
やること
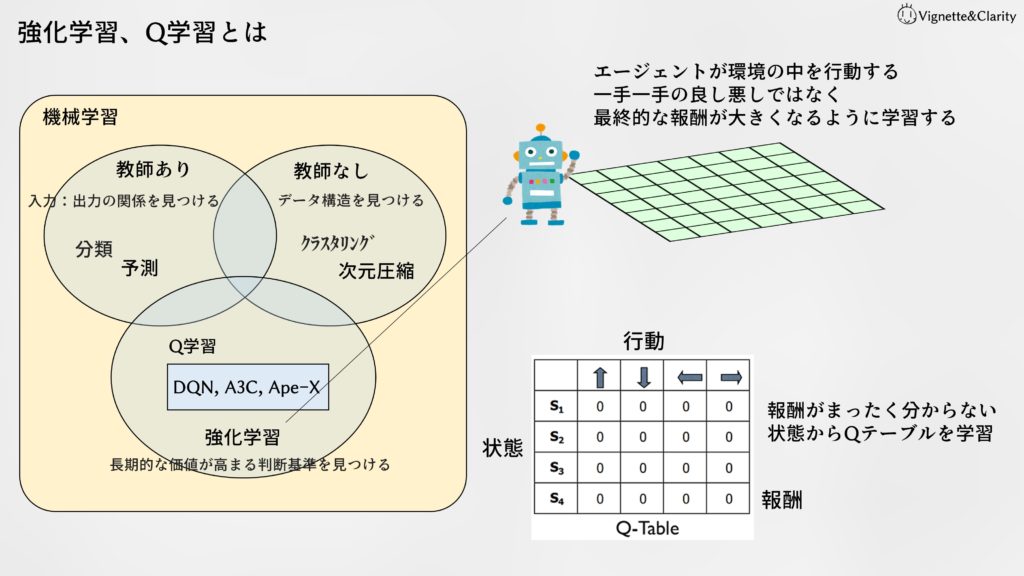
機械学習は、教師あり学習、教師なし学習、強化学習の3つに分けて語られることが多いです。強化学習は、「長期的な価値が高くなるような判断基準を見つける」感じの学習です。今日は、強化学習の基本である「Q学習」を知り、「Deep Q-network(DQN)」のアルゴリズムを確認してみます。
使うもの

AIワークショップ|初心者だけど強化学習(DQN)できちゃった (2018/09/28 19:00〜)
# 情報交換はAI FASHIONのSlack(参加ボタン)の方でお願いします。 ## 概要 ノートPCを持参して、強化学習で「迷路を解く」AIを作ってみよう。 「プログラム環境の準備」からやりますの...
aifashion.connpass.com
強化学習とは
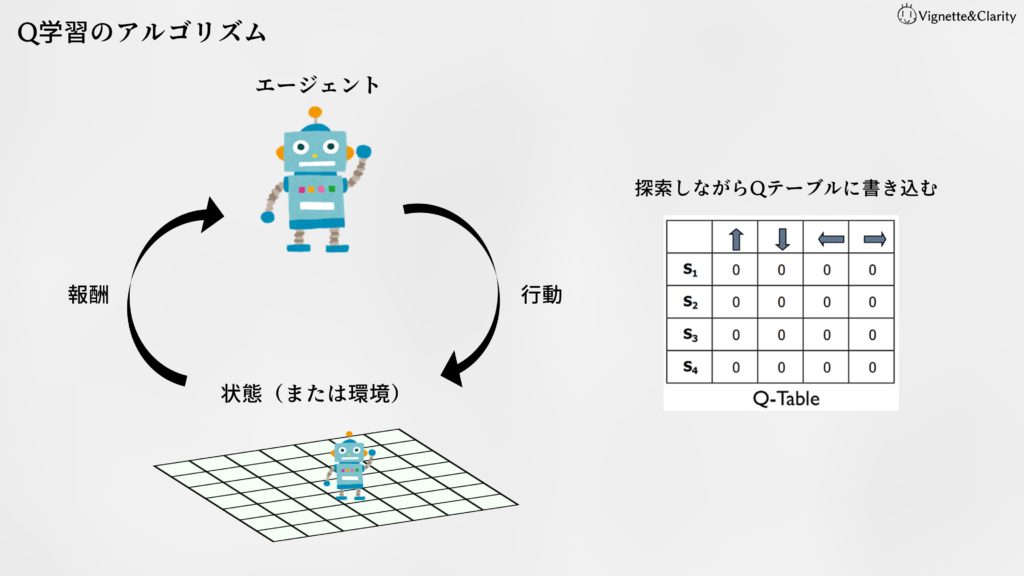
強化学習では、
- エージェントが行動する
- 状態(または環境)から報酬を得る
ことを繰り返しながら、報酬(目先のではなく長期的な報酬)が高くなるような行動基準を見つけます。
強化学習>Q学習のアルゴリズム
 「適当に行動する」うーん、よくわからんからとりあえずランダムに動いてみよう
「適当に行動する」うーん、よくわからんからとりあえずランダムに動いてみよう




複雑なゲームだとQテーブルが作れない
Q学習ではたくさん行動してひたすらQテーブル(どんな状態でどんな行動をすると何点の報酬がもらえるか)を埋めていきますが、囲碁やビデオゲームでは「状態×行動」のパターンが多すぎるため、Qテーブルすべてを埋めているうちに22世紀が来てしまいます。



