概要
Prolog(ぷろろぐ)は論理プログラミング言語の一つで、データの性質や関係を「命題」として記述することで、問い合わせに対して論理的な答えを導き出してくれます。
例えば、
- ピチューの進化後はピカチュウ
- ピカチュウの進化後はライチュウ
- 進化後の進化後もまた進化後と言える
と定義しておけば、「ライチュウの進化前は?」という問い合わせに対して「ピカチュウとピチューです」と答えてくれます。
Prologは第2次AIブーム(1980年代)を牽引したエキスパートシステムの発展に寄与しました。昨今のディープでポンなAIとは対照的な技術として、その価値が再評価されているとかいないとか。
ここではPrologの動作をPythonで模倣することによって、その仕組みや利点を理解することを目指します。なお、専門用語は平易な表現にしている部分があります。
参考文献
こちらの参考書の例題を踏襲しています。
Ivan Bratko(著)、安部憲広(翻訳)『Prologへの入門 (PrologとAI)』近代科学社
Prologの実行環境には「AZ-Prolog」等ありますがライセンスにご注意ください。

Python実行環境には
WinPython3.6をおすすめしています。

Google Colaboratoryが利用可能です。

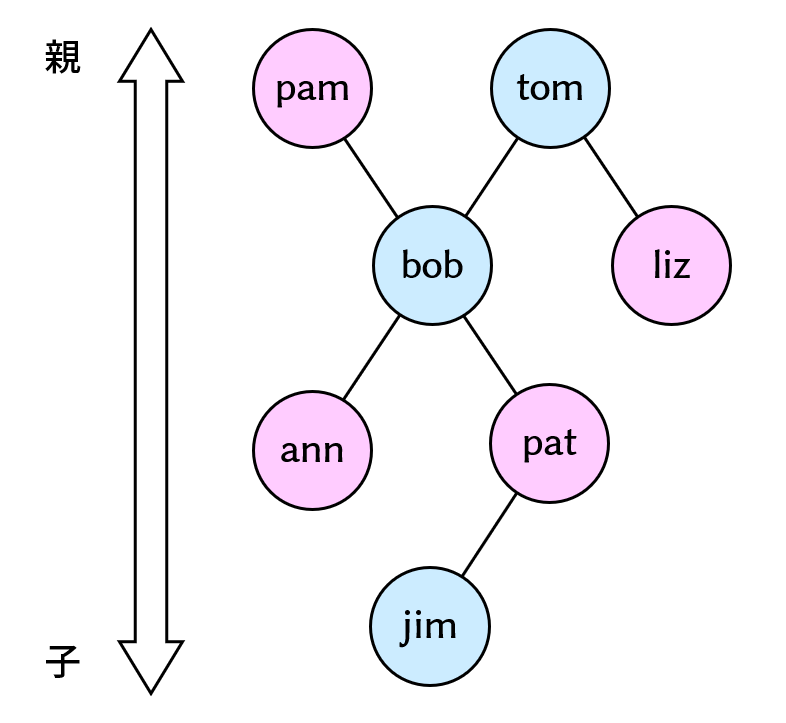
家系図
こちらの家系図を参照します。
ファクトと”変数なし質問”
Prologで6つの親子関係を定義します。このような定義をファクトと呼びます。
parent(pam, bob).
parent(tom, bob).
parent(tom, liz).
parent(bob, ann).
parent(bob, pat).
parent(pat, jim).その後、「pamはbobの親か?」と質問するとyes/noで答えてくれます。このような質問をクエリと呼びます。
?- parent(pam, bob). % pamはbobの親か?yesさて、定義した parent(pam, bob). については今回の例では第1引数が出力、第2引数が入力のように見えます。しかし機械にとってその順序は関心がないことで、単にpamとbobはparent関係にあると記憶します。人間が「第1引数が親、第2引数が子」と決めて定義文を打ち、同じ決まりに従って質問をすれば順序を間違うことなく回答が得られるのです。
また、?- parent(pam, bob). は厳密には「parent(pam, bob) を満たす情報が一つでもあるか?」という意味です。定義された情報を上から順に参照し、マッチした瞬間にyesを返して終わります。
ここまでをPythonで再現します。定義を追加する関数 DEF() を作りました。
import pandas as pd
from copy import deepcopy
#初期化
data = pd.DataFrame()
#定義を追加する関数
def DEF(data, info):
tmp = pd.DataFrame(info, index=[0]) #情報展開
data = data.append(tmp, ignore_index=True)
#重複削除
if len(data) > 0:
data = data.drop_duplicates()
return data
#定義
data = DEF(data, {'func':'parent', 'arg1':'pam', 'arg2':'bob'})
data = DEF(data, {'func':'parent', 'arg1':'tom', 'arg2':'bob'})
data = DEF(data, {'func':'parent', 'arg1':'tom', 'arg2':'liz'})
data = DEF(data, {'func':'parent', 'arg1':'bob', 'arg2':'ann'})
data = DEF(data, {'func':'parent', 'arg1':'bob', 'arg2':'pat'})
data = DEF(data, {'func':'parent', 'arg1':'pat', 'arg2':'jim'})
print(data) func arg1 arg2
0 parent pam bob
1 parent tom bob
2 parent tom liz
3 parent bob ann
4 parent bob pat
5 parent pat jim定義された情報はpandasデータフレームで持つことにしました。これを見ると、やはり入力と出力の順序に決まりはなく、人言側の解釈が一貫していればよいことが納得できます。
さらに質問にyes/noで答える関数を ASK() としました。
#変数なし質問(Yes/No)
def ASK(info):
tmp = pd.DataFrame(info, index=[0])
#定義を上から検索
for i in range(len(data)):
#ある行が入力条件をすべて満たしているかチェック
flg = True
for col in tmp.columns:
if data.loc[i, col] != tmp.loc[0, col]:
flg = False
#すべて満たしていればyesを返す
if flg:
return True
break
#条件をすべて満たす行が一つもなければnoを返す
return False
#?- parent(bob, pat).
print(ASK({'func':'parent', 'arg1':'bob', 'arg2':'pat'}))True今後の処理の都合上、yes/noではなくTrue/Falseを返すようにしています。
“変数あり質問”
Prologでは大文字始まりの語は変数、小文字始まりの語は値(Prologではアトムと呼ぶ)として扱われます。変数を使って次のような質問ができます。
?- parent(X, liz). % lizの親は誰か?X = tomこれは厳密には「parent(X, liz) を満たす X は何か?」という処理が行われています。
複数の変数を使うこともできます。
?- parent(X, Y).X = pam
Y = bob;
X = tom
Y = bob;
X = tom
Y = liz;
X = bob
Y = ann;
X = bob
Y = pat;
X = pat
Y = jim;これは定義された6つがすべて取り出されました。
これもPythonで再現します。変数あり質問に答える関数 FIND() を作りました。
#変数あり質問
def FIND(info1, info2):
tmp1 = pd.DataFrame(info1, index=[0]) #情報展開
tmp2 = pd.DataFrame(info2, index=[0]) #情報展開
#変数名を取り出しておく
vcols = tmp2.loc[0].values
tmp2 = tmp2[1:]
#定義を上から検索
for i in range(len(data)):
#ある行が入力条件をすべて満たしているかチェック
flg = True
for col in tmp1.columns:
if data.loc[i, col] != tmp1.loc[0, col]:
flg = False
#すべて満たしていれば変数DFに記録
if flg:
tmp2 = tmp2.append(data.loc[i, tmp2.columns], ignore_index=True)
if len(tmp2) > 0:
#列名を変数に変更して返す
tmp2 = pd.DataFrame(tmp2.values, columns=vcols)
return tmp2
else:
return False
#?- parent(X, liz).
print(FIND({'func':'parent', 'arg2':'liz'}, {'arg1':'X'}))
#?- parent(X, Y).
print(FIND({'func':'parent'}, {'arg1':'X', 'arg2':'Y'})) X
0 tom
X Y
0 pam bob
1 tom bob
2 tom liz
3 bob ann
4 bob pat
5 pat jimこちらも処理の都合上、pandasデータフレームで返すようにしています。
AND処理
「jimの祖父は誰か?」という質問は次のようにできます。
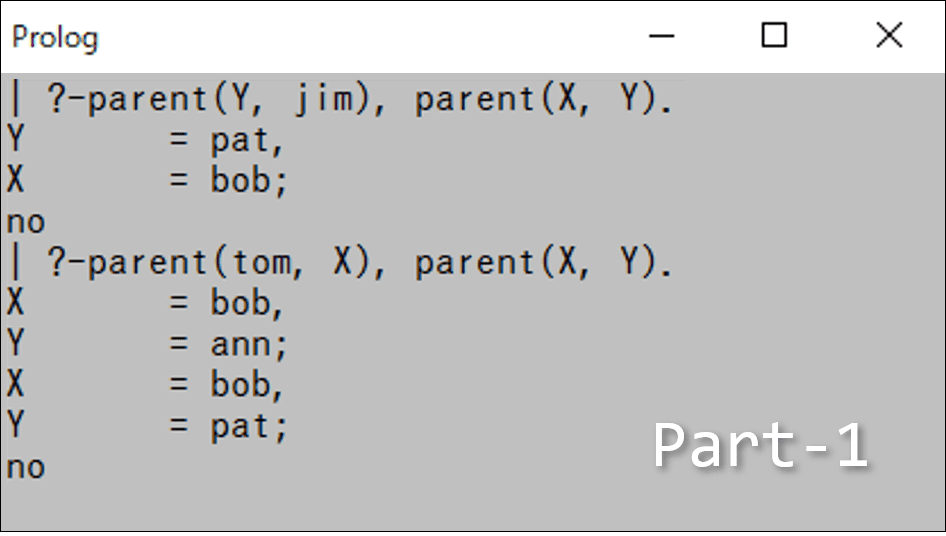
?- parent(Y, jim), parent(X, Y). % jimの祖父母は誰か?X = bob
Y = patカンマはAND処理を意味していて、「jimの親をYとする」「Yの親をXとする」をANDしています。もちろん厳密には「parent(Y, jim) を満たす Y は何か?」と「parent(X, Y) を満たす X, Y は何か?」のANDが取られています。
類似の質問です。
?- parent(tom, X), parent(X, Y). % tomの孫は誰か?X = bob
Y = ann;
X = bob
Y = pat条件を並べる順序は問わず、 ?- parent(X, Y), parent(tom, X). としても答えは変わりません。
Pythonで「2つの変数あり質問の回答をANDする関数」 AND() を作りました。
#AND処理
def AND(ret1, ret2):
#列名の和集合
ucols = list(set(list(ret1.columns)) | set(list(ret2.columns)))
#列名の積集合
icols = list(set(list(ret1.columns)) & set(list(ret2.columns)))
#ANDしたDF
u = pd.DataFrame(columns=ucols)
for i in range(len(ret1)):
for j in range(len(ret2)):
#積集合列がすべてマッチしているかチェック
flg = True
for col in icols:
if ret1.loc[i, col] != ret2.loc[j, col]:
flg = False
#すべて満たしていれば和集合列の情報を記録
if flg:
tmp1 = ret1.loc[i].to_dict()
tmp2 = ret2.loc[j].to_dict()
tmp3 = dict(tmp1, **tmp2)
tmp4 = pd.DataFrame(tmp3, index=[0])
u = u.append(tmp4, ignore_index=True)
return u
#?- parent(Y, jim), parent(X, Y).
#1つ目
ret1 = FIND({'func':'parent', 'arg2':'jim'}, {'arg1':'Y'})
print(ret1)
#2つ目
ret2 = FIND({'func':'parent'}, {'arg1':'X', 'arg2':'Y'})
print(ret2)
#AND
print(AND(ret1, ret2)) Y
0 pat
X Y
0 pam bob
1 tom bob
2 tom liz
3 bob ann
4 bob pat
5 pat jim
X Y
0 bob pat正しく回答が得られました。
#?- parent(tom, X), parent(X, Y).
#1つ目
ret1 = FIND({'func':'parent', 'arg1':'tom'}, {'arg2':'X'})
print(ret1)
#2つ目
ret2 = FIND({'func':'parent'}, {'arg1':'X', 'arg2':'Y'})
print(ret2)
#AND
print(AND(ret1, ret2)) X
0 bob
1 liz
X Y
0 pam bob
1 tom bob
2 tom liz
3 bob ann
4 bob pat
5 pat jim
X Y
0 bob ann
1 bob patこちらも正しく得られました。条件の順序を入れ替えると ret1, ret2 の中身が変わりますが、AND処理後の情報に違いはありません。
おわりに
今回は「ファクト」「変数なし質問」「変数あり質問」「AND処理」までを再現しました。次回は「ルール」を見ていきます。
