
やること
QUBOアニーリングでお世話になっている「TYTAN」パッケージ。
どれくらいの規模の問題が解けるの?メモリ使用量は?計算速度は?ちゃんと大域解が見つかる?学歴は?年収は?結婚してる?
調べてみた結果、よく分かりませんでした。いかがでしたか?
調べてみました。
TYTANについて
「TYTAN」はOSSのアニーリングSDKです。
チュートリアル教材はこちら。また、毎週木曜日22時にオンライン勉強会もやっています(2023年12月現在)。
discordコミュニティもあるので気軽に質問できます。
検証方法
最適解(大域解)が既知である2種類の問題を用意しました。Nを量子ビット数とします。
シフト最適化(ナーススケジューリング問題)
過去記事のシフト最適化問題を拡張して、N=24 なら24時間枠に対して24人の候補者、N=48 なら48時間枠に対して48人の候補者にしました。実装の都合上、大きな谷を2つ持っているはずです。Nを480まで増やして比較します。

連立方程式
過去記事の連立方程式を拡張して、N=24 なら [x, y, z] を各8量子ビットで、N=48 なら [x, y, z] を各16量子ビットで刻むようにしました。深めの局所解が規則的に大量に並んでいます。Nを480まで増やして比較します。
(1) 


結果:メモリ(RAM)使用量
sys.getsizeof(qubo)で変数のメモリ使用量を調べました。solver.run(qubo) に入力するQUBO(辞書型)と、内部でエネルギーを計算する際に使用するQUBO(行列)の両方を調べてみました。
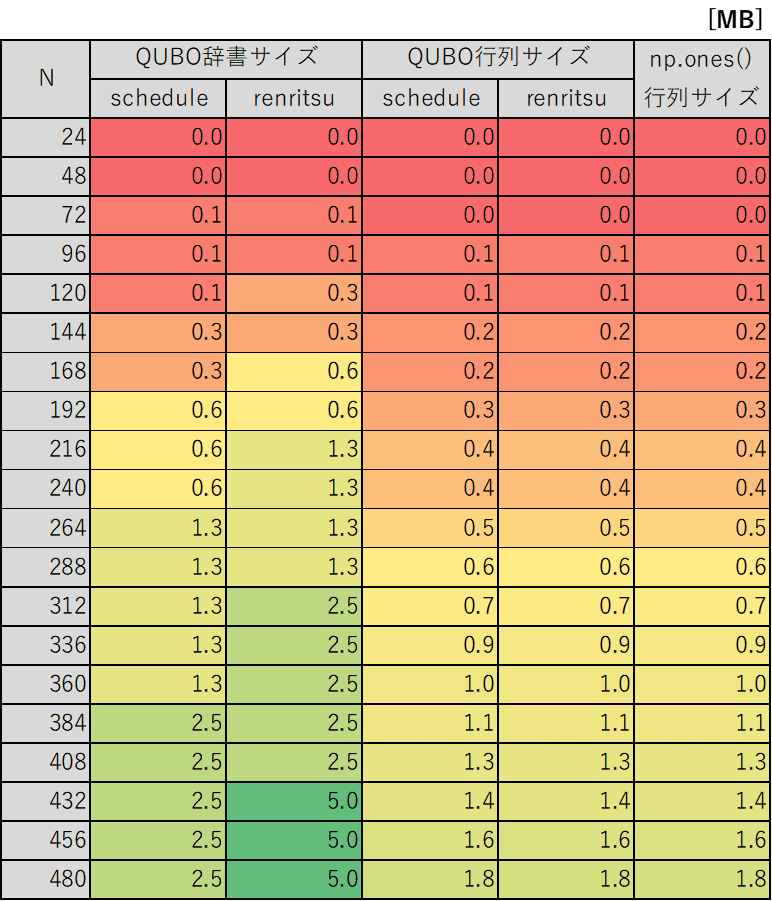
連立方程式の480量子ビットでは約5MBになりました。QUBO(行列)は、単純に np.ones((N, N)) で作った行列と同じサイズでした(それはそう)。QUBO(辞書型)はその2~3倍と見積もることができそうです。
したがって、例えば1万量子ビットは
arr = np.ones((10000, 10000), float)
print(sys.getsizeof(arr)/1024**2, 'MB')762.9 MBなので余裕を持って5倍してRAM 4GBは見ておいたほうが良さそうです。
2万量子ビットなら
3051.8 MBなのでRAM 16GBは欲しい。
4万量子ビットなら
12207.0 MBなのでRAM 64GBを覚悟。
なお、TYTAN利用者から「2万量子ビットで100GBくらい使うんだが」という情報を頂いています。問題によって、あるいは他の変数も含めるとそれくらいになるのですね。うーんこの。
結果:計算速度(計算時間)
コンパイル時間は対象とせず、アニーリングの時間だけを測りました。
s = time.time()
result = solver.run(qubo, shots=100)
print(time.time() - s)CPUがかなり古いので(i7-6500T)、相対的な指標として見てください。
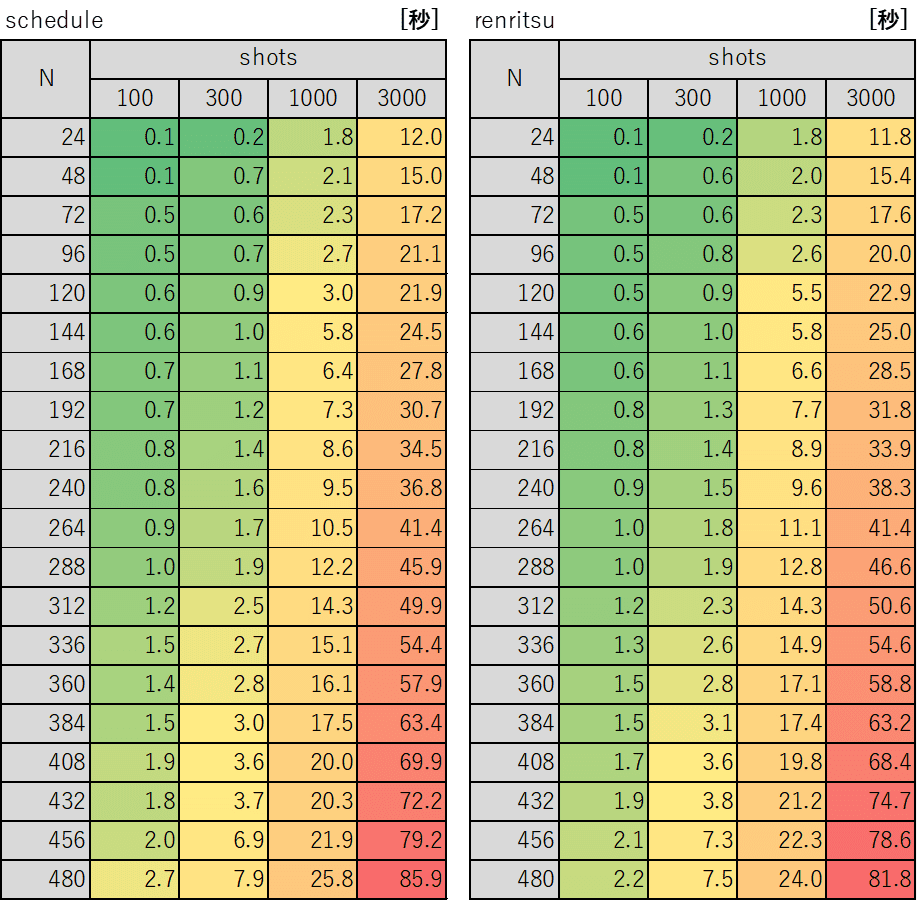
一発実験なのでブレがあるかと思います。Nにもshotsにもだいたい比例する感じでした。なお、480量子ビットにもなるとコンパイル時間もバカにならないという。
結果:正解率
shots=100で最適解(大域解)が得られたかどうかを0or1で判定しました。
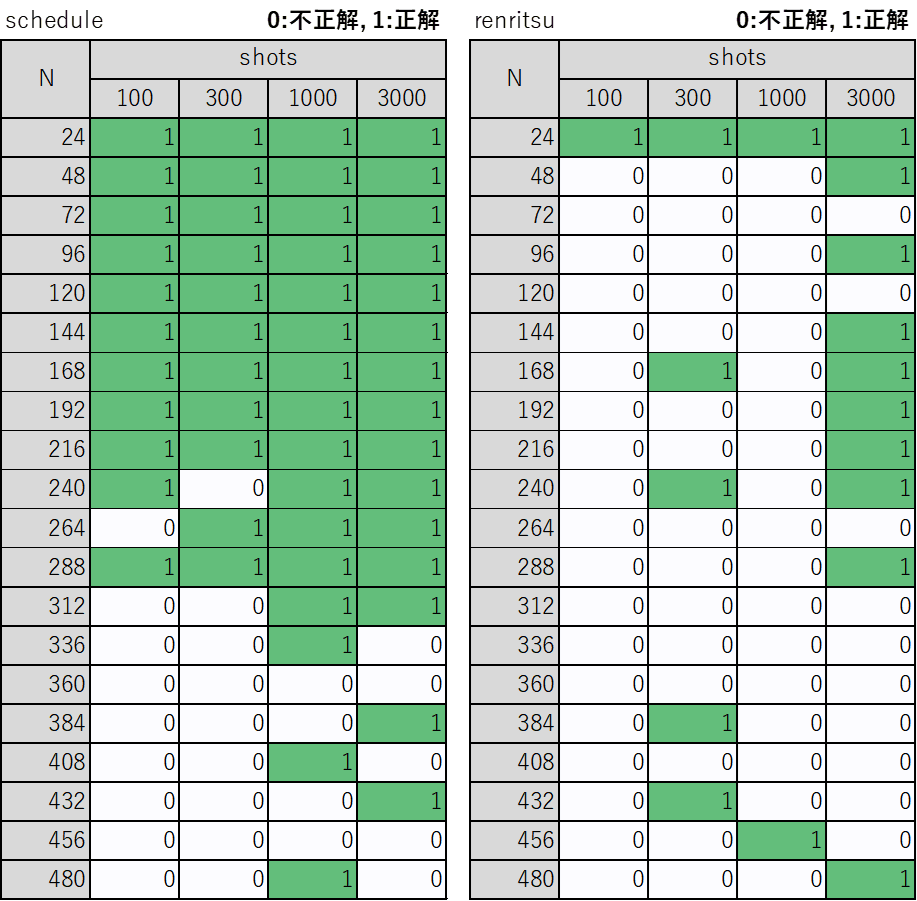
こちらも一発実験なのでざっくり見てください。問題が複雑になるほど正解率は下がり、shotsは大きいほど正解率が上がります。
ちなみに、他にアニーリングステップ数を意味する「T_num」という内部パラメータもあります(どこでも紹介していない)。これを大きくすることでよりゆっくりアニーリングすることになり、良い解が得られやすくなります。デフォルトは2000ステップ。
result = solver.run(qubo, shots=100, T_num=2000)複雑な問題ではこれも調整の余地があるかと思います。
おわりに
TYTANはチュートリアルと試験問題では100量子ビット程度までしか使用しません。業務で「もっと大規模にやりたいアルヨ~遅いヨ~」という方には各社が連携している有料ソルバーがありますので、気になる場合は問い合わせてみてください。