
概要
TF-IDFは文書内の各単語の重要度を表す指標で、文書の特徴を掴む手助けになります。自然言語処理や機械学習の前処理として使われることがあります。
ざっくりというと、TF-IDFは文字の通りTFとIDFを掛け合わせたものです。
例
大仏で有名な寺である東大寺と高徳院のレビューを用意しました。東大寺と高徳院はそれぞれどのような特徴をもったお寺でしょうか?
東大寺のレビュー
私が見た一番大きな大仏様は鎌倉大仏だったので想像以上の大きさに驚きと屋内にあることが更に驚きでした。しかし、やたらに鹿が多くて、鹿のふんが参道に散乱してます。
高徳院のレビュー
早朝はリスを見ることが多くてあとから調べると台湾リスが繁殖して住み着いていると知りました。私はただの観光客なので『リス=カワイイ』ですが…。さて、大仏とご対面して奈良の大仏と比較してしまう感がありますが、立派な大仏に満足です。
もちろんどちらも大仏が特徴なのですが、本当に”大仏”という単語がそれぞれのレビューの特徴と言えるでしょうか?
まずこの二つの文章で形態素解析を行うと、
東大寺の形態素解析
[私, 見る, 一番, 大仏, 様, 鎌倉, 大仏, 想像, 以上, 大きい, さ, 驚き, 屋内, ある, こと, 驚き, 鹿, 多い, 鹿, ふん, 参道, 散乱, する](全23単語)
高徳院の形態素解析
[早朝, リス, 見る, こと, 多い, あと, 調べる, 台湾, リス, 繁殖, する, 住み着く, いる, 知る, 私, ただ, 観光, 客, リス, カワイイ, 大仏, 対面, する, 奈良, 大仏, 比較, する, しまう, 感, ある, 立派, 大仏, 満足](全33単語)
となります。
TFの計算
まずはTFを計算してみます。
TF(Term Frequency)はある単語の出現頻度のことで、TFが大きいほど出現頻度が高く重要な単語とみなされます。式で表すと以下の通り。

東大寺と高徳院の”大仏”、”鹿”、”リス”のTFを計算すると、
東大寺

高徳院

この結果から、東大寺では”大仏”と”鹿”、高徳院では”大仏”と”リス”が重要であることがわかります。
IDFの計算
IDF(Inverse Document Frequency)は逆文書頻度とも呼ばれ、特定の文書にしか登場しないレア単語ほどIDF値が高くなります。式で表すと以下の通り。

IDFは全文書を通して計算されます。2つのレビューをひとまとめにして”大仏”、”鹿”、”リス”のIDFを計算してみると、

どちらのレビューにも含まれている”大仏”は、東大寺にしかない”鹿”や高徳院にしかない”リス”よりもIDF値が低くなり、それほど重要な単語ではないことになります。
TF-IDF
冒頭にも書いたとおり、TF-IDFはTFとIDFを掛け合わせたものです。これを計算することにより、ある文書の特徴となる単語(ある文書内の代表的な単語)を割り出すことができます。式で表すと以下の通り。
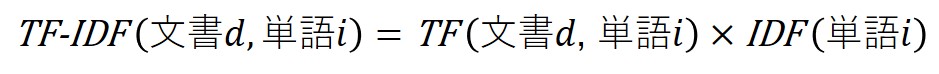
東大寺と高徳院の”大仏”、”鹿”、”リス”のTF-IDFを計算します。両レビューのIDFは共通していることに注意してください。
東大寺

高徳院

比較しやすいように表にまとめました。
| 東大寺 | 高徳院 | |
| 大仏 | 0.087 | 0.091 |
| 鹿 | 0.1131 | 0 |
| リス | 0 | 0.1183 |
この結果から、東大寺と高徳院を比較すると、
- 東大寺は”鹿”
- 高徳院は”リス”
が特徴的な寺だということが分かります。どちらのお寺も”大仏”が有名ではありますが、この2つの文書の比較においては、”鹿”と”リス”の方が特徴的だということです。
同じ文書であっても、周りにどんな文書があるかによって特徴的な単語は違ってくるのですね。
なお今回は3つの単語に着目してTF-IDFを比較しましたが、他の単語も同様に計算でき、より特徴的な単語が存在する可能性があります。
参考文献
テキストをjanomeで形態素解析をする【自然言語処理の基礎】

【初学者向け】TFIDFについて簡単にまとめてみた
自然言語処理の基礎技術!tf-idfを簡単に解説


