
やること
Quine(クワイン)という遊びをご存知でしょうか。
クワイン(英: Quine)は、コンピュータープログラムの一種で、自身のソースコードと完全に同じ文字列を出力するプログラムである。
WIkipedia「クワイン (プログラミング)」
つまり、「print(‘aaa’)」を実行すると「print(‘aaa’)」が出力されるようなコードを作る遊びです。これ、やってみると分かりますが異質な難しさがあります。
いろいろなプログラミング言語で複数タイプのQuineが見出されていますが、ここではPythonにおける比較的シンプルな仕組みのQuineを解説します。ネタバレになるので、まずはヒント無しで挑戦してその面白さを体験してみてください。
参考文献
こちらのアイデアを参考にさせていただきました。というかこれを解説します。先達に感謝です。

何をやっているか?
きちんとステップバイステップで説明しようと考えましたが、今回はうまい説明が思いつきませんでした。3つか4つの課題を逐次的に解決していくのではなく「こうすれば全部の課題が一度に解決する」とあまりに閃き頼りで説明できません。
結論、こういうことをしています。原文を暗号化するという発想で「入れ子問題」「尾ひれ問題」などを一挙に解決するため、仕組みはシンプルだと思います。
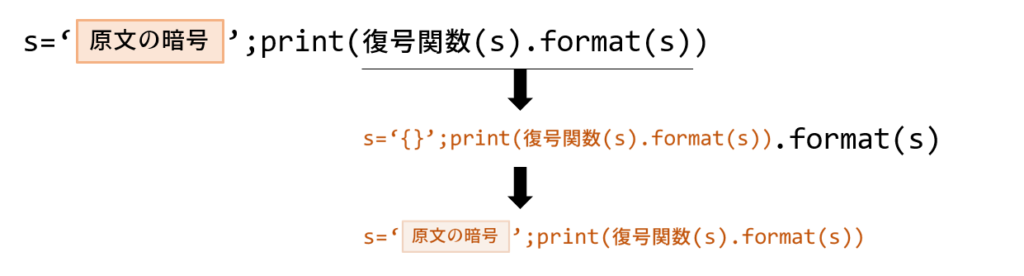
作成ステップ
では実際に作ってみます。
まず、原文を何らかのアルゴリズムで暗号化する必要があるので、暗号化関数・復号関数を用意します。この暗号に求められる要件は、quineで入れ子問題を発生させる「代入」「print」「{}」なんかを含まないことです。極端な話、全部数字とかに変換してしまえばOKです。
そこで、文字列を一文字ずつに分解し、Unicode値という整数に変換してカンマ結合して返す関数を暗号化関数としました。そして、その暗号を文字列に戻す関数を復号関数としました。
#暗号化関数
def enc(ccc):
return ','.join([str(ord(c)) for c in ccc])
#復号関数
def dec(ccc):
return ''.join([chr(int(c)) for c in ccc.split(',')])
print(enc('print()'))
print(dec('112,114,105,110,116,40,41'))112,114,105,110,116,40,41
print()「print()」という文字列を暗号化すると「112,114,105,110,116,40,41」という文字列になり、それを復号すると「print()」に戻りました。7文字なので整数も7個になります。
次に、format(s)を適用する前の文字列({} に親のsを入れると原文になるやつ)↓

を暗号化します。また、それを複合して元に戻るか確認します。
print(enc("s='{}';print(dec(s).format(s))"))
print(dec('115,61,39,123,125,39,59,112,114,105,110,116,40,100,101,99,40,115,41,46,102,111,114,109,97,116,40,115,41,41'))115,61,39,123,125,39,59,112,114,105,110,116,40,100,101,99,40,115,41,46,102,111,114,109,97,116,40,115,41,41
s='{}';print(dec(s).format(s))成功しました。
そして、その文字列の {} に暗号を入れた文字列↓

を作ってコンソールで実行します。これで99%完成です。
# s='{}';print(dec(s).format(s)) の{}に暗号を挿入
s='115,61,39,123,125,39,59,112,114,105,110,116,40,100,101,99,40,115,41,46,102,111,114,109,97,116,40,115,41,41';print(dec(s).format(s))s='115,61,39,123,125,39,59,112,114,105,110,116,40,100,101,99,40,115,41,46,102,111,114,109,97,116,40,115,41,41';print(dec(s).format(s))できました。出力が原文と同じになっています。
この原文は「dec()」という独自関数を含んでいるので、この関数を解除したバージョンでもう一度最初から作ります。つまり、
print(enc("s='{}';print(''.join([chr(int(c)) for c in s.split(',')]).format(s))"))から始めるということです。
# s='{}';print(''.join([chr(int(c)) for c in s.split(',')].format(s)) の{}に暗号を挿入
s='115,61,39,123,125,39,59,112,114,105,110,116,40,39,39,46,106,111,105,110,40,91,99,104,114,40,105,110,116,40,99,41,41,32,102,111,114,32,99,32,105,110,32,115,46,115,112,108,105,116,40,39,44,39,41,93,41,46,102,111,114,109,97,116,40,115,41,41';print(''.join([chr(int(c)) for c in s.split(',')]).format(s))s='115,61,39,123,125,39,59,112,114,105,110,116,40,39,39,46,106,111,105,110,40,91,99,104,114,40,105,110,116,40,99,41,41,32,102,111,114,32,99,32,105,110,32,115,46,115,112,108,105,116,40,39,44,39,41,93,41,46,102,111,114,109,97,116,40,115,41,41';print(''.join([chr(int(c)) for c in s.split(',')]).format(s))これで100%完成しました。
参考文献の解説
念のため参考文献のパターンも見てみましょう。本記事では暗号化関数として「文字をUnicode値に変換する」という独自関数を使用しました。参考文献では「文字列をBase64値に変換する」という暗号化関数を用いているだけで考え方はまったく同じです。
つまりこれを準備して↓
import base64
#暗号化関数
def enc(ccc):
return base64.b64encode(ccc.encode()).decode()
#復号関数
def dec(ccc):
return base64.b64decode(ccc).decode()原文の冒頭に「import base64」を付けることに注意して作り始めればできます。
print(enc("import base64;s='{}';print(dec(s).format(s))"))base64エンコード・デコードがちょっと理解しづらく、いきなりこれを理解しようとすると躓くかと思って先に独自関数で説明しました。
さいごに
これが唯一ということではなく、いろいろなタイプがあるみたいです。むしろこの方法はちょっと反則気味かもしれません(?)。興味がある方は他の方法も調べてみてください。

