やること
ウマ娘の声をフーリエ変換して比較する、の最終回です。前回はFFT画像の準備をしました。

いよいよ音声の定量比較です。ポジティブコントロールとネガティブコントロールも用意しているので実験設計の参考にもなるかと思います。
参考文献
FFT画像の類似度の計算にはこちらのサイトを使用しました。

上記のサイトでは、類似度の計算に「二乗誤差」を使用していると書かれています。画像のMSE(Mean Squared Error: 平均二乗誤差)についてはこちらが参考になります。(※サイト内で最小二乗誤差と表記されていますが正しくは平均二乗誤差です)

類似度の算出(1)
ライス①、ライス②、テイオー、マックイーンのスペクトログラムを各組み合わせで比較しました。全部で6通りです。
ライス① vs ライス②
これがポジティブコントロールです。ほぼ100%になっています。

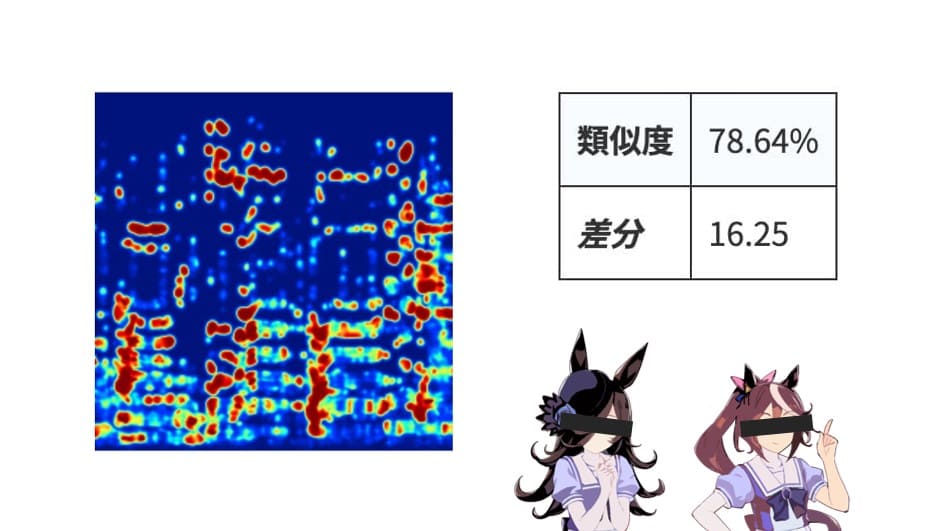
ライス① vs テイオー
いよいよ気になる結果です。類似度は78.64%

他の組み合わせも実行しました。結果がこちらです。
| ライス① | ライス② | テイオー | マックイーン | |
| ライス① | (100%) | 99.31% | 78.64% | 75.80% |
| ライス② | – | (100%) | 78.61% | 75.92% |
| テイオー | – | – | (100%) | 73.90% |
| マックイーン | – | – | – | (100%) |
ポジコンは99%でした。同じ声優が同じフレーズを歌っているから当然ですね。
違うウマ娘同士の類似度は73~79%でした。ちょっと範囲が狭い気がします(?)
類似度の算出(2)
ネガティブコントロールとしてblank画像も用意しているので、それぞれblank画像との類似度も算出してみます。
ライス① vs blank画像
テイオー vs blank画像
先程のテーブルにblank列を追加しました。
| ライス① | ライス② | テイオー | マックイーン | blank | |
| ライス① | (100%) | 99.31% | 78.64% | 75.80% | 69.64% |
| ライス② | – | (100%) | 78.61% | 75.92% | 69.61% |
| テイオー | – | – | (100%) | 73.90% | 68.37% |
| マックイーン | – | – | – | (100%) | 65.41% |
| blank | – | – | – | – | (100%) |
blank画像との類似度は低くなることを想定していて、ネガコンのつもりで加えています。それでも65~70%の類似度が出てしまうのですね。
類似度の算出(3)
違うウマ娘同士の類似度が73~79%でした。差を分かりやすくするために、ネガコンの値を考慮して65~100%の範囲を引き伸ばして新たに0~100点にするという規格化を行ってみます。
変換式はこちらです。(S:類似度、score:新たに算出する類似スコア)

結果がこちらです。
| ライス① | ライス② | テイオー | マックイーン | |
| ライス① | – | 98点 | 39点 | 31点 |
| ライス② | – | – | 39点 | 31点 |
| テイオー | – | – | – | 25点 |
| マックイーン | – | – | – | – |
先程よりは差が大きく見えるようになりました。ライスシャワーとトウカイテイオーの歌声は比較的似ていることが分かります。トウカイテイオーとメジロマックイーンの歌声は比較的遠いことが分かります。
このような定量比較が何に役立つかと言うと、例えば新しいウマ娘の声優を選ぶときに、既存のウマ娘との類似度を比較し、できるだけ遠い声優を起用するといったことができると思います。多様なキャラクターを揃えることでさらに魅力的なグループになると思います!
考察
まず、違うウマ娘同士の類似度が73~79%と「高く」「狭かった」ことについて。FFT画像はスパースで情報が少ないです(ほとんどのピクセルが0で情報密度が低い)。なのでほとんどのピクセルが一致していることになり、差が出にくかったのです。
これの改善策は情報密度を向上させることです。前回、高周波領域を破棄したのを覚えていますか?あれも情報密度を大きくする工夫でした。しかしまだまだ足りません。例えば、BGMの周波数領域もカットするとか、シグナル(白い線)を太くして情報量を増やすとか、そんなアイデアが考えられます。注意点として、倍音を削除するのは良くないですね。それは音質を失うことになります。
ポジコンが100%ではなく99%になったことについて。これは手作業によるトリミングの誤差だと思います。
最後に真のネガティブコントロールについて。ネガコンが黒画像で良いのかという議論はありそうです。情報がスパースなので、ネガコンとして真っ白な画像を使えばもっと低い類似度が出たかもしれません。しかし真っ白な画像に意味があるとは思えないので、やはり真っ黒な画像でいいのではないかと思っています。
おわりに
前編、中編、後編の3回に渡って音声スペクトログラムの定量比較を行いました ( ˘ω˘ ; )
今後は、一連の流れを自動化して長尺の動画の処理ができるようにしたいです。長い動画から特定のフレーズを自動抽出するとか、好きな声優の登場シーンだけを集めるようなことに使えると思います。
応援はリツイートなどを実行する形でお願いします!また、Qiitaとnoteもやっていますのでフォローお願いします!
Qiita

note
