
やること
DCGANのプログラムはやや複雑ですが、勉強会で配布されたものをそのまま使えばだれでもできます。今日は、DCGANでお寿司の画像を学習してみます。
使うもの
Google Colaboratoryが利用可能です。

WinPython3.6をおすすめしています。

こちらの勉強会を参考にしています。


画像のサイズ(解像度)を揃える
お寿司の画像を「osushi」フォルダに集めて、プログラムを用いて128*128サイズに揃えて、「osushi_resize」フォルダに保存します。
# -*- coding: utf-8 -*-
import os
from PIL import Image
import numpy as np
#パラメータ
#======================================
#画像を保存してあるフォルダ名
f = 'osushi/'
#リサイズした画像を保存するフォルダ名
f_resize = 'osushi_resize/'
#リサイズ後のサイズ
size = 128
#======================================
#処理
#======================================
if not os.path.isdir(f_resize):
os.makedirs(f_resize)
files = os.listdir(f)
for file in files:
img = Image.open(f + file).convert("RGBA"); img.close
tmp = np.array(img)
mask = tmp[:,:,3] < 240
tmp[mask, 0] = 255
tmp[mask, 1] = 255
tmp[mask, 2] = 255
img = Image.fromarray(tmp[:,:,0:3])
width, height = img.size
if width == height:
tmp = img
elif width > height:
tmp = Image.new('RGB', (width, width), (255, 255, 255))
tmp.paste(img, (0, (width - height) // 2))
else:
tmp = Image.new('RGB', (height, height), (255, 255, 255))
tmp.paste(img, ((height - width) // 2, 0))
img_resize = tmp.resize((size, size), Image.BICUBIC)
img_resize.save(f_resize + file)
print("リサイズ完了")
print()
#======================================リサイズ後のお寿司画像(.zip)をこちらに置いておきます。展開して用いてください。
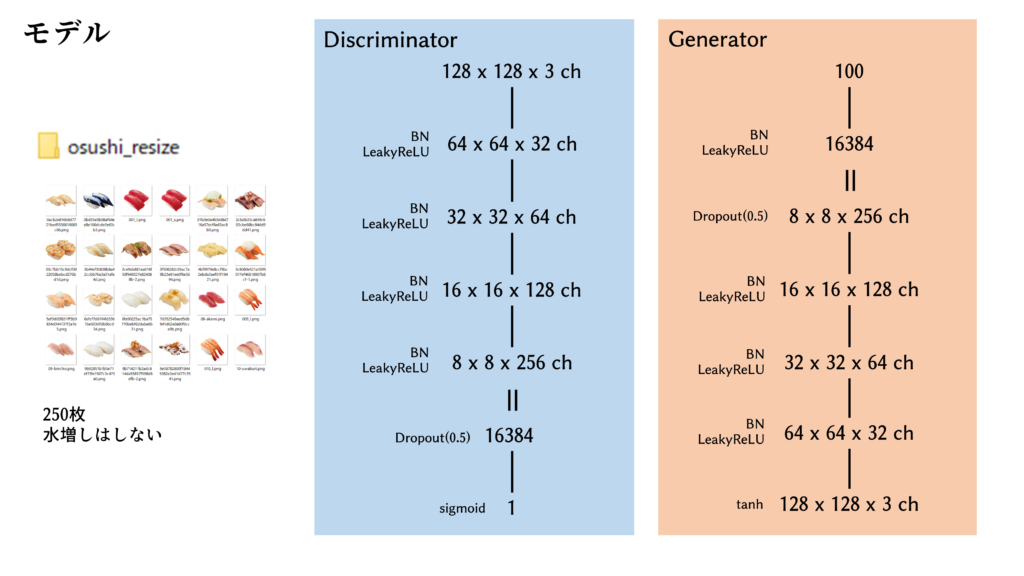
ジェネレータとディスクリミネータのモデル
さまざまな論文やテクニック集を参考に、珠玉のモデルを組みました。潜在変数は100次元に設定しました。
プログラムを実行する
DCGANのほぼ最小コードではないかと思います。自動的に「DCGAN_img」フォルダが生成され、10エポック毎にジェネレータが作成した画像が保存されます。また、「DCGAN_para」フォルダも生成され、100エポック毎にジェネレータの重みが保存されます。ハイパーパラメータの調整は非常に難しいのですが、128px*128pxくらいの画像であれば、この設定で学習が進みます。
2020/11/07追記
現在、こちらのコードではうまく学習ができないことが確認されています。原因としてはKeras, Tensorflowのバージョンしか思い当たりませんが、それぞれ下げてみてもうまく行っていません。うまく行った方がいましたら情報共有をお願い申し上げます。
import os
import time
import numpy as np
import numpy.random as nr
from PIL import Image
import matplotlib.pyplot as plt
import keras
from keras.models import Sequential
from keras.layers import Dense, Conv2D, BatchNormalization, Conv2DTranspose, Activation, Flatten, Dropout, Reshape, GlobalAveragePooling2D
from keras.layers.advanced_activations import LeakyReLU
#パラメータ
#======================================
#教師画像のフォルダ
f = 'osushi_resize/'
#ミニバッチサイズ(教師データ数の公約数にしてください)
batch_size = 50
#乱数列の次元
z_dim = 100
#unroll数(DをGよりも何回先行させるか)
unroll = 0
#discriminatorの学習率
opt_D = keras.optimizers.Adam(lr=0.0002)
#generatorの学習率
opt_G = keras.optimizers.Adam(lr=0.0004)
#画像を保存するフォルダ
img_f = 'DCGAN_img/'
#重みを保存するフォルダ
para_f = 'DCGAN_para/'
#======================================
#教師データ読み込み
#======================================
x_train = []
files = os.listdir(f)
for file in files:
img = Image.open(f + file).convert("RGB"); img.close
x_train.append(np.array(img))
x_train = np.array(x_train)
#-1~+1に規格化
x_train = (x_train - 127.5) / 127.5
print('枚数, たて, よこ, チャンネル')
print(x_train.shape)
#======================================
#モデルの定義
#======================================
def generator_model():
model = Sequential()
#100次元 → 8*8*256=16384次元に展開
model.add(Dense(8 * 8 * 256, input_shape = (z_dim, )))
model.add(BatchNormalization())
model.add(LeakyReLU())
#8*8*256chに変形
model.add(Reshape((8, 8, 256)))
model.add(Dropout(0.5))
#8*8*256ch → 16*16*128chにアップ
model.add(Conv2DTranspose(128, (4, 4), strides=(2, 2), padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
#16*16*128ch → 32*32*64chにアップ
model.add(Conv2DTranspose(64, (4, 4), strides=(2, 2), padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
#32*32*64ch → 64*64*32chにアップ
model.add(Conv2DTranspose(32, (4, 4), strides=(2, 2), padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
#64*64*32ch → 128*128*3chにアップ
model.add(Conv2DTranspose(3, (4, 4), strides=(2, 2), padding='same'))
model.add(Activation('tanh'))
return model
def discriminator_model():
model = Sequential()
#128*128*3ch → 64*64*32chにたたむ
model.add(Conv2D(32, (4, 4), strides=(2, 2), padding='same', input_shape=(128, 128, 3)))
model.add(BatchNormalization())
model.add(LeakyReLU())
#64*64*32ch → 32*32*64chにたたむ
model.add(Conv2D(64, (4, 4), strides=(2, 2), padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
#32*32*64ch → 16*16*128chにたたむ
model.add(Conv2D(128, (4, 4), strides=(2, 2), padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
#16*16*128ch → 8*8*256chにたたむ
model.add(Conv2D(256, (4, 4), strides=(2, 2), padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
#フラットに伸ばして
model.add(Flatten())
model.add(Dropout(0.5))
#真偽判定
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
def combined_model(generator, discriminator):
model = Sequential()
model.add(generator)
model.add(discriminator)
return model
#======================================
#モデルの生成
#======================================
#generatorの生成
generator = generator_model()
#discriminatorの生成
discriminator = discriminator_model()
#combinedの作成
combined = combined_model(generator, discriminator)
#generatorの構造
generator.summary()
print('↑generatorは学習ON(combinedの中に組み込む)')
#discriminatorの学習をONにして(デフォルトでONだけど)discriminatorをコンパイル
discriminator.trainable = True
discriminator.compile(loss='binary_crossentropy', optimizer=opt_D)
#discriminatorの構造
discriminator.summary()
print('↑discriminator単体としては学習ON')
#discriminatorの学習をOFFにしてcombinedをコンパイル
discriminator.trainable = False
combined.compile(loss='binary_crossentropy', optimizer=opt_G)
#combinedの構造
combined.summary()
print('↑combinedの中は、generatorが学習ON、discriminatorが学習OFF')
#======================================
#保存用フォルダ作成
if not os.path.isdir(para_f):
os.makedirs(para_f)
if not os.path.isdir(img_f):
os.makedirs(img_f)
#確認用の固定乱数列
z_fix = np.clip(nr.randn(10*2, z_dim), -1, 1)
#0エポック目、固定乱数列で生成して確認
#======================================
print('Epoch 0/30000')
ans_g = generator.predict(z_fix, verbose=0)
imgs = []
for i in range(len(ans_g)):
img = Image.fromarray(np.uint8(ans_g[i] * 127.5 + 127.5))
imgs.append(img)
back = Image.new('RGB', (imgs[0].width * 10, imgs[0].height * 2))
for i in range(2):
for j in range(10):
back.paste(imgs[i*10 + j], (j * imgs[0].height, i * imgs[0].width))
plt.figure(figsize=(10, 10))
back.save(img_f + '0.png')
plt.imshow(back, vmin = 0, vmax = 255)
plt.show()
#======================================
#0エポック目、重みの保存
generator.save(para_f + 'generator_0.h5')
#DCGAN
#======================================
for epoch in range(0, 30000):
#一定epoch毎に画像表示
if epoch % 10 == 0:
#固定乱数列で生成して確認
#======================================
ans_g = generator.predict(z_fix, verbose=0)
imgs = []
for i in range(len(ans_g)):
img = Image.fromarray(np.uint8(ans_g[i] * 127.5 + 127.5))
imgs.append(img)
back = Image.new('RGB', (imgs[0].width * 10, imgs[0].height * 2))
for i in range(2):
for j in range(10):
back.paste(imgs[i*10 + j], (j * imgs[0].height, i * imgs[0].width))
plt.figure(figsize=(10, 10))
back.save(img_f + str(epoch) + '.png')
plt.imshow(back, vmin = 0, vmax = 255)
plt.show()
#======================================
#一定epoch毎に重みを保存
if epoch % 100 == 0:
#重みの保存
generator.save(para_f + 'generator_' + str(epoch) + '.h5')
#discriminator.save(para_f + 'discriminator_' + str(epoch) + '.h5')
#学習イテレーション(エポックの中で、バッチサイズずつ繰り返すやつ)
#======================================
itmax = x_train.shape[0] // batch_size
for i in range(itmax):
#discriminatorの学習
#まずは1回学習
#真画像を入力して1へ学習
x = x_train[i * batch_size : (i + 1) * batch_size]
y = nr.rand(batch_size) * 0.5 + 0.7
d_loss = discriminator.train_on_batch(x, y)
#偽画像を入力して0へ学習
z = np.clip(nr.randn(batch_size, z_dim), -1, 1)
x = generator.predict(z, verbose=0)
y = nr.rand(batch_size) * 0.5 - 0.2
d_loss = discriminator.train_on_batch(x, y)
#重みをキープしておく
config = discriminator.get_weights()
#unroll回学習
for k in range(unroll):
#真画像を入力して1へ学習
x = x_train[i * batch_size : (i + 1) * batch_size]
y = nr.rand(batch_size) * 0.5 + 0.7
d_loss = discriminator.train_on_batch(x, y)
#偽画像を入力して0へ学習
z = np.clip(nr.randn(batch_size, z_dim), -1, 1)
x = generator.predict(z, verbose=0)
y = nr.rand(batch_size) * 0.5 - 0.2
d_loss = discriminator.train_on_batch(x, y)
#generatorの学習(=combinedの学習)
#乱数列を入力して1へ学習
z = np.clip(nr.randn(batch_size, z_dim), -1, 1)
y = nr.rand(batch_size) * 0.5 + 0.7
g_loss = combined.train_on_batch(z, y)
#unroll発動、discriminatorの重みを1回目に戻す
discriminator.set_weights(config)
#======================================
#一定epoch毎にprint表示
if epoch % 10 == 0:
print('Epoch {}/30000 d_loss: {} g_loss: {}'.format(epoch, d_loss, g_loss), end='')結果
20個の潜在変数(=乱数列)でジェネレータの性能を確認しています。0エポックではジェネレータはグレーの画像しか出力しませんが、だんだんお寿司が出てきます。1200エポックまで学習してみました。
あまり長いこと学習しているとmode collapseという現象が起きることがあります。理想的なジェネレータはランダムな潜在変数から多様なお寿司を生成するものですが、「サーモン出しとくだけでディスクリミネータが本物って言ってくれるじゃん」と怠けがちです。お寿司の多様性が失われます。

mode collapse対策
実はmode collapse対策として、Unrolled GANという手法が実装されています。興味がある方はunroll=0の値を1以上にして試してみてください。だたしその分だけ学習には時間がかかります。




