



vc-grendelとは
概要
「vc-grendel」はvcoptのプレミアムパッケージで、並列計算による高速なGAを実現します。例えば、4コア8スレッドのPCであれば、問題の性質によりますが、vcoptと比べて3~4倍程度の高速化が期待されます。
パッケージそのものはvcoptと同一で、有償のパスワードを入力することで並列計算オプションが機能します。したがって、vcoptのコードがほとんどそのまま使用できます。
注意点
並列計算が可能なのは、すべてのGAコマンド(tspGA, dcGA, setGA, rcGA)です。opt2 には非対応です。
パスワードの購入前に、必ずvcoptでの動作確認を行ってください。「並列計算が機能しない」につきましてはサポート対象ですが、「vcoptでも動かない」等は対応いたしかねます。
すべての問題において並列計算が高速化に寄与するわけではありません。どのような問題に有効か をご参照ください。
並列計算の仕様上、乱数シードを固定することはできません。
実行方法
seed='(password)’、core_num=4 のように指定します。
#GAで最適化
para, score = vcopt().rcGA(para_range, #パラメータ範囲
niji_kansu, #評価関数
0.0, #目標値
seed='(password)', #乱数シードの代わりにパスワードを入力
core_num=4) #並列ノード数を指定実行時、core_num : 4 (vcopt, *vc-grendel) と表示されることを確認してください。
___________________ info ___________________
para_range : n=5
score_func : <class 'function'>
aim : 0.0
show_pool_func : 'bar'
seed : None
pool_num : 50
max_gen : None
core_num : 4 (vcopt, *vc-grendel)
___________________ start __________________-1を指定すると論理コアすべてを使用します。-2を指定すると論理コアをひとつだけ残します。また、理由は分かりませんが、論理コア数よりも大きいノード数を指定するとより高速化する場合があります。
どのような問題に有効か
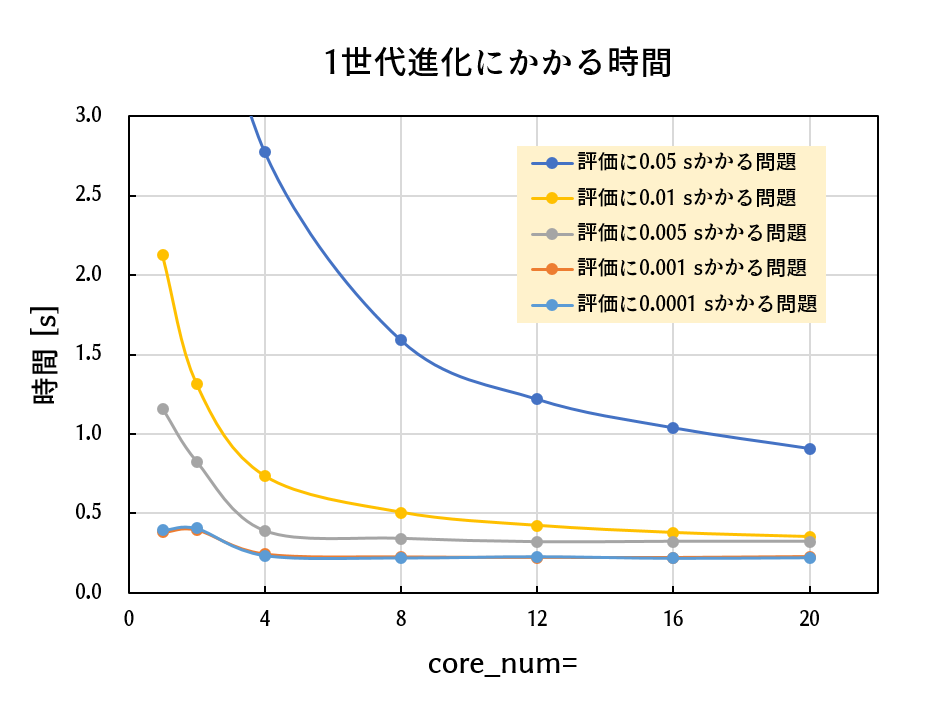
測定条件:WinPython3.6, Intel Core i7-3960X(3.30GHz/6C/12T), 問題は10次元のRastrigin, 評価関数に所定のtime.sleep()を挿入, pool_num=100, 各点1回試行
以上より、評価関数内の滞在時間が一定以上のとき、並列化の恩恵が受けられることがわかります。
| (1回の評価にかかる時間) | (並列化の恩恵) |
| 0.001秒未満 | 並列化の恩恵は小さい。4ノードで1.5~2倍の高速化が期待される |
| 0.005~0.01秒 | 並列化の恩恵は大きい。4~8ノードで3~4倍の高速化が期待される |
| 0.05秒以上 | 並列化の恩恵が大きい。4~8ノードで3~4倍の高速化が期待され、12ノード以上でさらなる高速化が望める |
では、1回の評価にかかる時間はどのように測定すればよいでしょうか。もっとも簡単な方法は、pool_num=8000 といった大きな個体数を設定し、初期個体の評価にかかる時間を測ることです。
また、並列化の恩恵が受けられるかどうかは、pool_num等、その他の条件にはほとんど依存しないようです。
パスワードの購入方法
(準備中です)
ライセンス
vcoptのライセンス規定が適用されます。