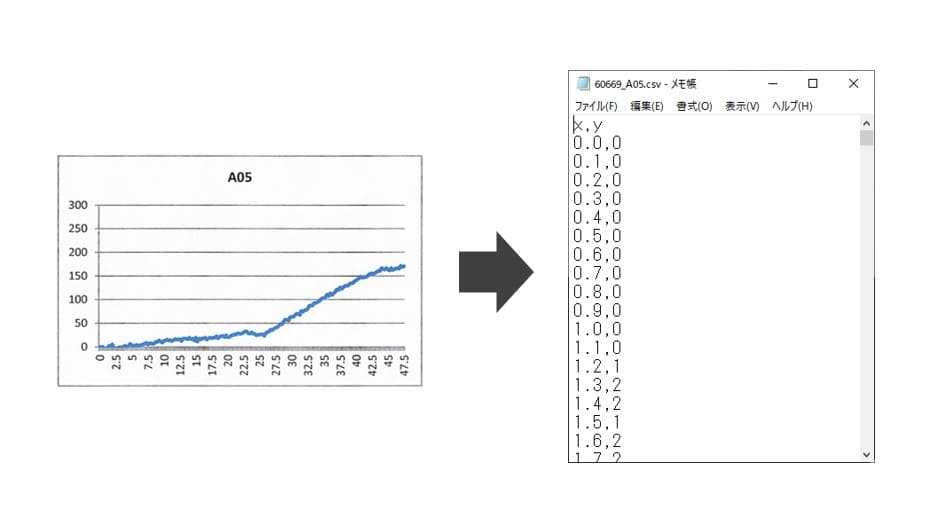
やること
自治体さんから緊急の依頼がありました。PDFで保存さているグラフ画像を大至急、数値データに戻してほしいとのことです。こんな感じのPDF画像が大量に送られてきました (゚д゚; )アレマー
古典的な画像処理でリバースエンジニアリングできますので手順を紹介します。Python(+OpenCV)とImageJを使用しました。
傾きの修正
まず、画像全体の傾きを修正します。OpenCVで直線を検出して、傾きが直るように回転させます。

今回はスキャナで取り込まれた画像なので台形補正などは不要でした。もしカメラで撮った写真だったりすると台形補正や明るさの調整も必要になります。
グラフ領域の抽出、線の抽出
グラフの枠線や軸の数字を検出してグラフ領域を抽出します。Excelのグラフらしく右側に枠線がありません。ミスを防ぐために右側に余白を残しました。(うっかり削り込んでしまっても気が付けないので)
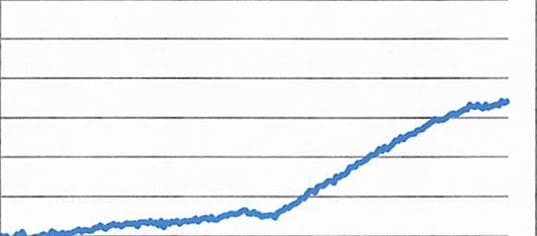
青色を検出して二値化します。
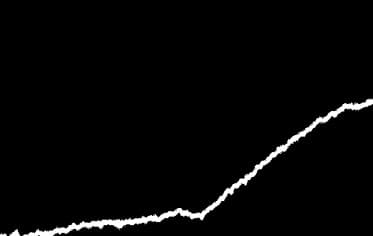
そのまま次のステップに進んでも良いのですが、ここではエッジ検出を適用して線の上部と下部をあぶり出しました。
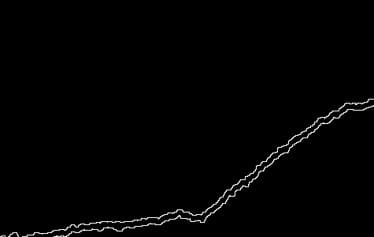
今回のグラフは横軸が0~47.5、縦軸が0~300の範囲で揃っています(やりやすくて助かりますね)。これを考慮してこの時点の画像サイズを (475, 300) に調整してあります。この後の処理が単純になります。
値の抽出
上部と下部の中間の値を読み取ります。
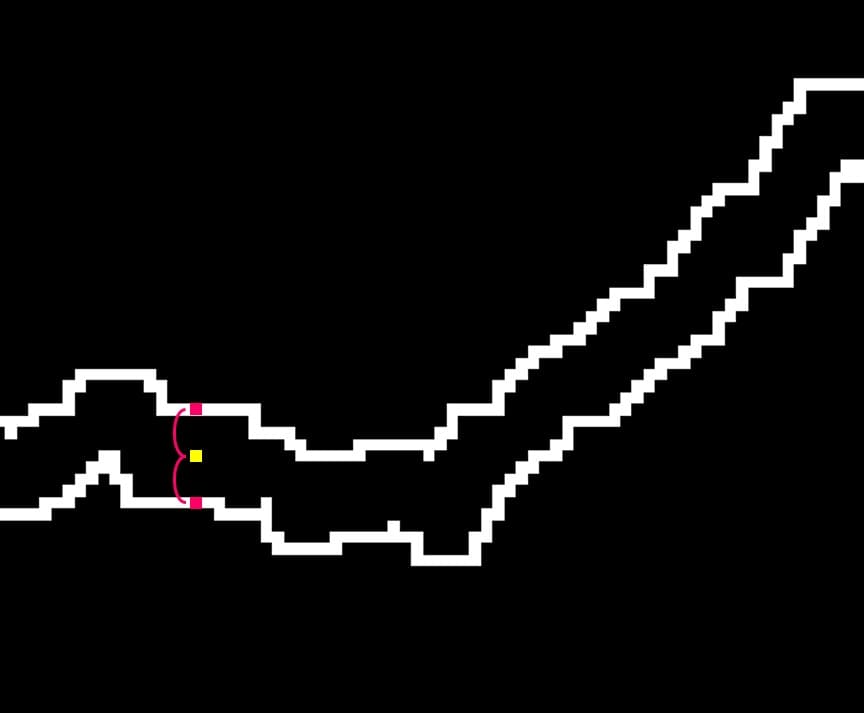
個別のcsvファイルに保存していきます。全部で1100個のデータファイルができました。この量は手動では不可能ですね。
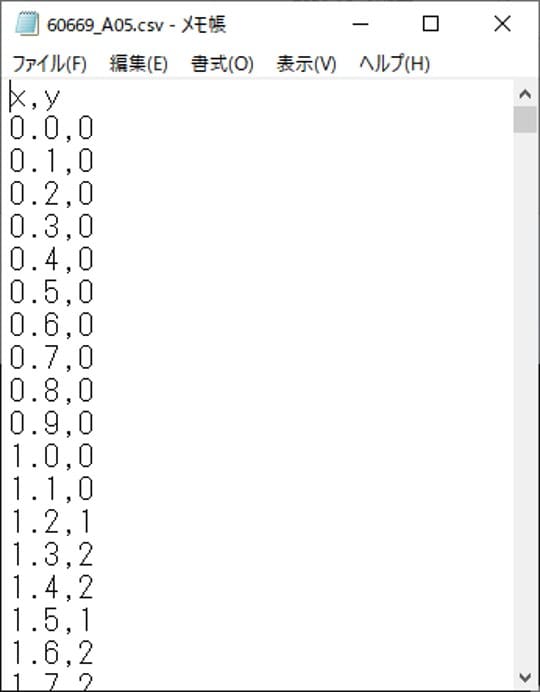
以上で処理は終了です。
データの確認
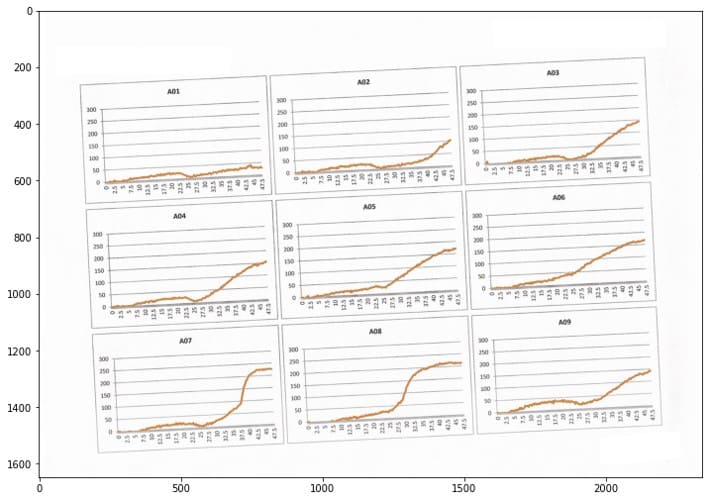
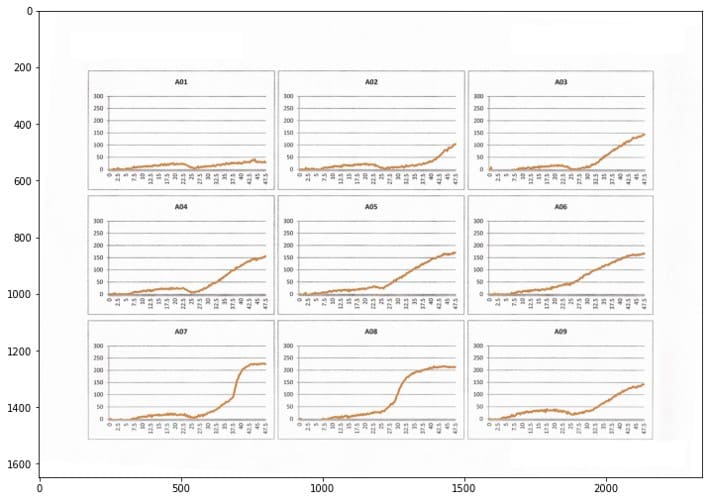
抽出したデータと元のグラフ画像を重ねて精度を確認してみます。赤線が今回抽出したデータ(をExcelでグラフにしたもの)です。
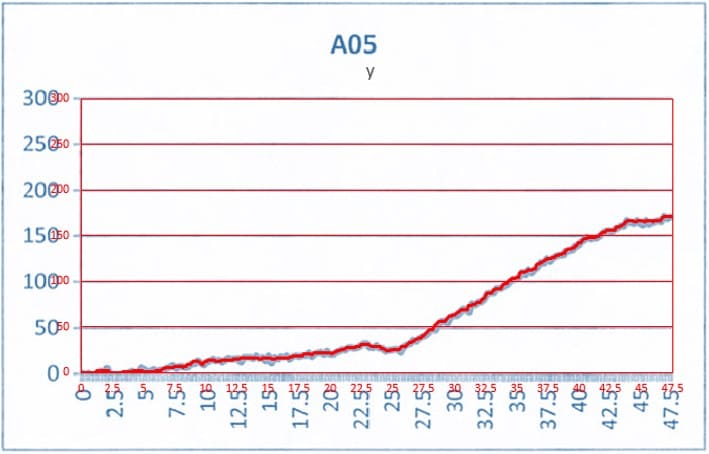
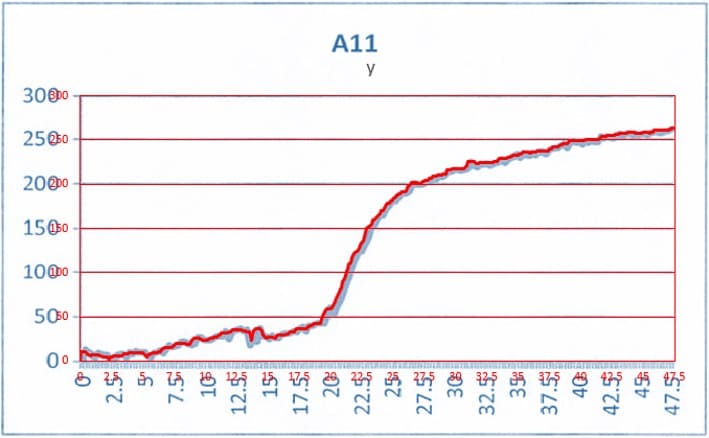
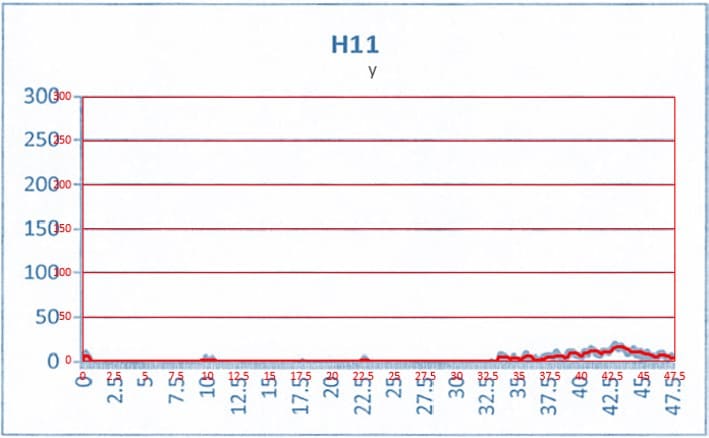
良さそうですね!y=0付近の値は埋もれがちなので慎重に抽出しました。
もちろん完全な復元はできません。どうしても少し丸まってしまいます。要求される精度によっては途中の工程が2倍にも3倍にも増えそうです。
おわりに
グラフ画像のリバースエンジニアリングができました。
企業や自治体に眠っている「データ化されていない」データがあればお気軽にご相談ください。