
やること
第2回ビネクラ杯の問題は、野口英世の画像を20×20個のパーツに分解し、並べ替えたり回転させたりして北里柴三郎を作るというものです。

まずは画像の読み込みと単純なアルゴリズムを試してみましょう。Pythonで実装していますが、コンテストは言語によりませんので、得意の言語でチャレンジしてみてください!
実行環境
WinPython3.6をおすすめしています。

Google Colaboratoryが利用可能です。

単純なアルゴリズム
2枚の画像について、各パーツの平均輝度値を調べます。

このランキングをもとに、「北里の輝度値n位のブロックに野口の輝度値n位のパーツを当てはめる」を繰り返していくだけです。回転はしないことにします。
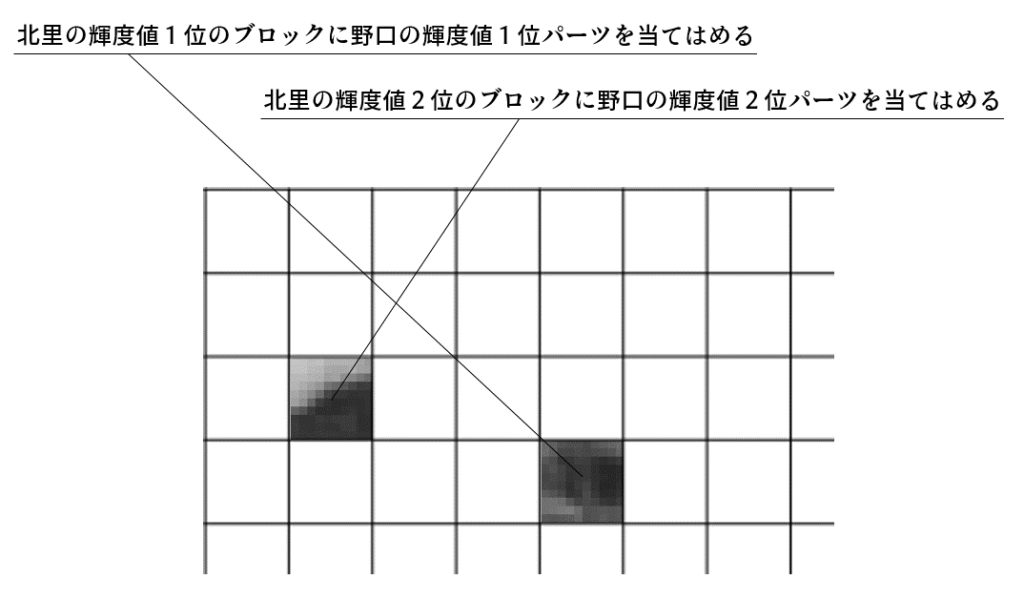
やっているうちにどっちのランキングをどう参照していいか混乱するので、「北里のブロックに」「野口のパーツを」を念仏のように唱えます。
pip, import
必要なパッケージをpipしてimportします。今回はOpenCVを使います。
pip install opencv-pythonimport cv2
import numpy as np
import matplotlib.pyplot as plt設定~問題データの読み込み
野口英世と北里柴三郎の画像は問題ページからダウンロードして置いてください。
画像を表示する関数、パーツを回転させる関数、パーツセットから画像を再構成する関数の3つを用意しました。これらは便利なので末永く使えると思います。
#============================
# パラメータ
#============================
#画像
noguchi_file = 'vccup2_img1.png'
kitazato_file = 'vccup2_img2.png'
#たてよこ分割数
num = 20
#============================
# 関数
#============================
#ndarray形式の画像を表示
def show(img):
plt.figure(figsize=(8, 8))
plt.imshow(img, vmin = 0, vmax = 255)
plt.gray()
plt.show()
plt.close()
print()
#ndarray形式のパーツを90°回転(反時計回りにn回)
def rotate(img, n):
return np.rot90(img, n)
#パーツセットから1枚の画像を再構成
def marge(ims):
tmp = [cv2.hconcat([ims[i*num + j] for j in range(num)]) for i in range(num)] #横長の短冊にして
img = cv2.vconcat([tmp[i] for i in range(num)]) #縦に並べる
return img
#============================
# 画像の読み込み
#============================
#野口英世をグレースケール(1ch)で読み込む(cv2で読むとndarrayになっている)
noguchi_img = cv2.imread(noguchi_file, cv2.IMREAD_GRAYSCALE)
#サイズの確認
print('noguchi_img.shape:{}'.format(noguchi_img.shape))
#表示
show(noguchi_img)
#北里柴三郎も読み込む
kitazato_img = cv2.imread(kitazato_file, cv2.IMREAD_GRAYSCALE)
print('kitazato_img.shape:{}'.format(kitazato_img.shape))
#表示
show(kitazato_img)
#1ブロックの幅
w = noguchi_img.shape[0] // numnoguchi_img.shape:(200, 200)
kitazato_img.shape:(200, 200)

読み込めました。
パーツへの分割~輝度値ランキングの計算
画像を20×20個のパーツに分解し、各パーツの平均輝度値を調べます。
#============================
# 画像をパーツに分解する
#============================
#野口
noguchi_ims = []
for tanzaku in np.vsplit(noguchi_img, num): #横長の短冊にして
noguchi_ims += np.hsplit(tanzaku, num) #正方形に切る
noguchi_ims = np.array(noguchi_ims)
print('noguchi_ims.shape:{}'.format(noguchi_ims.shape))
#北里
kitazato_ims = []
for tanzaku in np.vsplit(kitazato_img, num): #横長の短冊にして
kitazato_ims += np.hsplit(tanzaku, num) #正方形に切る
kitazato_ims = np.array(kitazato_ims)
print('kitazato_ims.shape:{}'.format(kitazato_ims.shape))
#============================
# パーツの平均輝度値を調べる
#============================
#野口
noguchi_kido = np.zeros(num**2)
for i in range(num**2):
noguchi_kido[i] = np.mean(noguchi_ims[i])
print('noguchi_kido[:10]:\n{}'.format(noguchi_kido[:10]))
#北里
kitazato_kido = np.zeros(num**2)
for i in range(num**2):
kitazato_kido[i] = np.mean(kitazato_ims[i])
print('kitazato_kido[:10]:\n{}'.format(kitazato_kido[:10]))
#============================
# パーツの輝度値が低い順のインデックスを調べる
#============================
#野口の輝度値が小さい順のインデックス
noguchi_kido_rank = np.argsort(noguchi_kido)
print('noguchi_kido_rank[:10]:\n{}'.format(noguchi_kido_rank[:10]))
#野口の輝度値が小さい順のインデックス
kitazato_kido_rank = np.argsort(kitazato_kido)
print('kitazato_kido_rank[:10]:\n{}'.format(kitazato_kido_rank[:10]))noguchi_ims.shape:(400, 10, 10)
kitazato_ims.shape:(400, 10, 10)
noguchi_kido[:10]:
[174.27 177.49 201.21 218.25 217.09 181.33 135.41 172.01 120.69 156.65]
kitazato_kido[:10]:
[186.37 187.17 185.79 184.74 183.21 182.68 183.13 179.23 174.21 173.97]
noguchi_kido_index[:10]:
[155 135 71 314 357 334 315 356 333 352]
kitazato_kido_index[:10]:
[399 379 325 378 344 398 227 47 384 345]輝度値ランキング(_rank)は、平均輝度値を小さい順に並べるためのインデックスです。例えば noguchi_kido_rank の最初は 155 ですが、これは野口パーツの155番目(ただし0始まり)がもっとも黒いことを意味します。同様に北里パーツの399番目(0始まりなので一番右下ですね)がもっとも黒いです。したがって、北里ブロック399番に野口パーツ155番が当てはまります。
野口パーツの当てはめ~提出用テキストの保存
この当てはめる部分のコードは、コーヒーでも淹れて落ち着いて考えないと間違いやすいです。最後にビネクラ杯提出用テキストの出力コードもつけました!とりあえず作品を出せます。
#============================
# 野口パーツを当てはめる
#============================
#新しいパーツ配列と番号記録用配列を用意
new_ims = np.zeros(kitazato_ims.shape, int)
parts = np.zeros(num**2, int)
#対応するインデックスのところに野口パーツを当てはめる
for i in range(num**2):
new_ims[kitazato_kido_rank[i]] = noguchi_ims[noguchi_kido_rank[i]]
parts[kitazato_kido_rank[i]] = noguchi_kido_rank[i]
#画像を再構成して表示
new_img = marge(new_ims)
show(new_img)
#============================
# 提出用のテキストファイルを保存
#============================
with open('yourname.txt', 'w') as f:
for i in range(num**2):
text = '{} {}\n'.format(parts[i] + 1, 0) #パーツ番号は1始まりなので1を足す、回転しないので0
f.write(text)
遠目で見るとじんわりと北里先生のご尊顔が・・・?
おまけ
当てはめのGIFもどうぞ。

また、パラメータ欄に「たてよこ分割数」という数字を用意しておきました。これを変えると20×20以外の分割数でも検証できます(ただし画像サイズ200の約数のみ)。200×200分割だと1ピクセルずつ当てはめていくので限りなく精巧だとは思いますが。。


