
やること
教師あり学習にはたくさんの教師データが必要です。今日は、「画像のクラス分類問題」の準備として、さまざまな検索ワードでGoogle画像検索を行い、結果をスクレイピングしてみます。
環境とコード
WinPython3.6をおすすめしています。


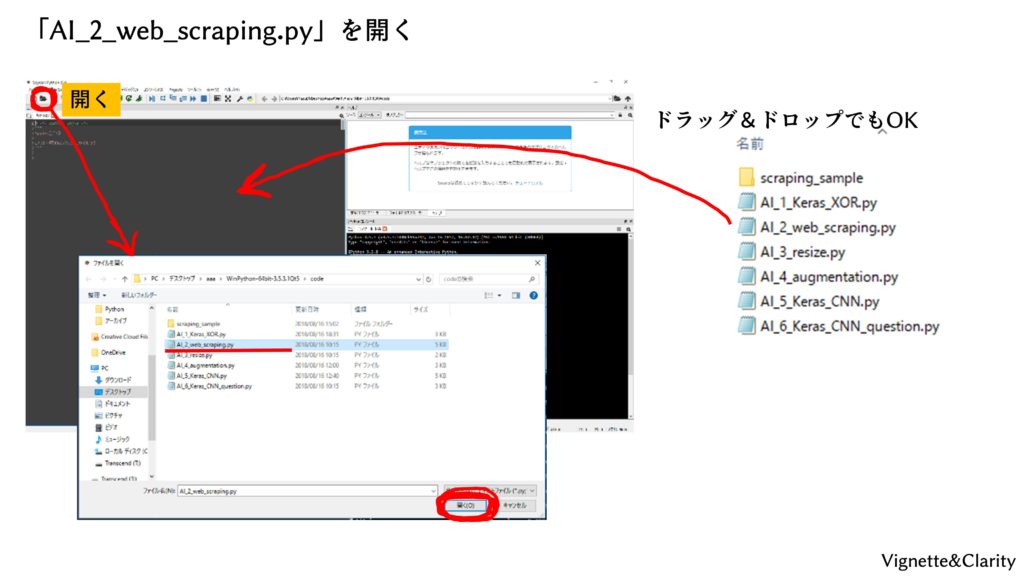
プログラムの実行
実行方法は覚えていますでしょうか。
配布されたプログラムの冒頭で、検索ワードを自由に書き換えられるようになっています。できるだけキレイな画像を集めるために、「レシピ ショートケーキ」のように検索ワードを工夫すると良いです。

結果
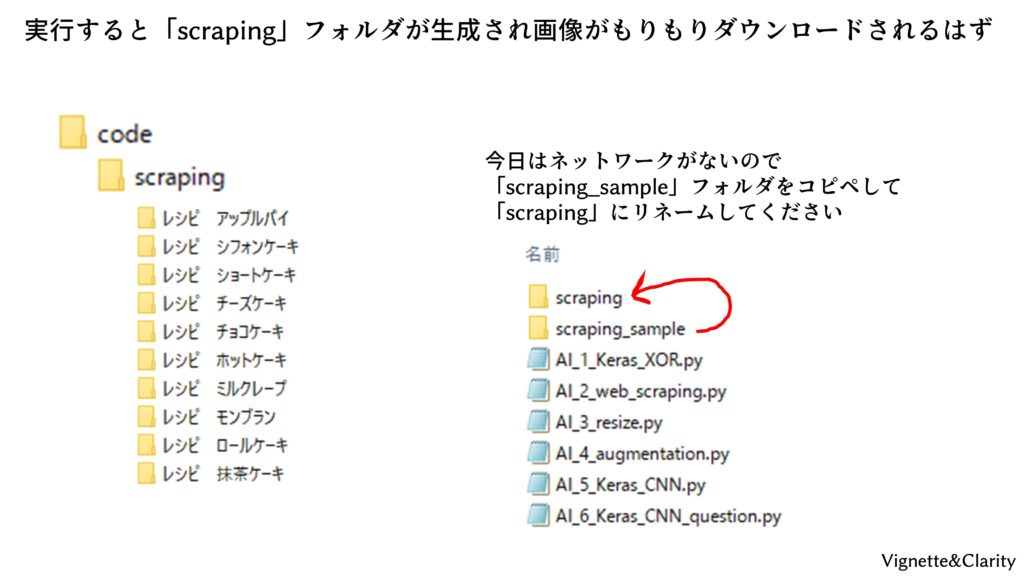
実行すると、自動的に「scraping」という親フォルダが生成され、その中に、各検索ワードの子フォルダが生成されます。小フォルダの中には最大100枚(※2018年12月に改良され最大200枚)の画像が保存されます。
不適切な画像を手動で削除する
子フォルダをひとつひとつ開き、学習にとって不適切な画像を削除します。ここで重要なテクニックですが、もっとも画像が少ないクラスの枚数に、他のクラスの枚数を合わせます。今回は「抹茶ケーキ」が40枚まで減ってしまったため、他のクラスも40枚に統一しました。

余談
なぜすべてのクラスの画像の枚数を統一する必要があるのでしょうか?こちらのニュースをご覧ください。

ところが15年までに、アマゾンはソフトウエア開発など技術関係の職種において、システムに性別の中立性が働かない事実を見つけ出してしまった。これはコンピューターモデルに10年間にわたって提出された履歴書のパターンを学習させたためだ。つまり技術職のほとんどが男性からの応募だったことで、システムは男性を採用するのが好ましいと認識したのだ。
例えば教師データに用いた履歴書の男女比が8:2で、男女ともに採用率50%だったとします(=男女に能力差はない)。偏った教師データで学習をすると、採用するか判断に迷った場合に、とりあえず男性を採用しておけば8割の確率で正解するわけですから、機械は男性に有利な判断をするのですね。ですから、教師データは各クラスとも同じ枚数を用意するか、同じ枚数になるように水増ししなければなりません。