やること
オートエンコーダでお寿司の画像を学習してみます。
使うもの
Google Colaboratoryが利用可能です。

Google Colab
colab.research.google.com
WinPython3.6をおすすめしています。

WinPython - Browse /WinPython_3.6/3.6.7.0 at SourceForge.net
Portable Scientific Python 2/3 32/64bit Distribution for Windows
sourceforge.net
こちらの勉強会を参考にしています。

AIワークショップ|初心者だけどCNNで次元圧縮できちゃった (2019/02/25 19:00〜)
# 「そうだ、次元を圧縮しよう」 中高生のなりたい職業ランキング1位「次元圧縮師」(大きな声で嘘をつく) ## オンラインコミュニティ 情報交換・質問・クレームなどはAI FASHIONのSlack(...
aifashion.connpass.com

AI勉強会|GANやVAEが書けるようになりたい (2019/10/11 19:30〜)
## 久しぶりに本郷で開催します こちらがライブ配信のアーカイブ動画です。 ## 参加方法 抽選や承認はありませんので、好き勝手にお越しください。 ## オンラインコミュニティ 情報交換・質問・クレー...
aifashion.connpass.com
画像のサイズ(解像度)を揃える
お寿司の画像を「osushi」フォルダに集めて、プログラムを用いて128*128サイズに揃えて、「osushi_resize」フォルダに保存します。
# -*- coding: utf-8 -*-
import os
from PIL import Image
import numpy as np
#パラメータ
#======================================
#画像を保存してあるフォルダ名
f = 'osushi/'
#リサイズした画像を保存するフォルダ名
f_resize = 'osushi_resize/'
#リサイズ後のサイズ
size = 128
#======================================
#処理
#======================================
if not os.path.isdir(f_resize):
os.makedirs(f_resize)
files = os.listdir(f)
for file in files:
img = Image.open(f + file).convert("RGBA"); img.close
tmp = np.array(img)
mask = tmp[:,:,3] < 240
tmp[mask, 0] = 255
tmp[mask, 1] = 255
tmp[mask, 2] = 255
img = Image.fromarray(tmp[:,:,0:3])
width, height = img.size
if width == height:
tmp = img
elif width > height:
tmp = Image.new('RGB', (width, width), (255, 255, 255))
tmp.paste(img, (0, (width - height) // 2))
else:
tmp = Image.new('RGB', (height, height), (255, 255, 255))
tmp.paste(img, ((height - width) // 2, 0))
img_resize = tmp.resize((size, size), Image.BICUBIC)
img_resize.save(f_resize + file)
print("リサイズ完了")
print()
#======================================リサイズ後のお寿司画像(.zip)をこちらに置いておきます。展開して用いてください。
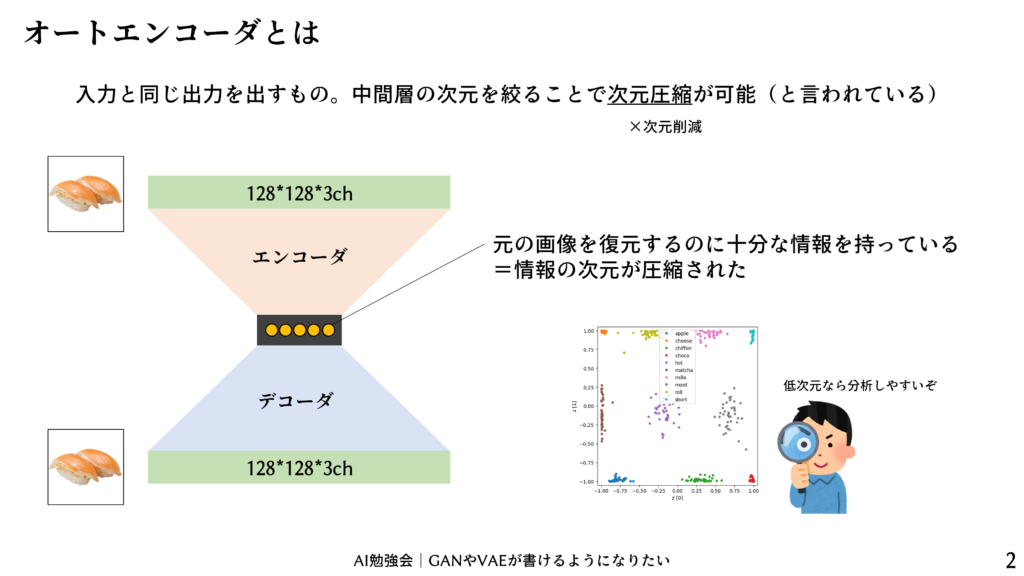
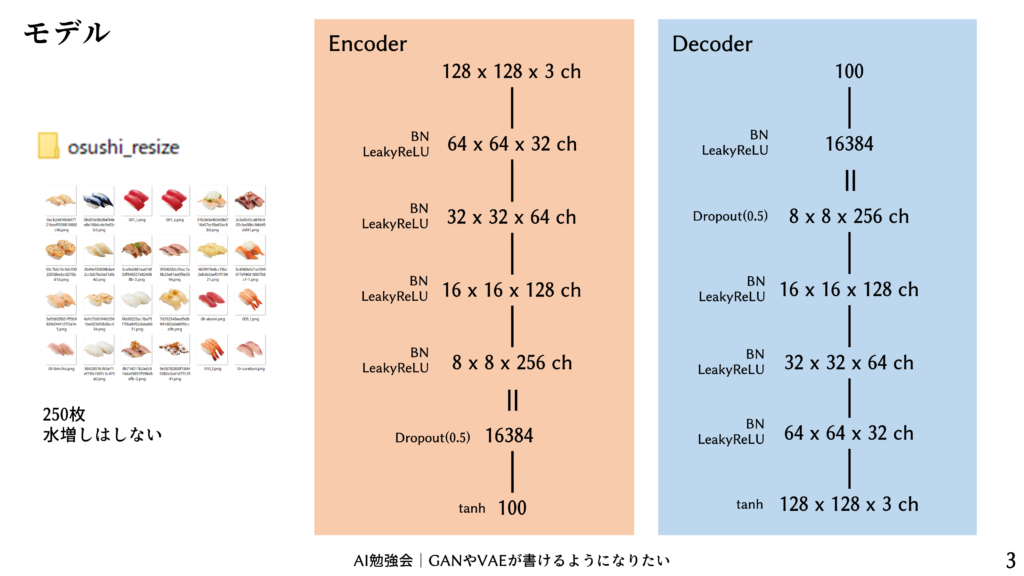
エンコーダとデコーダのモデル
こちらのモデルにしました。潜在変数は100次元に設定しました。
プログラムを実行する
オートエンコーダのほぼ最小コードではないかと思います。自動的に「AE_img」フォルダが生成され、10エポック毎に確認用の画像が保存されます。また、「AE_para」フォルダも生成され、50エポック毎にエンコーダとデコーダの重みが保存されます。2-3のDCGANに比べれば非常に速く学習は進みます。
import os
import numpy as np
from PIL import Image
from copy import deepcopy
import matplotlib.pyplot as plt
import keras
from keras.models import Sequential
from keras.layers import Dense, Conv2D, BatchNormalization, Conv2DTranspose, Activation, Flatten, Dropout, Reshape, GlobalAveragePooling2D, MaxPooling2D
from keras.layers.advanced_activations import LeakyReLU
from keras.preprocessing.image import ImageDataGenerator
from keras.models import load_model
from keras.callbacks import EarlyStopping
#パラメータ
#======================================
#教師画像の親フォルダ
f = 'osushi_resize/'
#ミニバッチサイズ(教師データ数の公約数にしてください)
batch_size = 40
#乱数列の次元
z_dim = 100
#discriminatorの学習率
opt = keras.optimizers.Adam(lr=0.0002)
#画像を保存するフォルダ
img_f = 'AE_img/'
#重みを保存するフォルダ
para_f = 'AE_para/'
#======================================
#教師データ読み込み
#======================================
x_train = []
files = os.listdir(f)
for file in files:
img = Image.open(f + file).convert("RGB"); img.close
x_train.append(np.array(img))
x_train = np.array(x_train)
#-1~+1に規格化
x_train = (x_train - 127.5) / 127.5
#確認用に手前の10枚を隔離
x_check = deepcopy(x_train[:10])
x_train = x_train[10:]
#入力と出力は同じですよ
y_train = x_train
print('枚数, たて, よこ, チャンネル')
print(x_train.shape)
#======================================
#モデルの定義
#======================================
def encoder_model():
model = Sequential()
#128*128*3ch → 64*64*32chにたたむ
model.add(Conv2D(32, (4, 4), strides=(2, 2), padding='same', input_shape=(128, 128, 3)))
model.add(BatchNormalization())
model.add(LeakyReLU())
#64*64*32ch → 32*32*64chにたたむ
model.add(Conv2D(64, (4, 4), strides=(2, 2), padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
#32*32*64ch → 16*16*128chにたたむ
model.add(Conv2D(128, (4, 4), strides=(2, 2), padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
#16*16*128ch → 8*8*256chにたたむ
model.add(Conv2D(256, (4, 4), strides=(2, 2), padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
#フラットに伸ばして
model.add(Flatten())
model.add(Dropout(0.5))
#100次元まで圧縮
model.add(Dense(z_dim))
model.add(Activation('tanh'))
return model
def decoder_model():
model = Sequential()
#100次元 → 8*8*256=16384次元に展開
model.add(Dense(8*8*256, input_shape=(z_dim, )))
model.add(BatchNormalization())
model.add(LeakyReLU())
#8*8*256chに変形
model.add(Reshape((8, 8, 256)))
model.add(Dropout(0.5))
#8*8*256ch → 16*16*128chにアップ
model.add(Conv2DTranspose(128, (4, 4), strides=(2, 2), padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
#16*16*128ch → 32*32*64chにアップ
model.add(Conv2DTranspose(64, (4, 4), strides=(2, 2), padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
#32*32*64ch → 64*64*32chにアップ
model.add(Conv2DTranspose(32, (4, 4), strides=(2, 2), padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
#64*64*32ch → 128*128*3chにアップ
model.add(Conv2DTranspose(3, (4, 4), strides=(2, 2), padding='same'))
model.add(Activation('tanh'))
return model
def autoencoder_model(encoder, decoder):
model = Sequential()
model.add(encoder)
model.add(decoder)
return model
#======================================
#モデルの生成
#======================================
#encoderの生成
encoder = encoder_model()
encoder.summary()
#decoderの生成
decoder = decoder_model()
decoder.summary()
#autoencoderの作成
autoencoder = autoencoder_model(encoder, decoder)
autoencoder.summary()
#autoencoderのコンパイル
autoencoder.compile(loss='msle', optimizer=opt)
#======================================
#保存用フォルダ作成
if not os.path.isdir(para_f):
os.makedirs(para_f)
if not os.path.isdir(img_f):
os.makedirs(img_f)
#学習中のログ
#======================================
class EpisodeLogger(keras.callbacks.Callback):
def on_epoch_begin(self, epoch, logs={}):
#一定epoch毎に画像表示
if epoch % 10 == 0:
#======================================
x_ans = autoencoder.predict(x_check)
stack1 = np.concatenate(x_check, axis=1)
stack2 = np.concatenate(x_ans, axis=1)
stack3 = np.concatenate([stack1, stack2], axis=0)
img = Image.fromarray(np.uint8(stack3 * 127.5 + 127.5))
plt.figure(figsize=(10, 10))
img.save(img_f + str(epoch) + '.png')
plt.imshow(img, vmin = 0, vmax = 255)
plt.show()
#======================================
#一定epoch毎に重みを保存
if epoch % 50 == 0:
#重みの保存
encoder.save(para_f + 'encoder_' + str(epoch) + '.h5')
decoder.save(para_f + 'decoder_' + str(epoch) + '.h5')
#======================================
#学習
hist = autoencoder.fit(x_train, y_train, epochs=30000, batch_size=batch_size, verbose=2, callbacks=[EpisodeLogger()])結果
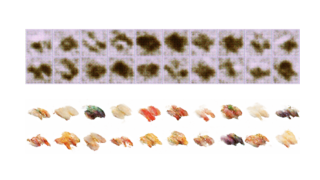
10個のお寿司(学習には使っていない)と、それをオートエンコーダに通した画像が表示されます。0エポックではグレーの画像しか出力しませんが、だんだんお寿司が出てきます。500エポックまで学習してみました。
入力と同じ出力になるように学習していますが、ちょっとぼやける感じがします。限られた潜在空間で多様なお寿司を生成しようとすると、どうしても平均的なところを取らざるを得ないのでしょう。