やること
画像というものは非常に高次元の情報を持っています。例えば128*128pxの画像は、128*128*3ch=49152次元の情報を含んでいます。人間は高次元の情報を処理できない動物なので、2~3次元くらいにまで情報を圧縮もしくは削減する必要があります。今日は、CNNでケーキ画像の次元圧縮をしてみましょう。
使うもの
Google Colaboratoryが利用可能です。


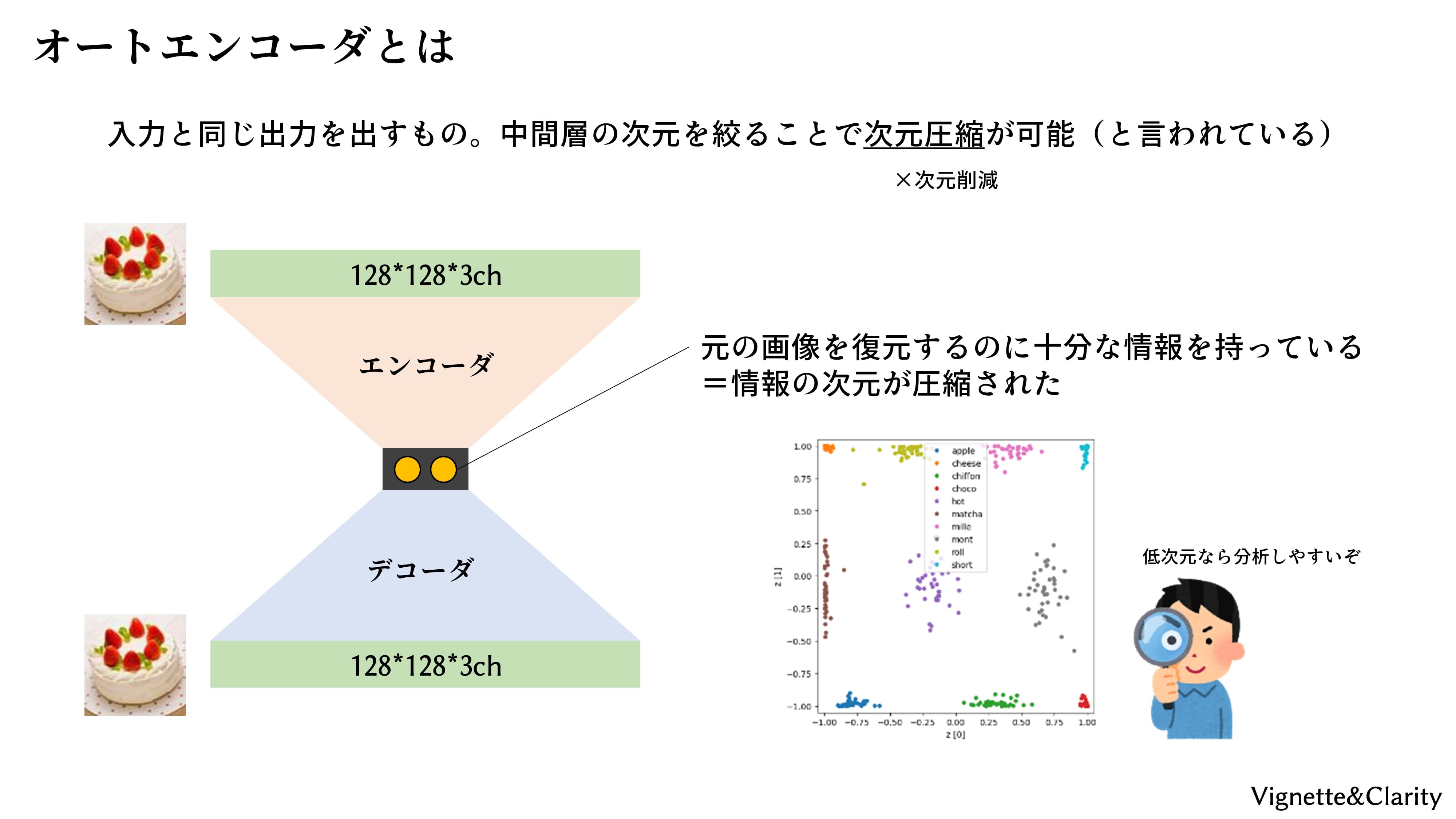
オートエンコーダとは
オートは「自分自身」、エンコーダは「変換器」です。オートエンコーダは、入力と同じ出力を出す変換器のことです。「意味なくない?」と思ってしまいますが、変換の途中で情報の通り道を絞ることで、情報の次元圧縮ができます。ニューラルネットを用いたオートエンコーダは、砂時計型のモデルです。すなわち、前半は畳み込みによって2次元まで圧縮し(エンコーダと呼ぶ)、後半はアップサンプリングによって元の画像サイズまで展開します(デコーダと呼ぶ)。
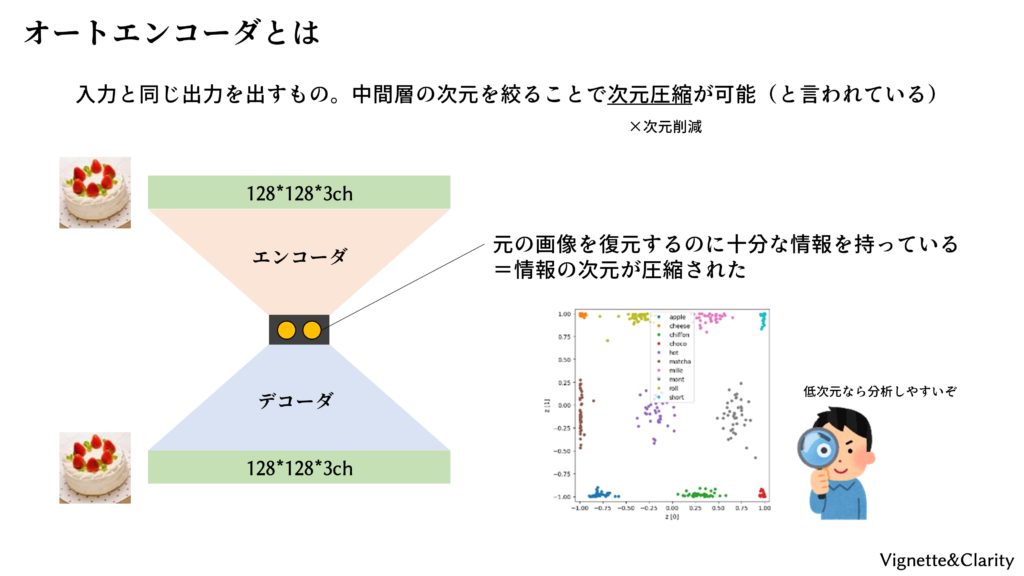
ニューラルネットモデル
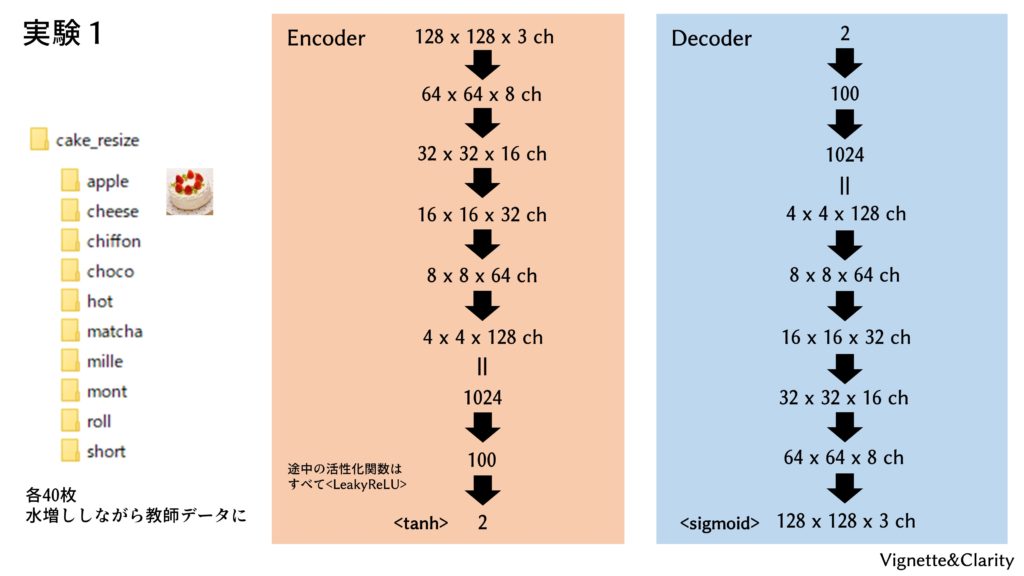
1-3, 1-4で用意した、10種のケーキの画像(計400枚)を用います。オートエンコーダは教師なし学習ですので、学習には「apple」「cheese」といった教師ラベルは用いません。
プログラムを実行する
配布された「autoencoder_1.py」を実行すると、「cake_AE1_para/」フォルダが生成され、1エポックごとに重みとバイアスが保存されます。学習は、1-4で言及した、Kerasの「フォルダから画像を読み込みながら(リサイズはしないけど)水増ししながら正解ラベル(この場合は入力と同じ画像)を作りながら学習する」という必殺技を存分に使用していますので、コードは比較的短くシンプルです。
結果
1エポックごとに、規定のケーキ画像10枚を用いて、オートエンコーダの性能確認をしています。しかし、さすがに「2次元」は絞りすぎたのでしょう。情報を入力画像をほとんど復元できていません。つまり、オートなエンコードができませんでした。
