
はじめに
今回はpix2pixで線画にした画像を着色してみます。pix2pixはImage-to-ImageなGANモデルで多様な使い方ができます。セグメンテーション画像から本物の画像を予測する、モノクロ画像をカラーにしたり、地図画像を本物の画像にするなどのタスクで使われます。
使うもの
Google Colaboratoryを使用します。

データの前処理
pix2pixでは画像のペアが必要になってきます。今回は線画から着色するので線画の画像とカラー画像の2種類を用意します。この際、変換前と変換後の画像は以下のように対応付けられるようにしなければなりません。この対応付がされていないとpix2pixではうまく訓練がすすみません。カラー画像の線画化は以下のサイトを参考にしました。


コードの説明
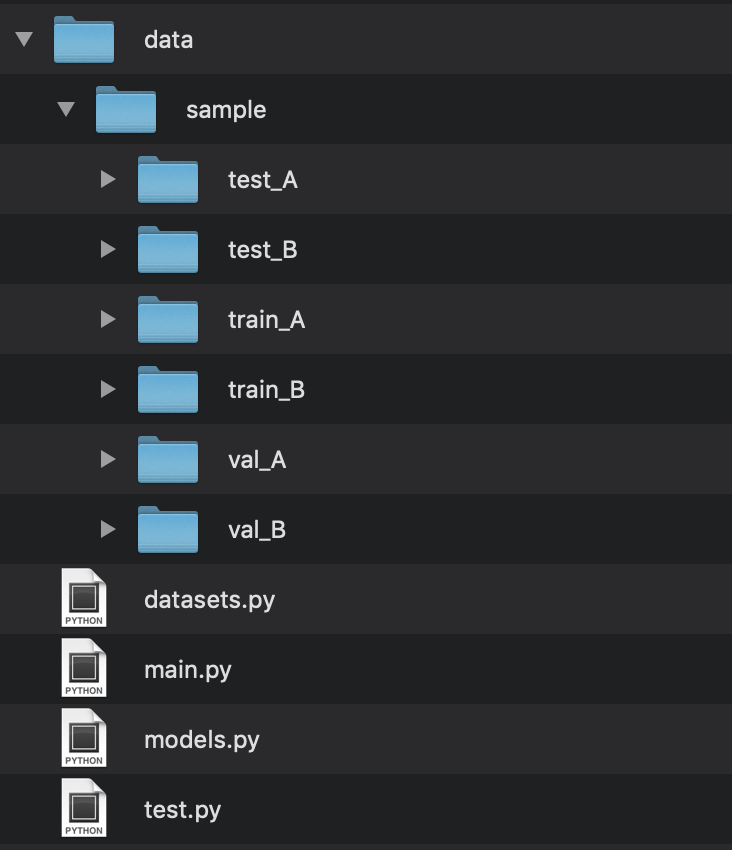
まずデータセットを用意します。ディレクトリ構造は以下のようになります。train_Aに変換前、train_Bに変換後の画像を入れます。それぞれ対応する画像は同じサイズで同じ名前をつけてください。同じようにval_Aとval_Bにも画像を入れます。data/sampleは自動で生成されないので自分で作成してください(test_Aとtest_Bは予測の際に使用します)。
次にtrainデータとvalデータそれぞれdataloaderを作成します。make_path_listとImageDatasetの中を見ていきます。
#trainに使う画像と、valに使う画像を分ける。
train_A, train_B = make_datapath_list(opt)
val_A, val_B = make_datapath_list(opt, phase="val")
dataloader = DataLoader(
#ImageDatasetはDatasetクラスをオリジナルに改変したもの->datasets.py
ImageDataset(train_A, train_B, opt, transforms_=transforms_),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
val_dataloader = DataLoader(
ImageDataset(val_A, val_B, opt, transforms_=transforms_),
batch_size=10,
shuffle=True,
num_workers=1,
)make_datapath_list関数でtrain_A、train_Bのデータリストを作成します。ImageDatsetクラスでは与えられたデータリストから画像データの行列データリストを作成します。今回、modeという引数はデフォルトでgray2colorになっています。これは1chの画像を3chの画像に変換するようなタスクで使用します。3ch画像から3ch画像の変換の際はcolor2colorを指定するようにします。
import glob
import random
import os
import numpy as np
import math
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
import sys
def make_datapath_list(opt, phase="train"):
#フォルダの名前の数を調べる
str_len = len('data/{}/{}_A/'.format(opt.dataset_name, phase))
#画像リスト(***.jpg形式)
filenames = glob.glob('data/{}/{}_A/*.jpg'.format(opt.dataset_name, phase))
img_list = [filename[str_len:] for filename in filenames]
#imgのリストをシャフルする
img_list = random.sample(img_list, len(img_list))
img_path_A = "data/{}/{}_A/%s".format(opt.dataset_name, phase)
img_path_B = "data/{}/{}_B/%s".format(opt.dataset_name, phase)
# 訓練データの画像ファイルとアノテーションファイルへのパスリストを作成
data_A = list()
data_B = list()
for img_l in img_list:
# file_id = line.strip() # 空白スペースと改行を除去
path_A = (img_path_A % img_l) # 画像のパス
path_B = (img_path_B % img_l) # アノテーションのパス
data_A.append(path_A)
data_B.append(path_B)
return data_A, data_B
class ImageDataset(Dataset):
def __init__(self, data_A, data_B, opt, transforms_=None):
self.transform = transforms.Compose(transforms_)
self.data_A = data_A
self.data_B = data_B
self.opt = opt
def __len__(self):
'''画像の枚数を返す'''
return len(self.data_A)
def __getitem__(self, index):
#画像Aの読み込み
data_A = self.data_A[index]
#convert("L").convert("RGB")としているのはモノクロ画像を3chにするため。
#カラー画像を使う場合はconvert("L").convert("RGB")を削除する。
if self.opt.mode == "gray2color":
img_A = Image.open(data_A).convert("L").convert("RGB")
else:
img_A = Image.open(data_A)
#画像Bの読み込み
data_B = self.data_B[index]
img_B = Image.open(data_B) # [高さ][幅][色RGB]
#transformはPILファイルで入れる
img_A = self.transform(img_A)
img_B = self.transform(img_B)
return {"A": img_A, "B": img_B}次にネットワークを見ていきます。pix2pixではU-Netを用います。U-NetとはAutoEncoderの一種で以下のようなネットワークの形をしています。
通常のEncoder-decoderとの違いは、DecoderでEncoderの出力を結合している点です。これをスキップコネクションといいます。U-netはセマンティックセグメンテーションでよく使われます。このタスクにおいて物体の位置はできるだけ残したい情報です。しかしCNNでは畳み込みをするほど位置情報が曖昧になるので、それを保持できるような仕組みとしてスキップコネクションが使われました。pix2pixでも画像の位置は維持するべき情報であるので、U-netを使用しています。
import torch.nn as nn
import torch.nn.functional as F
import torch
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class UNetDown(nn.Module):
def __init__(self, in_size, out_size, normalize=True, dropout=0.0):
super(UNetDown, self).__init__()
layers = [nn.Conv2d(in_size, out_size, 4, 2, 1, bias=False)]
if normalize:
layers.append(nn.InstanceNorm2d(out_size))
layers.append(nn.LeakyReLU(0.2))
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class UNetUp(nn.Module):
def __init__(self, in_size, out_size, dropout=0.0):
super(UNetUp, self).__init__()
layers = [
nn.ConvTranspose2d(in_size, out_size, 4, 2, 1, bias=False),
nn.InstanceNorm2d(out_size),
nn.ReLU(inplace=True),
]
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x, skip_input):
x = self.model(x)
x = torch.cat((x, skip_input), 1)
return x
class GeneratorUNet(nn.Module):
def __init__(self, in_channels=3, out_channels=3):
super(GeneratorUNet, self).__init__()
self.down1 = UNetDown(in_channels, 64, normalize=False)
self.down2 = UNetDown(64, 128)
self.down3 = UNetDown(128, 256)
self.down4 = UNetDown(256, 512, dropout=0.5)
self.down5 = UNetDown(512, 512, dropout=0.5)
self.down6 = UNetDown(512, 512, dropout=0.5)
self.down7 = UNetDown(512, 512, dropout=0.5)
self.down8 = UNetDown(512, 512, normalize=False, dropout=0.5)
#up1->up2と層を重ねていくとき、次の層のinputは
#結合する層のchを足し合わせたchにする。
self.up1 = UNetUp(512, 512, dropout=0.5)
self.up2 = UNetUp(1024, 512, dropout=0.5)
self.up3 = UNetUp(1024, 512, dropout=0.5)
self.up4 = UNetUp(1024, 512, dropout=0.5)
self.up5 = UNetUp(1024, 256)
self.up6 = UNetUp(512, 128)
self.up7 = UNetUp(256, 64)
self.final = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(128, out_channels, 4, padding=1),
nn.Tanh(),
)
def forward(self, x):
d1 = self.down1(x)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
d6 = self.down6(d5)
d7 = self.down7(d6)
d8 = self.down8(d7)
u1 = self.up1(d8, d7)
u2 = self.up2(u1, d6)
u3 = self.up3(u2, d5)
u4 = self.up4(u3, d4)
u5 = self.up5(u4, d3)
u6 = self.up6(u5, d2)
u7 = self.up7(u6, d1)
return self.final(u7)
class Discriminator(nn.Module):
def __init__(self, in_channels=2):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, normalization=True):
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
#第一層だけはnormalizationをfalseにする。
#最初のレイヤーでinstancenormを使用する場合、入力画像の色は正規化され、
#無視される。入力画像の色を保持したい場合は最初のレイヤーでは
#InatanceNorm2dを行わない。
if normalization:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(in_channels * 2, 64, normalization=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1, bias=False)
)
def forward(self, img_A, img_B):
img_input = torch.cat((img_A, img_B), 1)
return self.model(img_input)次に訓練の部分です。pix2picでは条件付きのGAN LossとL1 Lossを使用します。ここでL1ロスを使用するとL2 lossよりもぼやけのない画像を生成することができます。
# Loss functions
criterion_GAN = torch.nn.MSELoss()
# L1loss
criterion_pixelwise = torch.nn.L1Loss()
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# 本物の画像の行列データ
real_A = Variable(batch["A"].type(Tensor))
real_B = Variable(batch["B"].type(Tensor))
# 正解ラベル
valid = Variable(Tensor(np.ones((real_A.size(0), *patch))), requires_grad=False)
# 偽物ラベル
fake = Variable(Tensor(np.zeros((real_A.size(0), *patch))), requires_grad=False)
#optimizerが持つvariable型のパラメーターを初期化する
optimizer_G.zero_grad()
fake_B = generator(real_A)
pred_fake = discriminator(real_A, fake_B)
#正解ラベルを与え、それに近づけるように学習
loss_GAN = criterion_GAN(pred_fake, valid)
# Pixel-wise loss
loss_pixel = criterion_pixelwise(fake_B, real_B)
# Total loss
loss_G = loss_GAN + lambda_pixel * loss_pixel
#勾配の計算
loss_G.backward()
#パラメーターの更新
optimizer_G.step()
optimizer_D.zero_grad()
# Real loss
pred_real = discriminator(real_A, real_B)
loss_real = criterion_GAN(pred_real, valid)
# detach()とすることでrequires_grad=Falseとなるのでそれ以降の微分はされない。
# detach()なしだと、fake_Bを通じて勾配がGに伝わってしまう。
pred_fake = discriminator(real_A, fake_B.detach())
#偽物と判断するようにする。
loss_fake = criterion_GAN(pred_fake, fake)
# Total loss
loss_D = 0.5 * (loss_real + loss_fake)
loss_D.backward()
optimizer_D.step()
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, pixel: %f, adv: %f] ETA: %s"
% (
epoch,
opt.n_epochs,#総エポック数
i,#iter数
len(dataloader),#バッチ数
loss_D.item(),
loss_G.item(),
loss_pixel.item(),
loss_GAN.item(),
time_left,
)
)
# 画像をサンプリングするタイミング
if batches_done % opt.sample_interval == 0:
sample_images(batches_done)
#モデルを保存するタイミング
if epoch % opt.checkpoint_interval == 0:
torch.save(generator.state_dict(), "saved_models/%s/generator_%d.pth" % (opt.dataset_name, epoch))
torch.save(discriminator.state_dict(), "saved_models/%s/discriminator_%d.pth" % (opt.dataset_name, epoch))
torch.save(generator.state_dict(), "saved_models/%s/generator_last.pth" % (opt.dataset_name))
torch.save(discriminator.state_dict(), "saved_models/%s/discriminator_last.pth" % (opt.dataset_name))すべてのコードはここにのせてあります。

訓練の経過
最後に訓練過程を見ていきます。今回のデータセットはサイズ256*256の砂漠の画像584枚です。各画像をOpenCVで線画化しました。1000iterですでに色情報などを捉えているような画像もあります。50000iterでは本物に近い着色ができています。pix2pixは教師ありの画像変換であるので訓練が安定しています。





訓練で使用していない画像で予測してみました。pix2pixのディレクトリでtest.pyを実行してください。
結果は以下のようになりました。左から線画、予測した画像、本物の画像になります。あまりうまく変換できていません。もう少しデータ数を増やす必要があるかもしれません。。。



ちなみに、訓練画像で予測してみるとよく変換されているので過学習している可能性がありますね。

さいごに
今回、Batchsize=1で200epoch訓練しましたが、Google Colaboratoryで約4時間かかりました。さらにデータ数を増やせばより、精度は高まると考えられます。またpix2pixをはじめImage-to-ImageなGANはGoogle Colaboratoryでも動かせるモデルが多いので今後もいろいろ試していきたいと思います。

