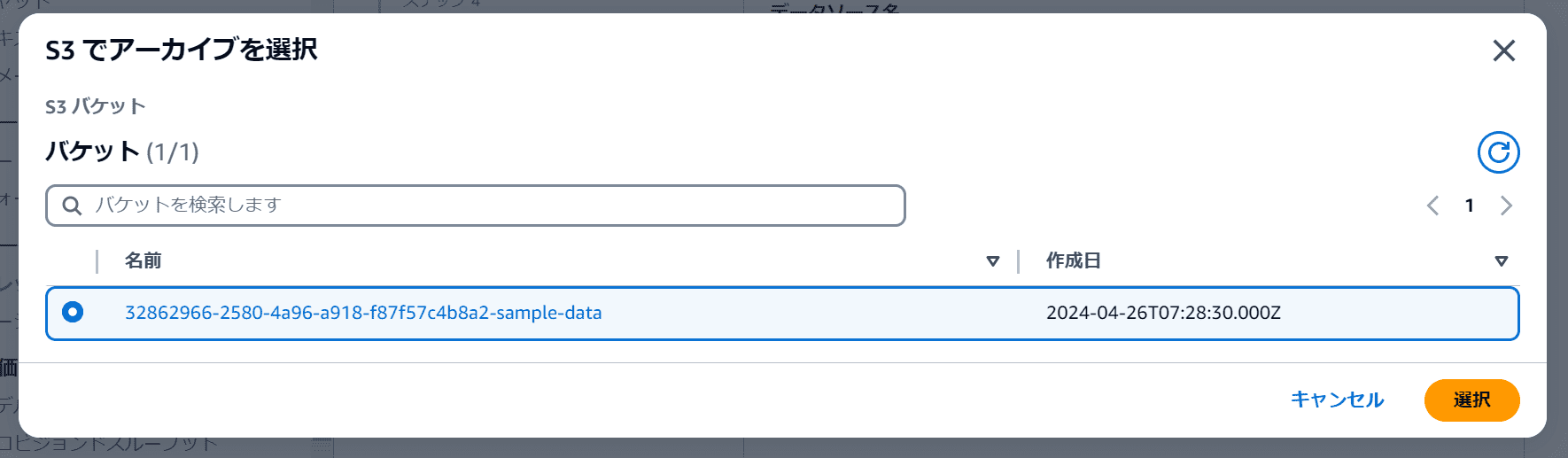
「次へ」
埋め込みモデルに「Titan Embeddings G1 – Text」を選択します。
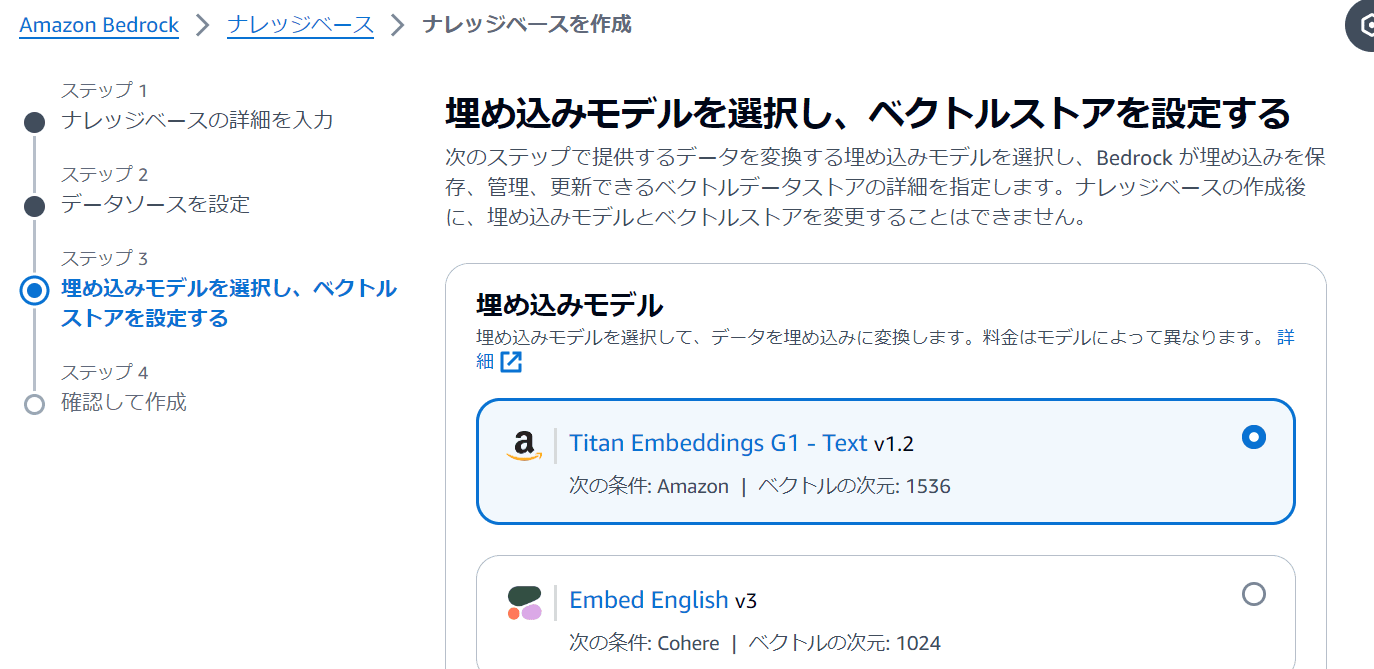
ベクトルデータベースはデフォルトのままで、「次へ」をクリックします。なお、ここで選択したベクトルデータベースは非常にお金のかかるサービスなので、使用後は本記事やマニュアルにしたがって必ず削除してください。

「ナレッジベースを作成」をクリック。
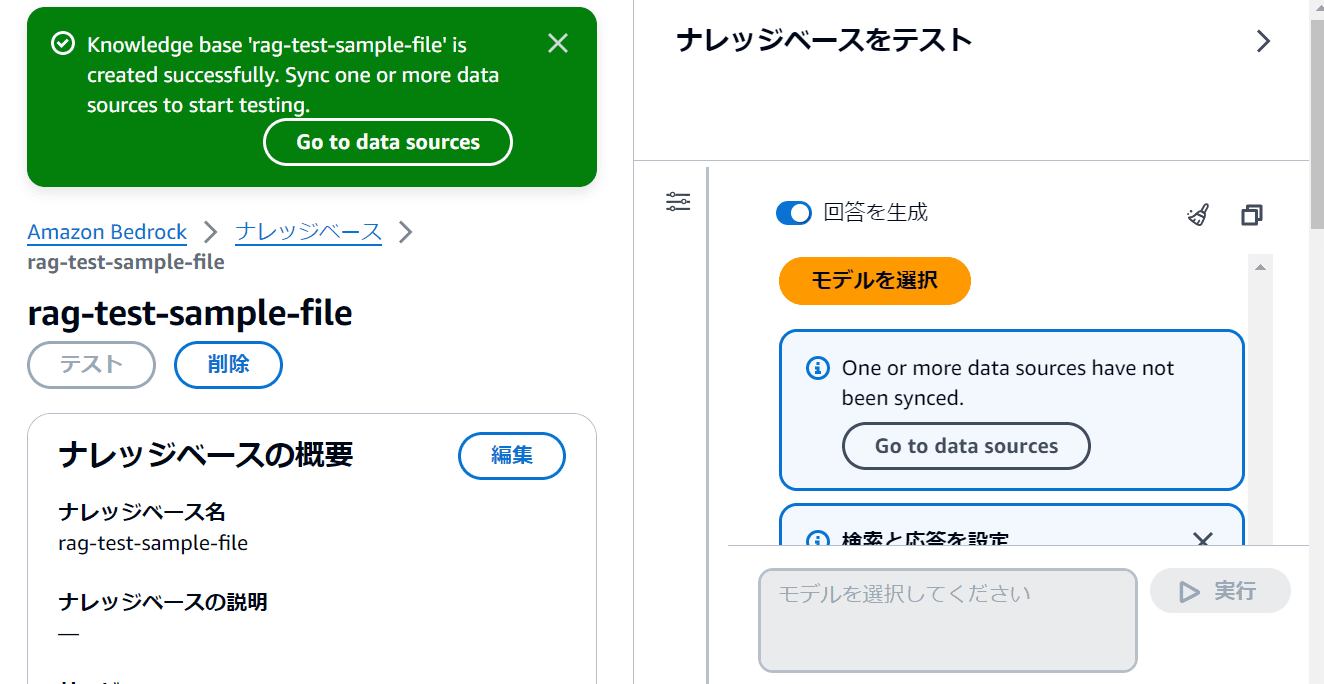
ナレッジベースの作成に数分程度かかります。成功すると次のような表示になります。(PCのディスプレイ解像度などによって見え方が異なります)
RAGのテスト
先ほどの画面の中央をスクロールするとデータソースという部分があります。この部分のデータソース名にチェックを入れて「同期」をクリックします。同期にしばらく時間がかかります。
右側の「モデルの選択」をクリック。
「Claude 3 Sonnet」を選択し「適用」をクリック。
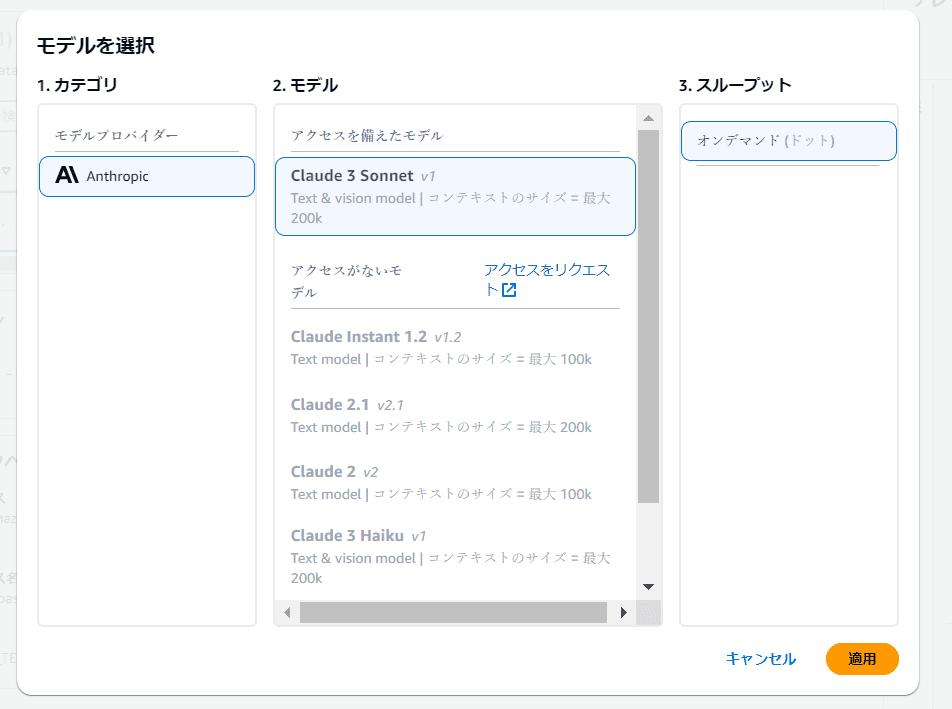
右側のプレースホルダーに質問を入力し「実行」をクリックすると回答が生成されます。なお、ここに記載されている「ナレッジベースID」は後ほど使用するのでメモしておきます。
では、前回と同じ質問をしてみましょう。
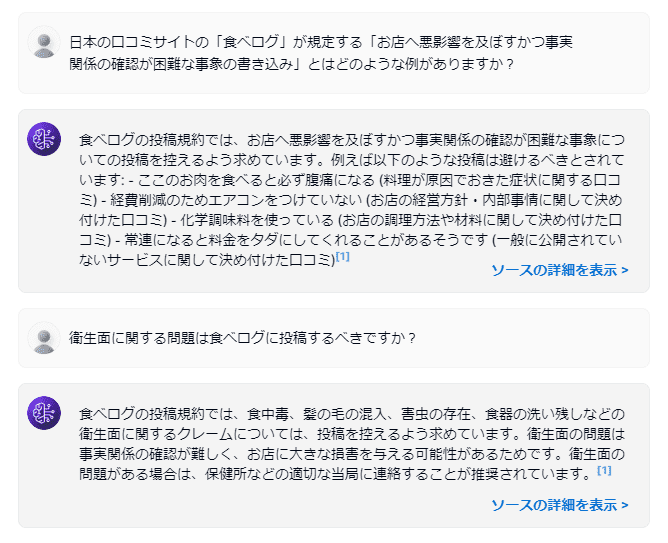
きちんと食べログガイドラインに記載された情報を回答してくれました。衛生面に関する質問もしてみましたが、こちらも文書中の例を引っ張ってきてくれています。
無事にRAGの構築に成功しました。
つづく
今回はClaude3のRAG構築までできました。
次回は、このRAGのAPIを作ってCurlやPythonで呼び出せるようにしてみましょう。
