
やること
聞き間違えを防ぐ時に使う「アルファのA」「ブラボーのB」のような表現をフォネティックコード(英語の場合は欧文通話表とも)と呼び、国際的な取り決めがあります。先日うっかり「DドライブのDです」と言ったら「Dはデルタですよ」と正されたうえ、よく考えたらBドライブと聞き間違えやすいので全然ダメでした。
日本語版のフォネティックコードは和文通話表と呼び、こちらもあらかじめ定義されています。尾張(をはり)なんですね。
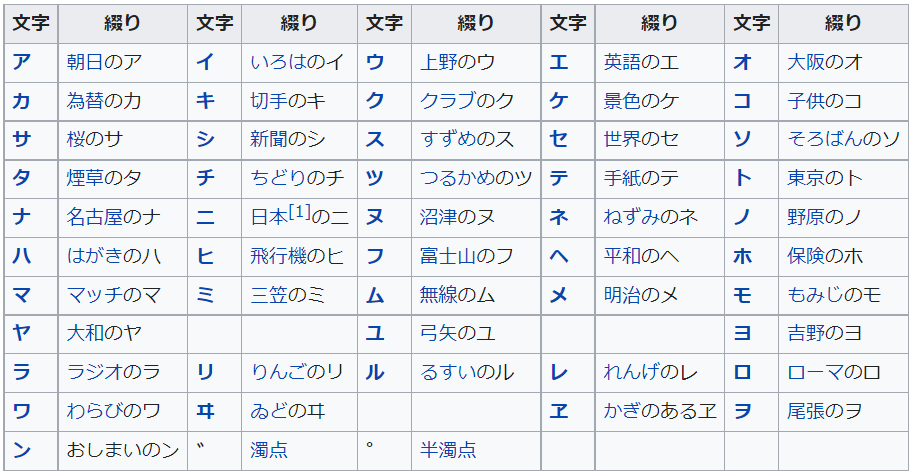
しかし、これらは適切と言えるでしょうか?例えば「朝日のア」「はがきのハ」「わらびのワ」はいずれも母音がaaiのため聞き間違いが生じる可能性があります。「世界のセ」「手紙のテ」など他にもいくつかあります。
通話表の役割を考えれば、例示される単語の母音に重複がないことが理想と言えるでしょう。ここではポケモンを使って理想的な和文通話表を定義してみます。
参考
フォネティックコード

ポケモン一覧

過去の記事を使ってあらかじめポケモン名をスクレイピングしておきました。ファイルを置いておきます。

条件
例示にポケモン名を用いますが、ヲ、ンから始まるポケモンはいないので除外します。濁点、数字、記号は現状の通話表で問題ないので除外します。よってア~ワまでの44文字を考えることになります。
ここで、頭から何文字目までの母音重複を避ければよいか考えます。1文字では5通り、2文字で25通り、3文字で125通りなので頭から3文字の母音が重複しないように設計すべきです。「エビワラーのエ」「サワムラーのサ」であれば頭3文字がeiaとaauなので重複しておらず、「ラー」は一緒でも問題ありません。
小さな「ッ」はどの母音にも該当しないと考え、第6の母音として扱うことにします。
準備1
ポケモン名リストを読み込みます。問題を少し難しくするために第3世代までのポケモンに限定します(386匹)。ただしセレビィだけ特例でセレビイに変更させてください。
import numpy as np
import pandas as pd
#============================
#ポケモン名の読み込み
#============================
data = pd.read_csv('pokemon_namelist.csv', encoding='utf-8', header=None)
names = np.array(data[1])[:386] #第3世代までに限定
names[251] = 'セレビイ' #ごめんなさいセレビィだけ特例
print(names[-3:])
print(len(names))['レックウザ' 'ジラーチ' 'デオキシス']
386使えそうなポケモンを選別します。
- 3文字に満たないものは除外
- 1文字目が濁音、半濁音であれば除外
- 3文字目までに長音(ー)や点(・)があるものは除外
- 4文字目までに小さい字(ャュョ等)があるものは除外
#============================
#データの選別
#============================
#削除対象リスト
set_daku = list('ガギグゲゴザジズゼゾダヂヅデドバビブベボパピプペポヴ')
set_skip = list('ー・')
set_small = list('ァィゥェォャュョ')
#ポケモンの削除
for i in range(len(names)-1, -1, -1):
#3文字に満たなければ削除
if len(names[i]) < 3:
names = np.delete(names, i)
continue
#1文字が濁音・半濁音があれば削除
if names[i][0] in set_daku:
names = np.delete(names, i)
continue
#3文字目までに長音や点があれば削除
if names[i][0] in set_skip or names[i][1] in set_skip or names[i][2] in set_skip:
names = np.delete(names, i)
continue
#4文字目までに小さい字があれば削除
if names[i][0] in set_small or names[i][1] in set_small or names[i][2] in set_small or (len(names[i]) >= 4 and names[i][3] in set_small):
names = np.delete(names, i)
continue
#print(names)
print(len(names))219219匹まで減りました。
準備2
各文字から始まるポケモンをグループ化します。
#============================
#ポケモンのグループ分け
#============================
#アイウエオ
set_aiu = list('アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワ') #ヲンは除く
#空のグループ作成
group = {}
for a in set_aiu:
group[a] = []
#ポケモンのグループ分け {頭文字:[ポケモン, ポケモン,...]}
for name in names:
group[name[0]].append(name)
print(group){'ア': ['アズマオウ', 'アリゲイツ', 'アリアドス', 'アンノーン', 'アゲハント', 'アメタマ', 'アメモース', 'アサナン', 'アノプス', 'アブソル'], 'イ': ['イシツブテ', 'イトマル', 'イノムー', 'イルミーゼ'], (中略) , 'ワ': ['ワンリキー', 'ワニノコ', 'ワタッコ']}第3世代まではマが最多で15匹いるようです。
ある文字を頭文字にもつポケモンが1匹もいない場合、あるいは1匹しかいない場合を確認します。
#============================
#予備解析
#============================
#0匹のグループ
for a in set_aiu:
if len(group[a]) == 0:
print(a)
#1匹のグループ
for a in set_aiu:
if len(group[a]) == 1:
print(a, group[a])シ ['シザリガー']
セ ['セレビイ']
ソ ['ソルロック']
ネ ['ネンドール']
ム ['ムウマ']
モ ['モココ']
リ ['リングマ']担当ポケモンがいない文字はなく、1匹だけの文字がいくつかありました。(君に決めた)
母音抽出
頭から3文字の母音を「アイウ」のように抽出します。
#============================
#母音抽出
#============================
#変換リスト
set_daku_after = list('アイウエオアイウエオアイウエオアイウエオアイウエオウ') #set_dakuに対応
set_aiu_after = list('アイウエオアイウエオアイウエオアイウエオアイウエオアイウエオアイウエオアウオアイウエオア') #set_aiuに対応
#グループを拡張して3母音も保存 {頭文字:[[ポケモン, 3母音], [ポケモン, 3母音],...]}
for a in set_aiu:
for i in range(len(group[a])):
boin = group[a][i]
#濁点を外す
for j in range(len(set_daku)):
boin = boin.replace(set_daku[j], set_daku_after[j])
#母音に変換
for j in range(len(set_aiu)):
boin = boin.replace(set_aiu[j], set_aiu_after[j])
#3文字に限定
boin = boin[:3]
#拡張保存
group[a][i] = [group[a][i], boin]
print(group){'ア': [['アズマオウ', 'アウア'], ['アリゲイツ', 'アイエ'], (略)採択と調整
いよいよメインの処理です。一応、組合せ最適化になるのですが、ここでは貪欲法で「採択リストになければ採択、どうしても採択できなければ先客を追い出す形で融通してもらう」という方針でいきます。珍しくpandasデータフレームや set() を使っています。
#============================
#母音採択と調整
#============================
#採択リスト
save = pd.DataFrame(columns=['HEAD', 'NAME'])
while 1:
#未達成の頭文字リスト
remains = list(set(set_aiu) - set(list(save['HEAD'])))
#終了判定
if len(remains) == 0:
print('END')
break
#未達成の頭文字を一つ指定
a = remains[0]
#頭文字のポケモンを順番に調べる
for name, boin in group[a]:
#採択リストになければ追加
if boin not in list(save.index):
print('add {} {} {}'.format(boin, a, name))
save.loc[boin] = [a, name]
break
else:
name, boin = group[a][0]
print('- remove {} {} {}'.format(boin, save['HEAD'][boin], save['NAME'][boin]))
save.drop(boin, axis=0) #採択できなければ採択リストから無理やり除外
print('- add {} {} {}'.format(boin, a, name))
save.loc[boin] = [a, name] #新規採択
#終了判定
if len(save) == len(set_aiu):
print('END')
breakadd ウイン ウ ウインディ
add オオン ロ ロコン
add アンオ サ サンド
(中略)
add アイイ カ カイリキー
add ウウア ム ムウマ
add エッオ テ テッポウオ
- remove オウオ ホ ホウオウ
- add オウオ ソ ソルロック
add オエウ ホ ホエルコ
add ウンア ル ルンパッパ
add アアウ マ マダツボミ
(中略)
add インウ リ リングマ
add イエイ キ キレイハナ
add アオオ ナ ナゾノクサ
ENDポケモン数が多かったので1回しか融通が起きませんでした。ソのポケモンからどれかを採択しようとしたところ、どの母音もすでに採択されていました。そこで採択済みのオウオ(ホウオウ由来)を追い出してオウオ(ソルロック由来)を追加しました。その後、ホについてはオエウ(ホエルコ由来)を採択しています。
最後にアイウエオ順にソートして表示、また、母音に重複がないかチェックしました。
#============================
#仕上げ
#============================
#アイウエオ順にソート
save = save.sort_values('HEAD')
print(save)
#重複チェック
print(len(list(save.index)) == len(set(list(save.index)))) HEAD NAME
アウア ア アズマオウ
イイウ イ イシツブテ
ウイン ウ ウインディ
エイア エ エビワラー
オイウ オ オニスズメ
アイイ カ カイリキー
イエイ キ キレイハナ
ウアイ ク クサイハナ
エンア ケ ケンタロス
オアッ コ コラッタ
アンオ サ サンド
イアイ シ シザリガー
ウイア ス スピアー
エエイ セ セレビイ
オウオ ソ ソルロック
アアア タ タマタマ
イオイ チ チコリータ
ウオウ ツ ツボツボ
エッオ テ テッポウオ
オアン ト トランセル
アオオ ナ ナゾノクサ
イオウ ニ ニドクイン
ウアウ ヌ ヌマクロー
エンオ ネ ネンドール
オオッ ノ ノコッチ
アエッ ハ ハネッコ
イオア ヒ ヒトカゲ
ウイイ フ フシギダネ
エアウ ヘ ヘラクロス
オエウ ホ ホエルコ
アアウ マ マダツボミ
イウア ミ ミルタンク
ウウア ム ムウマ
エオウ メ メノクラゲ
オオオ モ モココ
アオン ヤ ヤドン
ウンエ ユ ユンゲラー
オアア ヨ ヨマワル
アッア ラ ラッタ
インウ リ リングマ
ウンア ル ルンパッパ
エアオ レ レアコイル
オオン ロ ロコン
アンイ ワ ワンリキー
Trueご査収ください。これからは「アズマオウのア」「イシツブテのイ」と表現すると良いでしょう。頭から3文字の母音の重複がないので聞き取り間違いが起きにくいです。