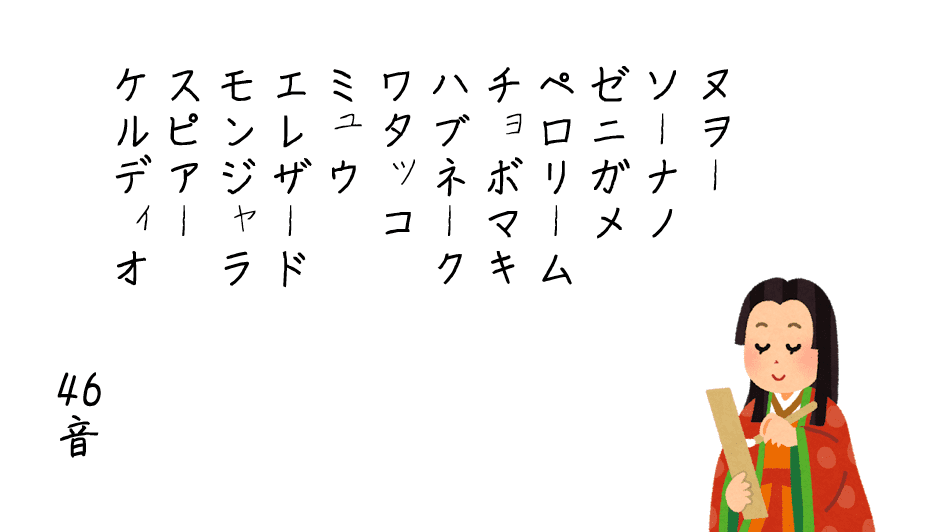やること
「いろは歌」は組合せ最適化問題であり、「いろはにほヘと」で始まるものが有名です。ここでは、vcoptを使ってポケモンで「いろは歌」に挑戦します。
実行環境
WinPython3.6をおすすめしています。

vcoptの使い方についてはチュートリアルをご参照ください。

vcoptの仕様については最新の仕様書をご参照ください。本記事執筆時とは仕様が異なる場合があります。

ポケモンのデータベース
前回に引き続き、ポケモンのデータベースはこちらを使わせていただきました。
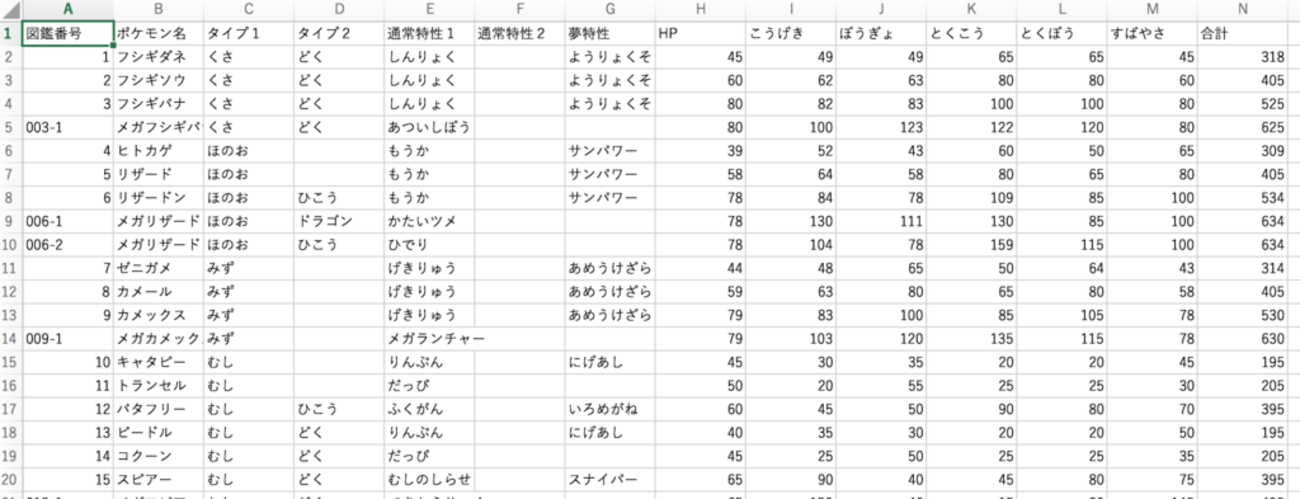
データの整形を行います。
- メガとアローラは除外する
- フォルム名は取り除く(デオキシスN→デオキシス、ニャオニクス♂→ニャオニクス、ジガルデ10%→ジガルデ)
- 記号は読み方に変換する(ニドラン♂→ニドランオス、ポリゴンZ→ポリゴンゼット)
整形後のcsvをこちらに置いておきます。(著作権は上記リンク主にありますのでご注意を)
他にもプログラム中でデータ整形を行いますが、それは後ほど説明します。
import
まず、今回使うパッケージをインポートします。
import copy
import numpy as np
import matplotlib.pyplot as plt
from vcopt import vcopt全ポケモン名の読み込み
上の「pokemon_status_2.csv」の全行、2列目を読み込みます。
#============================
#全ポケモンデータの読み込み
#============================
#ファイル名
file = open('pokemon_status_2.csv', 'r')
#
data = []
#1行目はラベルなのでカラ読み
file.readline()
#2行目以降のポケモン名だけを読み込む
while 1:
tmp = file.readline().split(',')
if len(tmp) > 1:
data.append(tmp[1])
else:
break
file.close()
#コピーしておく
data_save = copy.deepcopy(data)
print('ポケモンの数:{}'.format(len(data)))
print('最初の4匹:{}'.format(data[:4]))ポケモンの数:802
最初の4匹:['フシギダネ', 'フシギソウ', 'フシギバナ', 'ヒトカゲ']メガとアローラを除いたポケモン数は802匹でした。
データの整形
以下の整形を行います。
- 小さい字は大きくする(コラッタ→コラツタ)
- 濁点、半濁点を解消する(カビゴン→カヒコン)
- 長音を削除する(イワーク→イワク)
- 同じ文字を2回以上使っているポケモンは除外(タマタマ等)
#============================
#データの整形
#============================
#配列の要素を削除するときは逆順で処理しないと大変なことになります
for i in range(len(data)-1, -1, -1):
#小さい字を大きくする
tmp = [('ァ', 'ア'), ('ィ', 'イ'), ('ゥ', 'ウ'), ('ェ', 'エ'), ('ォ', 'オ'),
('ャ', 'ヤ'), ('ュ', 'ユ'), ('ョ', 'ヨ'), ('ッ', 'ツ')]
for s in tmp:
data[i] = data[i].replace(s[0], s[1])
#濁点、半濁点を戻す
tmp = [('ガ', 'カ'), ('ギ', 'キ'), ('グ', 'ク'), ('ゲ', 'ケ'), ('ゴ', 'コ'),
('ザ', 'サ'), ('ジ', 'シ'), ('ズ', 'ス'), ('ゼ', 'セ'), ('ゾ', 'ソ'),
('ダ', 'タ'), ('ヂ', 'チ'), ('ヅ', 'ツ'), ('デ', 'テ'), ('ド', 'ト'),
('バ', 'ハ'), ('ビ', 'ヒ'), ('ブ', 'フ'), ('ベ', 'ヘ'), ('ボ', 'ホ'),
('パ', 'ハ'), ('ピ', 'ヒ'), ('プ', 'フ'), ('ペ', 'ヘ'), ('ポ', 'ホ'),
('ヴ', 'ウ')]
for s in tmp:
data[i] = data[i].replace(s[0], s[1])
#長音を削除
data[i] = data[i].replace('ー', '')
#同じ文字を2回以上使っているポケモンは削除
if len(data[i]) != len(set(data[i])):
data.pop(i)
data_save.pop(i)
print('ポケモンの数:{}'.format(len(data)))
print('途中の8匹:{}'.format(data[9:17]))ポケモンの数:643
途中の4匹:['キヤタヒ', 'トランセル', 'ハタフリ', 'ヒトル', 'コクン', 'スヒア', 'ヒシヨン', 'ヒシヨツト']同じ音を2回以上使っているポケモンを除くと643匹でした。途中の8匹を確認すると、キャタピーが「キヤタヒ」になっていますし、ポッポ(というかホツホ)が除外されているので、うまく処理できていることが分かります。
(必須)評価関数
ポケモンIDが並んだparaを受け取って、ポケモン名に変換した後、アイウエオ表と照合します。アイウエオ表は「ア~ン」までの46音です。ヲはオとましたので、オが2つあります。ここからポケモン名を一文字一文字引いていき、アイウエオ表になければペナルティ1点、また、最後までアイウエオ表に残った文字数もペナルティとします。要するに、46音に満たなければペナルティ、重複してもペナルティということです。
最適化は、このペナルティが0に近づくように行います(=過不足がなくなるよう)。
#評価関数
def iroha_score(para):
#いろは一覧をパラパラにリストに
iroha = list('アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワオン')
#paraのポケモン名を直列して、バラバラにリストに
name = ''
for p in para:
name += data[p]
name = list(name)
#スコア計算
score = 0
for s in name:
#irohaにあればirohaから削除する、irohaになければペナルティ
if s in iroha:
iroha.remove(s)
else:
score -= 1
#irohaに残ってる字数はペナルティ
score -= len(iroha)
#スコアを返す
return score
print(data[10], data[4])
print(iroha_score([10, 4]))トランセル リサト
-40試しにpara=[10, 4]を入力してみると、ペナルティ40が返ってきました。「トランセルリサト」ですから、7音使用し、1音重複しています。スコアは-46+7-1=-40ですので合っています。
(任意)すべてのパラメータ群を可視化する関数
poolを受け取って、全員のスコアを計算し、棒グラフで表示します。
#poolの可視化
def iroha_show_pool(pool, **info):
#任意で次の変数が使用できます
gen = info['gen']
best_index = info['best_index']
best_score = info['best_score']
mean_score = info['mean_score']
#mean_gap = info['mean_gap']
time = info['time']
#pool全員のスコアを計算
scores = []
for i in range(len(pool[:100])):
scores.append(iroha_score(pool[i]))
#プロット
plt.figure(figsize=(6, 6))
plt.bar(range(len(pool[:100])), scores)
plt.ylim([-40, 0])
plt.title('gen={} best={} mean={} time={}'.format(gen, best_score, mean_score, time))
#plt.savefig('save/{}.png'.format(gen))
plt.show()
print()GAで最適化(643匹)
とりあえず643匹でやってみましょう。setGA()が使えるところですが、選択肢に対して極端に選ぶ個数が少ない場合は、重複する確率が低いこともあり、dcGA()の方が良いようです。選ぶポケモンの数は12~13匹がちょうど良いようですので、どちらも試してみました。
#パラメータ範囲
para_range = [[i for i in range(0, len(data))] for j in range(13)]
#GAで最適化
para, score = vcopt().dcGA(para_range, #para_range
iroha_score, #score_func
0.0, #aim
show_pool_func=iroha_show_pool, #show_para_func=None
seed=None, #seed=None
pool_num=5000)
#結果の表示
print(para)
print(score)
#ポケモンを表示
for p in para:
print(data_save[p], end=' ')
print()
#多かった音、足りなかった音を表示
iroha = list('アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワオン')
name = ''
for p in para:
name += data[p]
name = list(name)
print('多かった文字')
for s in name:
if s in iroha:
iroha.remove(s)
else:
print(s)
print('足りなかった文字')
print(iroha)実行結果
[204 243 581 421 471 625 365 87 418 53 157 431 45]
-2.0
セレビィ エネコ クレベース ミジュマル アーケン メテノ ウソハチ サワムラー ポカブ ニョロモ ヌオー ヤナッキー ダグトリオ
多かった文字
レ
ク
足りなかった文字
[]レ・クの2音が重複してしまいました、惜しい感じです。いろいろ頑張っても、スコア-4~-2くらいにしかなりませんでした。
ちょっと工夫する
さて、643匹の「46音の使用数」をカウントしてみます。
#============================
#各音の使用数カウント
#============================
#カウント数0で初期化
d = {}
for key in list('アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワオン'):
d[key] = 0
#カウント
for name in data:
for onn in list(name):
d[onn] += 1
#使用数が少ない順にソートして表示
d = sorted(d.items(), key=lambda x:x[1])
print(d)[('ヌ', 10), ('ソ', 15), ('セ', 16), ('ヘ', 19), ('ヨ', 20), ('ネ', 21), ('ワ', 21), ('ミ', 22), ('サ', 31), ('モ', 31), ('ノ', 32), ('ケ', 34), ('メ', 34), ('エ', 35), ('ウ', 37), ('ム', 40), ('レ', 40), ('ナ', 41), ('ユ', 42), ('ニ', 43), ('ホ', 44), ('チ', 45), ('ヒ', 48), ('オ', 51), ('テ', 53), ('ヤ', 53), ('ロ', 62), ('ア', 63), ('キ', 69), ('タ', 71), ('マ', 71), ('リ', 81), ('カ', 84), ('コ', 90), ('ハ', 90), ('イ', 95), ('ツ', 95), ('フ', 98), ('シ', 101), ('ラ', 101), ('ス', 112), ('ク', 114), ('ト', 126), ('ル', 134), ('ン', 162)]「ヌ」は10匹しか持っていないようです。
さらに、ヌ・ソ・セ・ヘをもつポケモンを列挙してみます。
#============================
#使用数ワースト4文字を使っているポケモン
#============================
for onn in ['ヌ', 'ソ', 'セ', 'ヘ']:
print('###「{}」を含むポケモン'.format(onn))
for name in data:
if onn in name:
print(name, end=',')
print()###「ヌ」を含むポケモン
ヌオ,クヌキタマ,ヌマクロ,ヌケニン,ヌメラ,ヌメイル,ヌメルコン,アシレヌ,ヌイコクマ,タイフヌル,
###「ソ」を含むポケモン
フシキソウ,ナソノクサ,ニヨロソ,ウソツキ,ソナンス,コマソウ,ケムツソ,ソルロツク,アフソル,ソナノ,ウソハチ,ソロア,ソロアク,コソクムシ,ソルカレオ,
###「セ」を含むポケモン
セニカメ,トランセル,ハラセクト,ハリセン,セレヒイ,イルミセ,ロセリア,フイセル,フロセル,ホリコンセツト,クレセリア,アルセウス,セフライカ,セクロム,ケノセクト,セルネアス,
###「ヘ」を含むポケモン
ヘルシアン,ヘロリンカ,ヘイリフ,ヘラクロス,ヘルカ,ヘリツハ,ヘイカニ,シユヘツタ,タツヘイ,エンヘルト,ヘラツフ,コンヘ,ヘントラ,オヘム,ツンヘア,シヘツト,ヘロツハフ,ヘロリム,クレヘス,実は、ヌをもつポケモンはソ・セ・ヘを持っていませんし、他も同様で、完全に独立です。ということは、いろは歌に12~13匹を選びますが、内4スロットはそれぞれヌ・ソ・セ・ヘのポケモン専用にすることができます。
ただ、もう少し簡単にしたいので、使用数ワースト10文字に専用スロットを用意してあげることにします。10文字はほぼ独立と考えましょう。
10文字それぞれをもつポケモンのインデックスを抽出し、いずれにも当てはまらないポケモンはindex_othersに押し込みます。
#============================
#使用数ワースト10文字をもつポケモンのインデックス
#============================
index_nu = []
index_so = []
index_se = []
index_he = []
index_yo = []
index_ne = []
index_wa = []
index_mi = []
index_sa = []
index_mo = []
index_others = []
for i in range(len(data)):
flag = False
if 'ヌ' in data[i]:
index_nu.append(i)
flag = True
if 'ソ' in data[i]:
index_so.append(i)
flag = True
if 'セ' in data[i]:
index_se.append(i)
flag = True
if 'ヘ' in data[i]:
index_he.append(i)
flag = True
if 'ヨ' in data[i]:
index_yo.append(i)
flag = True
if 'ネ' in data[i]:
index_ne.append(i)
flag = True
if 'ワ' in data[i]:
index_wa.append(i)
flag = True
if 'ミ' in data[i]:
index_mi.append(i)
flag = True
if 'サ' in data[i]:
index_sa.append(i)
flag = True
if 'モ' in data[i]:
index_mo.append(i)
flag = True
if flag == False:
index_others.append(i)GAで最適化(工夫)
12匹のスロットのうち、手前の10スロットは、ワースト10文字をもつポケモンの専用スロットとします。残りの2スロットはその他のポケモンで調整してもらいます。
#パラメータ範囲
para_range = [index_others for j in range(12)]
para_range[0] = index_nu
para_range[1] = index_so
para_range[2] = index_se
para_range[3] = index_he
para_range[4] = index_yo
para_range[5] = index_ne
para_range[6] = index_wa
para_range[7] = index_mi
para_range[8] = index_sa
para_range[9] = index_mo
#GAで最適化
para, score = vcopt().dcGA(para_range, #para_range
iroha_score, #score_func
0.0, #aim
show_pool_func=iroha_show_pool, #show_para_func=None
seed=None, #seed=None
pool_num=5000)
#結果の表示
print(para)
print(score)
#ポケモンを表示
for p in para:
print(data_save[p], end=' ')
print()
#多かった音、足りなかった音を表示
iroha = list('アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワオン')
name = ''
for p in para:
name += data[p]
name = list(name)
print('多かった文字')
for s in name:
if s in iroha:
iroha.remove(s)
else:
print(s)
print('足りなかった文字')
print(iroha)実行結果
[157 297 6 498 617 222 354 127 302 445 518 193]
-1.0
ヌオー ソーナノ ゼニガメ オーベム アマージョ タネボー フワンテ ミュウ サクラビス コロモリ バルチャイ エレキッド
多かった文字
足りなかった文字
['ケ']12匹でやってみると、「ケ」だけ足りませんでした。
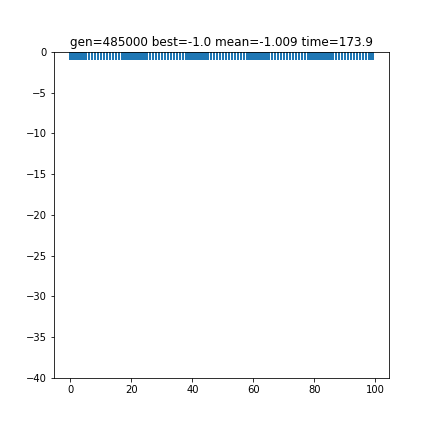
[157 297 6 560 508 222 354 127 567 208 461 513 56]
-1.0
ヌオー ソーナノ ゼニガメ ペロリーム マッギョ タネボー フワンテ ミュウ エレザード アチャモ バスラオ ゴルーグ ケーシィ
多かった文字
足りなかった文字
['ヒ']13匹でやってみると、今度は「ヒ」だけ足りませんでした。果たして「いろは歌」完成できるのでしょうか。
怒りの個体数10万体
あとはマシンパワーで殴ります。12匹、pool_num=100000で実行してみました。
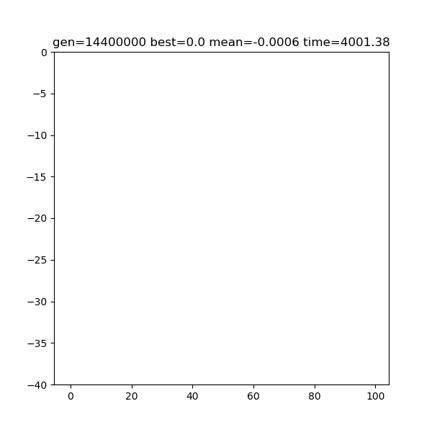
[157 297 6 560 506 275 153 127 567 95 14 534]
0.0
ヌオー ソーナノ ゼニガメ ペロリーム チョボマキ ハブネーク ワタッコ ミュウ エレザード モンジャラ スピアー ケルディオ
多かった文字
足りなかった文字
[]やりました!570万世代目でペナルティ0を達成!1440万世代で終了!過不足なし!ポケモンいろは歌の完成です!