 画像生成AI / スタイル変換
画像生成AI / スタイル変換 4-19. アプリ版DALL-EとAPI版DALL-Eを比較してみた(まとめ)
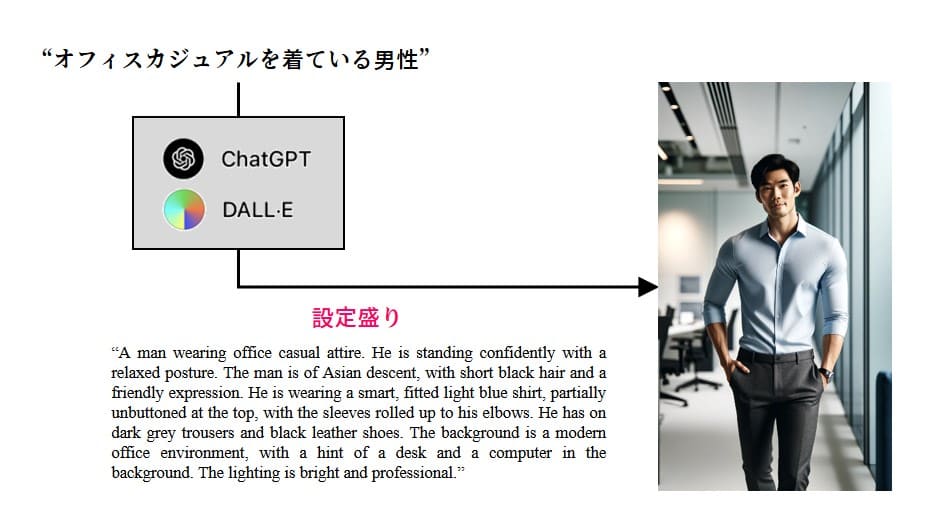
やることはじめまして、Yoshimotoです ( ˘ω ˘ *)ウッス今月上旬、OpenAIは画像生成のAPI「DALL-E 2」のアップデート版である「DALL-E 3」を公開しました。同じく、Ch...
2023/11/19

画像生成AI / スタイル変換