はじめに
先日、HOBO対応したアニーリングパッケージ「HOBOTAN」を紹介しました。現在は「TYTAN」に統合され、TYTANひとつでQUBOもHOBOもGPUアニーリングできるようになりました。
現在、有志でHOBOのテンソル計算の精度確認と高速化に取り組んでいるのですが、なんか間違ったエネルギーの値が返ってくるなと思ったら数値の型が原因のようでした。
通常、Numpyはデフォルトで「float64」ですが、PyTorchは「float32」らしいです。ですからNumpyでは正しい値が返ってきていたものが、PyTorch(GPUモード)に変えたら間違った値が返ってきたということでした。
非常に雑な言い方ですが、単精度(float32)は7桁、倍精度(float64)は15桁の数字を表現できるとのことで、「大きな数」や「小数点以下すごい細かい数」を正確に計算したい場合は倍精度を使おう、というイメージです。
ということでPyTorchのコードでfloat64を指定して問題は解決しましたが、計算速度は10分の1程度まで遅くなってしまいました。倍精度の計算は遅い!単精度用の計算ユニットをFP32ユニット、倍精度用をFP64ユニットと呼ぶことにすると、GPUによってはFP32ユニットに比べてFP64ユニットの搭載数が非常に少なく、単精度に比べて倍精度の計算がとても遅いということになります。
実際、FP32ユニットとFP64ユニットがどのような比率で搭載されているのか勉強してみました。
参考文献
様々なサイトで勉強させていただきました。専門的な用語を分かりやすく解説してくださっている先人たちに感謝申し上げます。





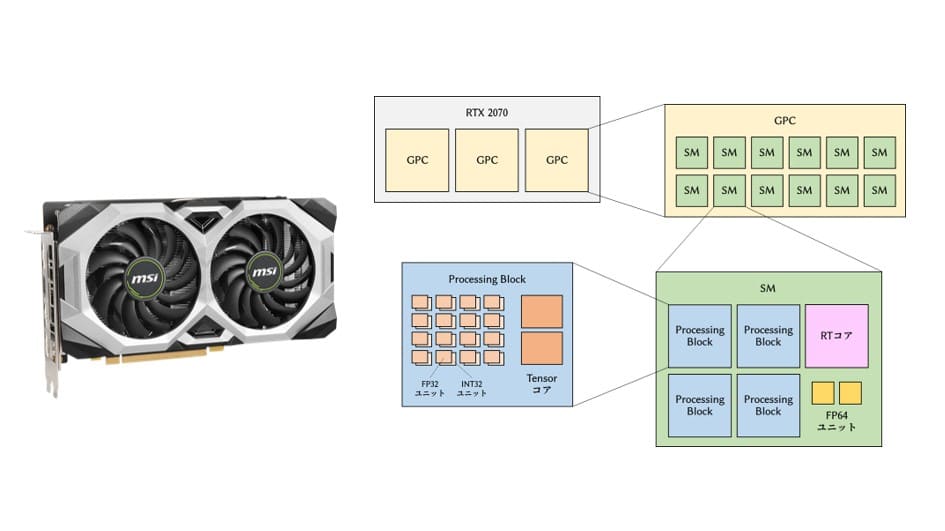
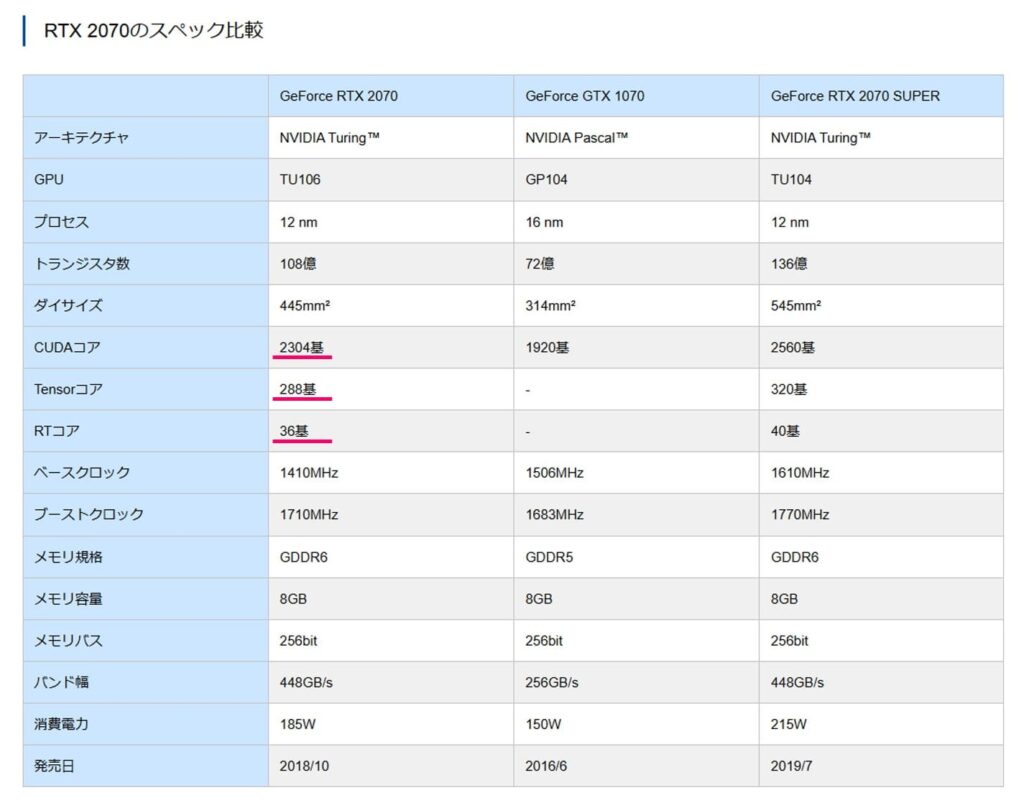
GeForce RTX 2070のスペック
うちでメインで使用しているTuring世代のGPU「GeForce RTX 2070」について調べてみました。

ドスパラのサイトによると、CUDAコアが2304基、Tensorコアが288基、RTコアが36基と書かれています。
PyTorchでの数値計算に関係するのは「CUDAコア」と「Tensorコア」の数です。しかし、どうやらこれらのコアを分解してFP32ユニット、FP64ユニットの数を確認しないと計算速度が分からないようです。(RTコアはおそらく無関係なのでここでは考えないことにします)
FP32ユニットとFP64ユニットの数を求める
まずはスペック表に書かれているCUDAコア=2304基、Tensorコア=288基にたどり着くことを目指しましょう。
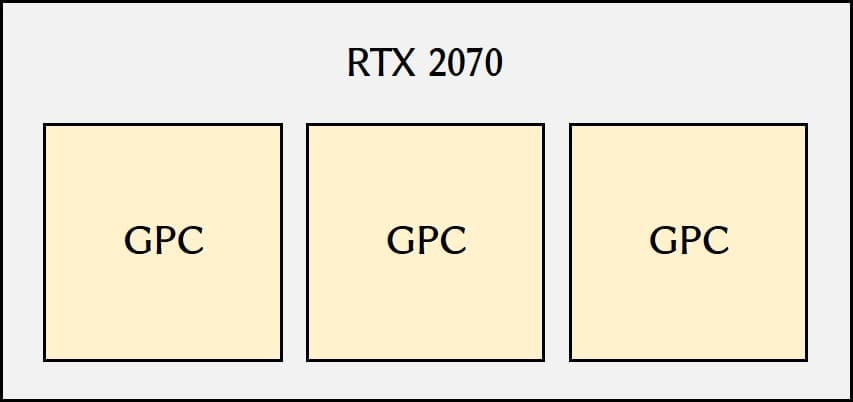
RTX 2070にはGPC(Graphics Processing Cluster)という塊が3つ入っているらしい。
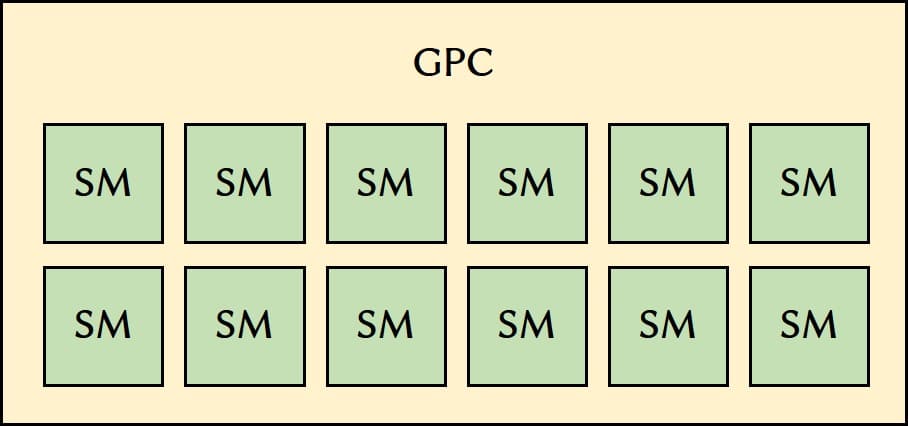
Turingアーキテクチャには上位から順に「TU102」「TU104」「TU106」があり、RTX 2070はTU106のようです。TU106は1つのGPCあたり12個のStreaming Multiprocessor(SM)が入っています。
SMの中を見ていきましょう。ここには4個のProcessing Blockと1基のRTコア、2個のFP64ユニットが配置されています。RTコアとFP64ユニットの勘定はこの段階で完了です。
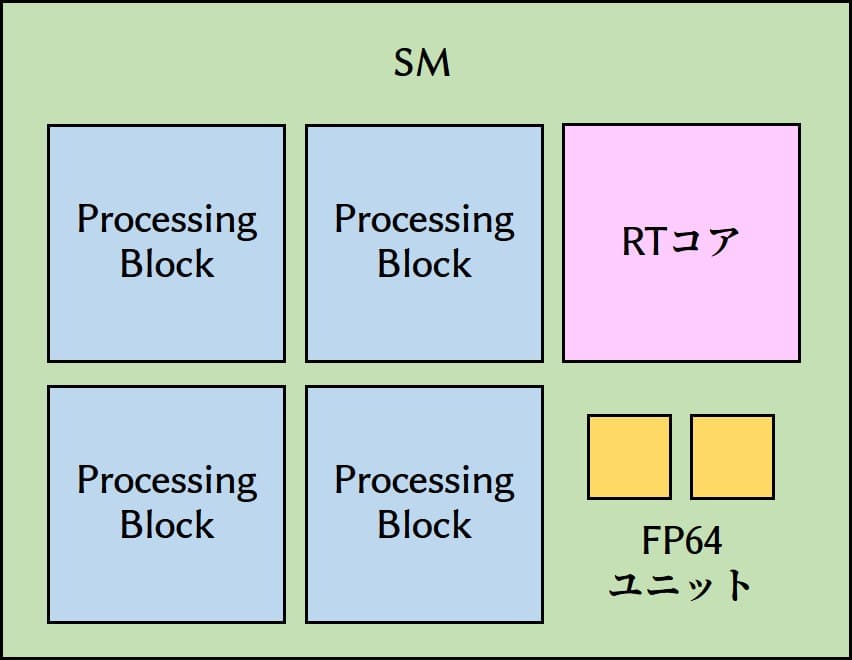
さらにProcessing Blockの中を見てみると、16個のFP32ユニット、16個のINT32ユニット、2基のTensorコアがあります。FP32ユニットとINT32ユニットをセットで「CUDAコア」とカウントしているらしいので、ここには16基のCUDAコアがあることになります。これですべてのコアとユニットの勘定が完了しました。
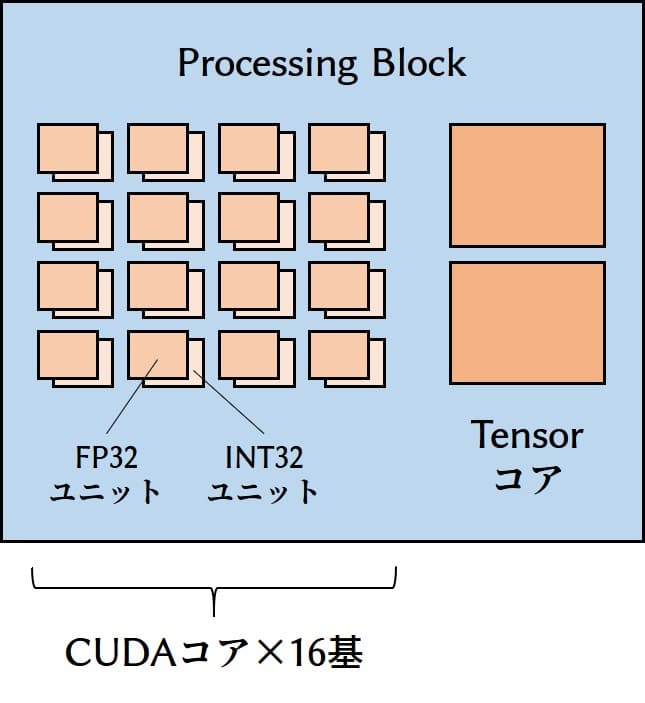
結局、RTX 2070は
- CUDAコア=3×12×4×16=2304基
- Tensorコア=3×12×4×2=288基
が搭載されていることになり、カタログと一致しました。Tensorコアはほとんど半精度(FP16)用、深層学習で活躍するものらしくここでは一旦無視します。
さらに、ユニットの数で言うと
- FP32ユニット=3×12×4×16=2304個(CUDAコアと同じ)
- FP64ユニット=3×12×2=72個
となっており、単精度に比べて倍精度の計算速度は32分の1になると見積もられました。
一般に「FP64の性能はFP32の32分の1」という情報をよく見ます。
しかし、グラフィックス向けのTuringでは、FP64の性能はFP32の32分の1となっている。各サイクルにSM毎に2命令のスループットだ。
https://pc.watch.impress.co.jp/docs/column/kaigai/1143278.html
GPGPU用ではないGeForceブランドのGPUは,一部の例外を除いてFP64の演算性能は,
https://www.4gamer.net/games/527/G052743/20200911024/
・FP32演算性能:FP64演算性能=32:1
このことは上記の計算を見れば納得できます。
まとめ
全体を一枚の画像にまとめるとこのようになります。
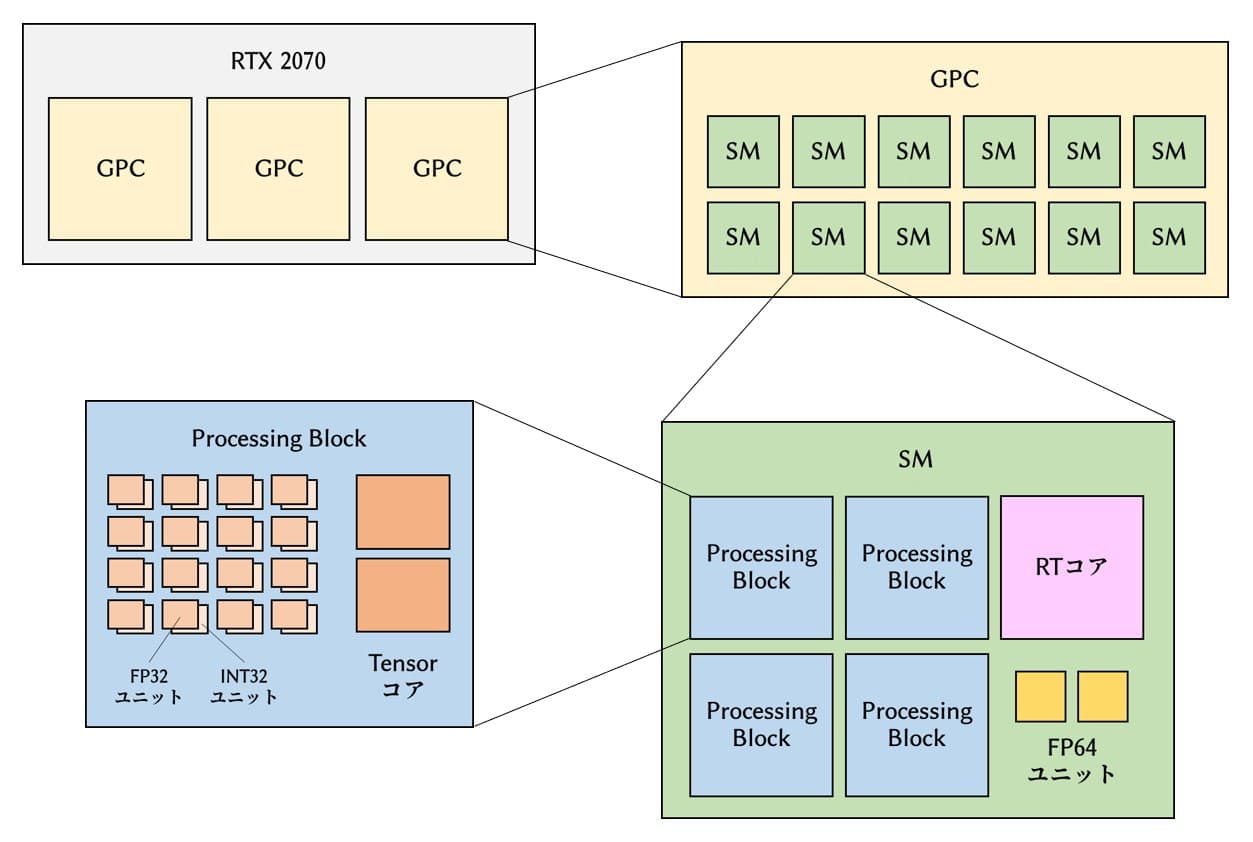
個々のレイヤーの解説は見つかるのですが、全体を俯瞰した解説がなかなか見当たらなかったのでこの記事を書きました。まあ多分いろいろ間違っていると思うので優しく指摘してください。
なお、「H100」や「A100」といったGPGPU用の製品ではFP64が有利になっており、精密な計算やシミュレーションに用いられています。また、NVIDIAは「データセンターでGeForceを使わないで」とも言っています(→GeForceのデータセンター利用を禁止する使用許諾契約に対してNVIDIAが声明)。GeForceと計算専用GPUの比較もしてみたいところですね。
一応、「H100」「A100」用の専用クーラーも販売していますのでぜひ見てみてください。
