
AI要約
PythonのOCRライブラリを使い、『SPY×FAMILY謎解き』の画像から文字情報を抽出し謎解きに挑戦しました。Tesseractの設定や実行結果も詳細に解説しています。
やること
こんにちは、Suzuです ヾ(⌒(_๑˘ㅂ˘๑)_
前回、SPY×FAMILY(スパイファミリー)のたぬき暗号の記事を書きました。

今回も2020年9月の「SPY x FAMILY謎解き」キャンペーンに出てくる謎解き問題を解いてみました。謎解き問題の上級3、新聞の問題をOCR(光学文字認識)で解いてみました。光学文字認識(OCR)は、画像からテキストを抽出するプロセスのことを言います。
参考文献
① 『SPY×FAMILY謎解き』の問題はこちらをサイトからお借りしました。

② pyocrとTessreractによるOCRはこちらの記事を参考にさせていただきました。

③ その記事の中で、Tessreractのインストール方法はこちらを参考にするとよいと紹介されています。

④ Tesseractのパラメータ「layout」の選び方はこちらをご参照ください。

謎解き問題
謎解きは多段階になっていて、最終的に新聞の中から「O」「R」「D」「E」「R」(命令)の5文字を探すことになります。
その新聞がこちらです。

今回はOCRの勉強のため、不要な部分をマスクしたこちらの画像を入力として使用します。

準備
「pyocr」は「Tessreract」のラッパーのようなものらしいです。
参考文献③にしたがって「Tessreract」をインストールします。インストール時に日本語データにチェックを入れるのを忘れないようにします。インストールされたパスを調べておきます。私の場合、C:\Program Files\Tesseract-OCR でした。
また、Pythonの方で「pyocr」をpipします。
pip install pyocrpyocr が Tessreract を認識するか確認
pyocr が Tessreract を呼び出せるかを確認します。Tessreract のパスを一時的に追加して、pyocr が使用できるツール一覧に表示されるかを見ます。
import os
import pyocr
from copy import deepcopy
import matplotlib.pyplot as plt
from PIL import Image, ImageDraw
# tesseractのpathを一時的に追加
os.environ['PATH'] = 'C:\Program Files\Tesseract-OCR'
# pyocrからtesseractを使えることを確認
tools = pyocr.get_available_tools()
print(tools)
# tesseractを指定
tool = tools[0]
print(tool.get_name())[<module 'pyocr.tesseract' from 'C:\\Users\\aaa\\Desktop\\WPy64-31090\\python-3.10.9.amd64\\lib\\site-packages\\pyocr\\tesseract.py'>]
Tesseract (sh)Tesseract (sh) と表示されればOKです。
画像読み込み
入力画像をグレースケールで読み込みます。普段はOpenCVを使うことが多いのですが、pyocr がPILしか受け付けないというので仕方なくPILで開きます。
# 画像をグレースケールで読み込み
img = Image.open('a034_newspaper2.jpg').convert('L')
# 確認
plt.imshow(img)
plt.show()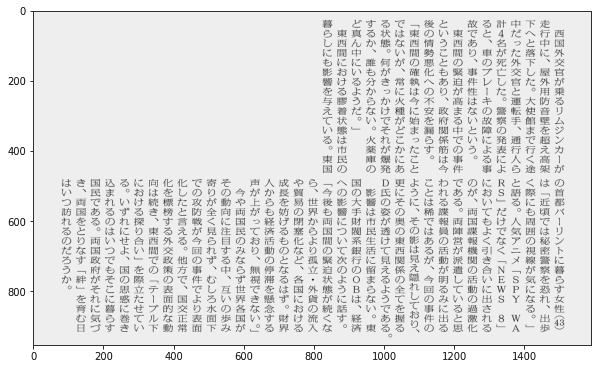
OCRの実行1
さっそくOCRを実行してみます。pyocr.builders.TextBuilder() は画像からテキストを抽出してくれます。
# OCRの設定 ※tesseract_layoutを調整すること。デフォルトは3
builder = pyocr.builders.TextBuilder(tesseract_layout=3)
# OCR
text = tool.image_to_string(img, lang='jpn', builder=builder)
# スペースを削除
text = text.replace(' ', '')
print(text)購岡玄相名骨0つく私慰一色G押旦々一ヘー勿公収幸③
掲中革/p計臣豆卸制対剛選字上6「央司6泡粗鋼時対悦だ^皇晶
に<く抑につお?表筐明人し選V鵜V是はめ凡加眉名馬4600?」
持8お康似血如面由/回選く4Q骨00?く上基ト中「のmnとほる
(中略)
約6選0QGSく0しMINJ人0
岡也し人約0?恒岡党也久居
交^恒岡納NQ6邊「工」対押紀四
6くの給選@QG和SNQO公文字化けしてる感じでうまく抽出できません。
これは「tesseract_layout=3」のパラメータが合っていないからです。参考文献④を見ながら(見てもよくわからないのですが)数字をいろいろ変えてみます。
builder = pyocr.builders.TextBuilder(tesseract_layout=4)暮ごどごするで一後と政る計中下走
ら東真る状は東のい東でと4だへ行西
し西んか上態な西情う西あ名っどと中国
に間中)“い間勢とこと問り車がだ沙に外
(中略)
をれに惑た1面国よろい界き懸ずに貨がにはなうてレのみいの出8Yなれ女
育に暮にせブ的交り水の各な念?おの続話^いでを避更にる過ごさきる性
むぶ気ら巻てルな正表面歩国いす財け流くす経-あ握め件出ど激れ8W82付
是づすきい下動常面下みがごる界る入な-済東るるへのる思化るA一歩ごお!「tesseract_layout=4」でなんとなく抽出できている気がします。ただし、横書きとして認識しているようです。
新聞は縦書きなので、きちんと縦書きで認識するように設定します。「lang=’jpn_vert’」に変更して、再びちょうどいい「tesseract_layout」を探していきます。
# OCRの設定 ※tesseract_layoutを調整すること。デフォルトは3
builder = pyocr.builders.TextBuilder(tesseract_layout=3)
#画像からOCRで日本語を読んで、文字列として取り出す
text = tool.image_to_string(img, lang='jpn_vert', builder=builder)
#スペースを削除
text = text.replace(' ', '')
print(text)西国外交官が乗るリムジンカーがの首都パーリントに暮らす女性(な)
走行中に、屋外用防音壁を超え高架は「近頃では秘密警察を届れ、出歩
下へと落下した。大使館まで行く<途<際にも周囲の視線が気になる。」
中だった外交官と運転手、通行人ろをと語る。人気アニメ[SPYWA
(中略)
込まれるのはいつでもそこに暮らす
国民である。両国取府がそれに気づ
き、両国をとりなす[「絆」を育む日
はいつ訪れるのだろうか。今度はデフォルトの「tesseract_layout=3」でうまくいきました!精度もまずまずじゃないでしょうか。「女性(43)」が「女性(な)」になっていたりしますが。
OCRの実行2
次に認識した文字の座標を活用する方法です。pyocr.builders.WordBoxBuilder() を使用するとテキストだけでなく、認識の信頼度、バウンディングボックスの左上と右下の座標も取得できます。
# OCRの設定 ※tesseract_layoutを調整すること。デフォルトは3
builder = pyocr.builders.WordBoxBuilder(tesseract_layout=3)
# OCR
results = tool.image_to_string(img, lang='jpn_vert', builder=builder)
# 認識したすべての文字を囲む
img_copy = img.copy()
draw = ImageDraw.Draw(img_copy)
for res in results:
#信頼度、文字、左上と右下の座標
print(res.confidence, res.content, res.position[0], res.position[1])
#矩形で囲む
draw.rectangle((res.position[0], res.position[1]), outline=0, width=5)
# 確認
plt.imshow(img_copy)
plt.show()96 西国 (1487, 56) (1515, 129)
86 外交 (1487, 138) (1515, 188)
86 官 (1488, 193) (1515, 215)
93 が (1487, 221) (1515, 243)
(中略)
96 だ (74, 685) (114, 708)
96 ろう (83, 708) (108, 751)
93 か (83, 756) (109, 773)
92 。 (99, 784) (110, 794)
これを見ると、1~4文字の塊で認識されていることがわかります。長いものは「見え隠れ」が4文字でした。
謎解き
いよいよ、ORDERの5文字がどこにあるか囲ってみましょう。
# OCRの設定 ※tesseract_layoutを調整すること。デフォルトは3
builder = pyocr.builders.WordBoxBuilder(tesseract_layout=3)
# OCR
results = tool.image_to_string(img, lang='jpn_vert', builder=builder)
# ORDERを囲む
img_copy = img.copy()
draw = ImageDraw.Draw(img_copy)
pos = []
for l in ['O', 'R', 'D', 'E', 'R']:
for res in results:
if l in res.content:
#矩形で囲む
draw.rectangle((res.position[0], res.position[1]), outline=0, width=5)
#座標を記録
pos.append(res.position[0])
print(pos)
# 確認
plt.imshow(img_copy)
plt.show()[(899, 787), (1314, 501), (982, 496), (1314, 679), (1314, 501)]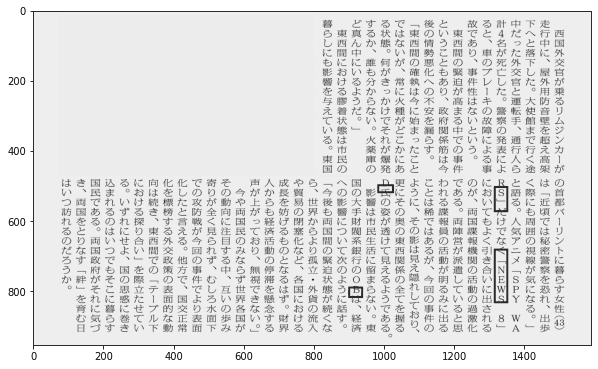
アルファベットは認識座標が少しずれるようです。なぜでしょうか・・・。2つの「R」は同じ座標ですね。
ORDERの順に線で繋いでみます。
# ORDERの順で結ぶ
img_copy = img.copy()
draw = ImageDraw.Draw(img_copy)
draw.line(pos, fill=0, width=5)
plt.imshow(img_copy)
plt.show()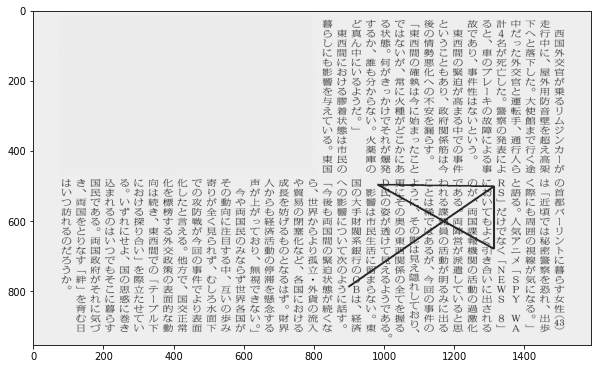
大きな矢印が表れました!!矢印の方向にあるテキストを読むと、「らくえン(楽園)」のキーワードが見つかりました!
さいごに
今回はOCRの威力を確認することができました。新聞はフォントもレイアウトも整っているのでもっとも認識が簡単だと思います。手書きの手紙だとAIを使った認識が必要になるかもしれません。
ここまで記事を読んでいただきありがとうございました。Qiitaとnoteもやっていますのでフォローお願いします!
Qiita

note
