
はじめに
シンプルなWebページのスクレイピングを試してみましょう。
対象のWebページ
ポケモンWikiの「ポケモン一覧」ページから全ポケモン名を取得してみます。

実行環境
WinPython3.6をおすすめしています。

Google Colaboratoryが利用可能です。

HTMLソースの取得
必要なパッケージをインストールします。
pip install requests
pip install beautifulsoup4URLを指定してHTMLソースを取得します。なお、URLに日本語が含まれる場合、コピペすると自動で「URLエンコード」されて「%E3%83%9D・・・」という文字列になるかと思います。そうでない場合、あるいはプログラム中で日本語からURLを生成するような場合には手動でURLエンコードする必要がありますのでご留意ください。
import requests
from bs4 import BeautifulSoup
#URL
url = 'https://wiki.xn--rckteqa2e.com/wiki/%E3%83%9D%E3%82%B1%E3%83%A2%E3%83%B3%E4%B8%80%E8%A6%A7'
#HTML内容を文字列として取得
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser')
html = str(soup)
print('--------- HTML内容 ---------')
print(html[:500])
print('----------------------------')--------- HTML内容 ---------
<!DOCTYPE html>
<html class="client-nojs" dir="ltr" lang="ja">
<head>
<meta charset="utf-8"/>
<title>ポケモン一覧 - ポケモンWiki</title>
<script>document.documentElement.className = document.documentElement.className.replace( /(^|\s)client-nojs(\s|$)/, "$1client-js$2" );</script>
<script>(window.RLQ=window.RLQ||[]).push(function(){mw.config.set({"wgCanonicalNamespace":"","wgCanonicalSpecialPageName":false,"wgNamespaceNumber":0,"wgPageName":"ポケモン一覧","wgTitle":"ポケモン一覧","wgCurRevisionId":518284,"wgRevisionI
----------------------------HTMLの冒頭の500文字を表示しました。注意点として、コンソールで改行されている場所には改行コード「/n」が隠れています。
どうやってポケモン名を取得するか
ページを見ると、図鑑番号のそばにポケモン名があります。
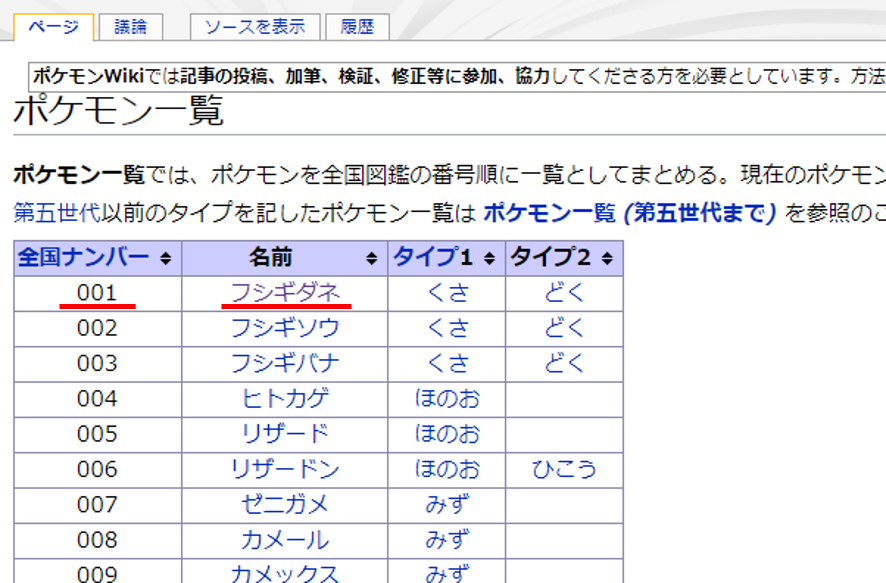
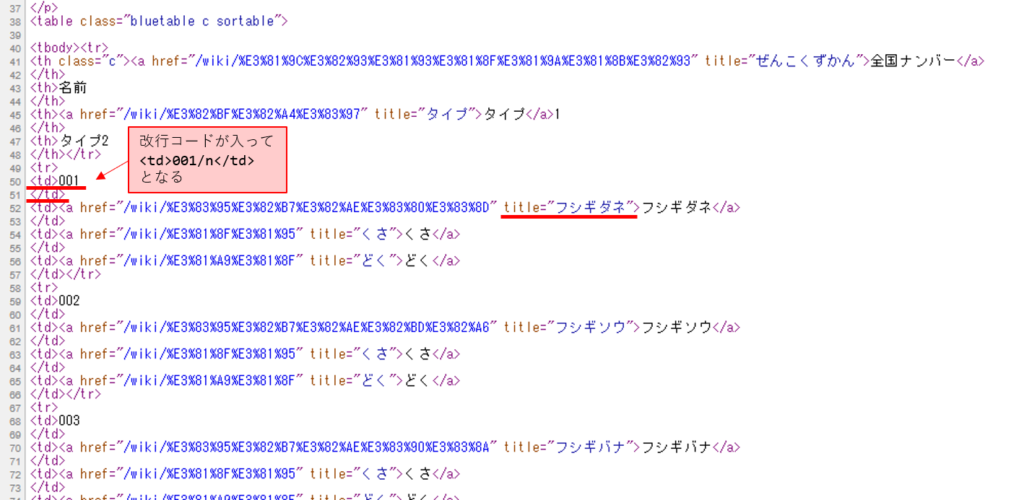
HTMLソースを見ると、<td>001/n</td> という文字列が図鑑番号で、title=” の後にポケモン名が来るという法則が分かります。
ポケモン名の取得
長いHTMLソースから特定の文字列を見つける関数を作りました。
#長い文字列から特定の文字列を探して開始インデックスを返す
#検索開始位置とそこからの検索範囲を指定できる
def find_index(html, text, start, length=9999999):
for i in range(length):
if html[start+i:start+i+len(text)] == text:
return i
return -1 #見つからなければ-1を返す
#図鑑番号(ゼロ埋めして3桁に)
num = str(1).zfill(3)
print(num)
#図鑑番号の位置
text = '<td>' + num + '\n</td>'
index = find_index(html, text, 0)
print(index)
print('--------- HTML内容 ---------')
print(html[index:index+150])
print('----------------------------')001
6447
--------- HTML内容 ---------
<td>001
</td>
<td><a href="/wiki/%E3%83%95%E3%82%B7%E3%82%AE%E3%83%80%E3%83%8D" title="フシギダネ">フシギダネ</a>
</td>
<td><a href="/wiki/%E3%81%8F%E3%81%95" t
----------------------------<td>001/n</td> を探すと6447文字目から始まることが分かりました。その場所から150文字を表示してみると、たしかにこの付近で間違いなさそうです。
最後に、その場所から初めて登場する title=” と “> の場所を見つけ、間に挟まれたポケモン名を取得します。
#ポケモン名を検出
start = find_index(html, 'title="', index) + len('title="')
end = find_index(html, '">', index)
print(start, end)
name = html[index+start:index+end]
print(name)87 92
フシギダネ87文字目から91文字目までの「フシギダネ」が取得できました。
まとめ
ちなみに図鑑番号が001だからといって「001」だけで探そうとすると、長いHTMLソースの中にたまたまあった無関係な001がヒットしてしまうことがあるので、欲しい部分に特有の表現を指定することが大切です。そのためにわざわざ <td>001/n</td> を指定しました。
このような感じでfor文を回せば全ポケモン名を取得できますし、同様に各ポケモンのリンクURLも取得できますので、子ページの内容を取ってくることも可能です。

