やること
Exploratory, Inc.が提供する統計解析ソフト「Exploratory」の評判を耳にしたので、無償版の使い勝手を試してみました。説明書はあえて読まずに行きます!(開発者に失礼)
※筆者とExploratoryとは一切の利害関係がありません。
Exploratoryとは
GUI(マウスクリック)でサクサクとデータサイエンスができるソフトのようです。統計解析に長けたR言語がベースなので、Rのパッケージでさらに機能を拡張できるようです。

使用したデータ
「ポケモンいろは歌」でお世話になったポケモンの種族値データシートを使わせていただきます。

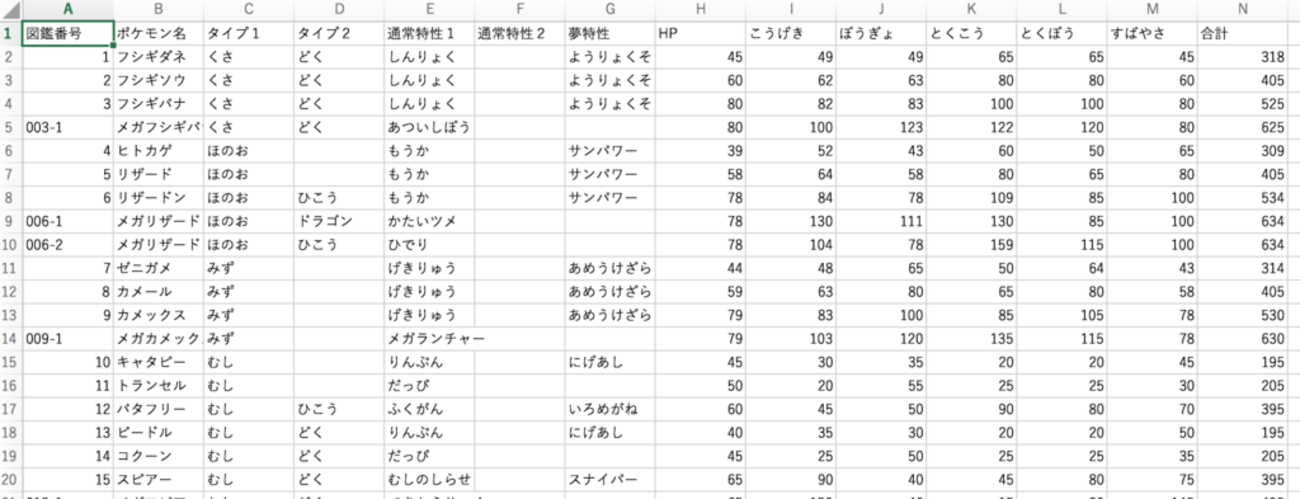
Excel版とcsv版があります。ちなみに718番目のポケモンの列がちょっとおかしいので、これをExploratoryでどう処理すればよいかも検証していきます。
インストール
HPを見ると、いろいろ可視化できそうな感じが漂っています。
ユーザー登録(無料)をして、デスクトップ版をダウンロード・インストールします。
必要な付属ソフトも自動的にインストールされます。
プロジェクトの作成とデータのインポート
起動して新規プロジェクトを作成します。
読み込めるデータの形式はExcelやcsvをはじめ、JSONファイルまであれば困ることはないと思います。
読み込みの際にヘッダーや区切り文字を視覚的に調整できます。
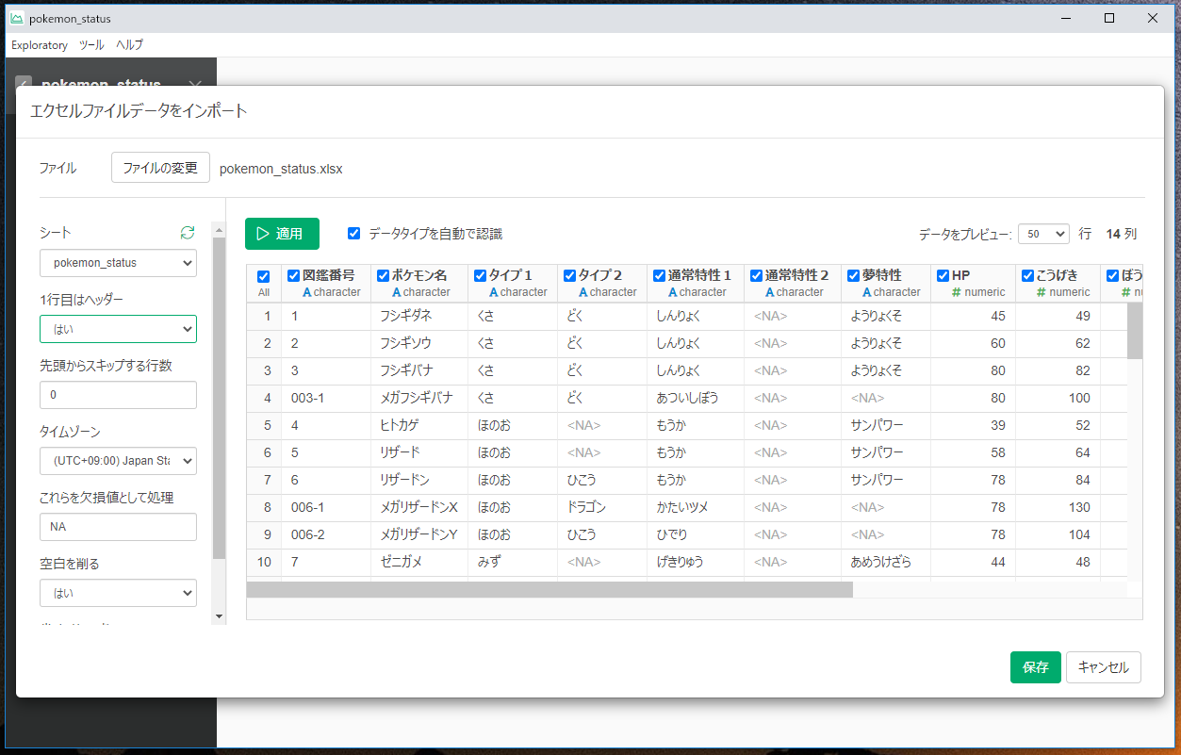
読み込みが完了するとサマリ画面へ移りますが、もう基本的な統計情報が出ています。仕事が早い。9時に出社したとして、9時20分には1日の仕事が終わったような気分になれます。
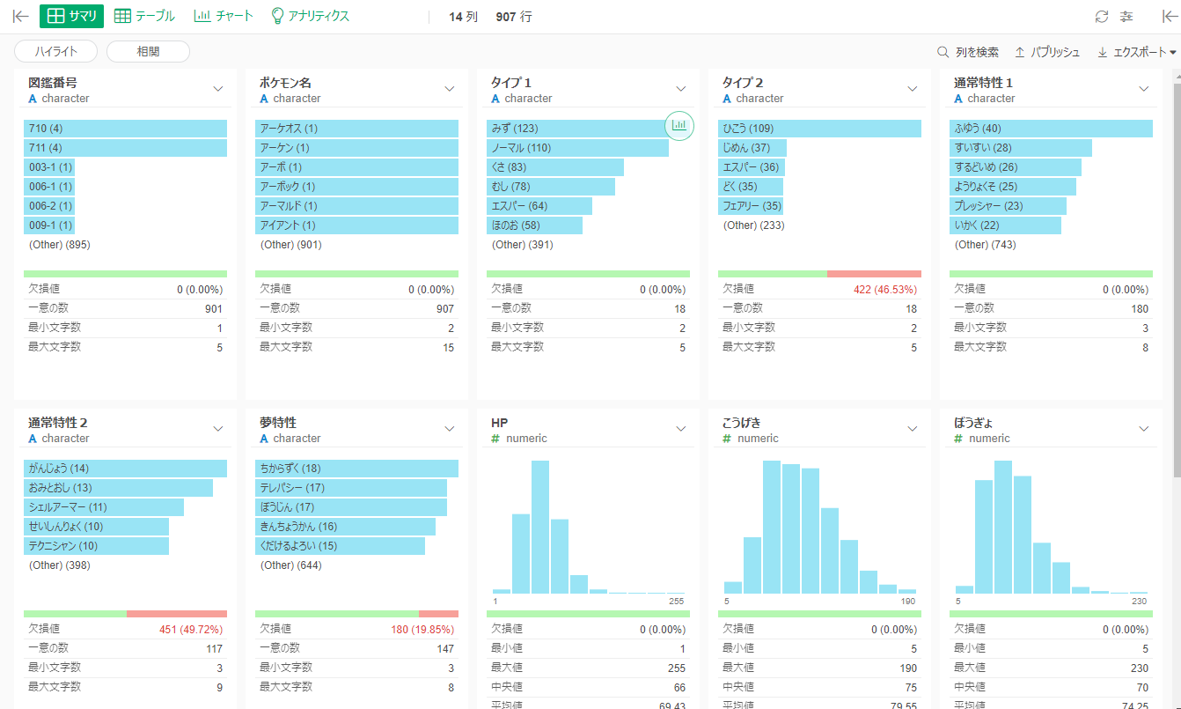
データを見ると、各列が文字列なのか数値なのかを自動判別して、それぞれヒストグラム化してくれているようです。欠損データは<NA>となっており、欠損率もグラフの下に表示されています。
データの前処理
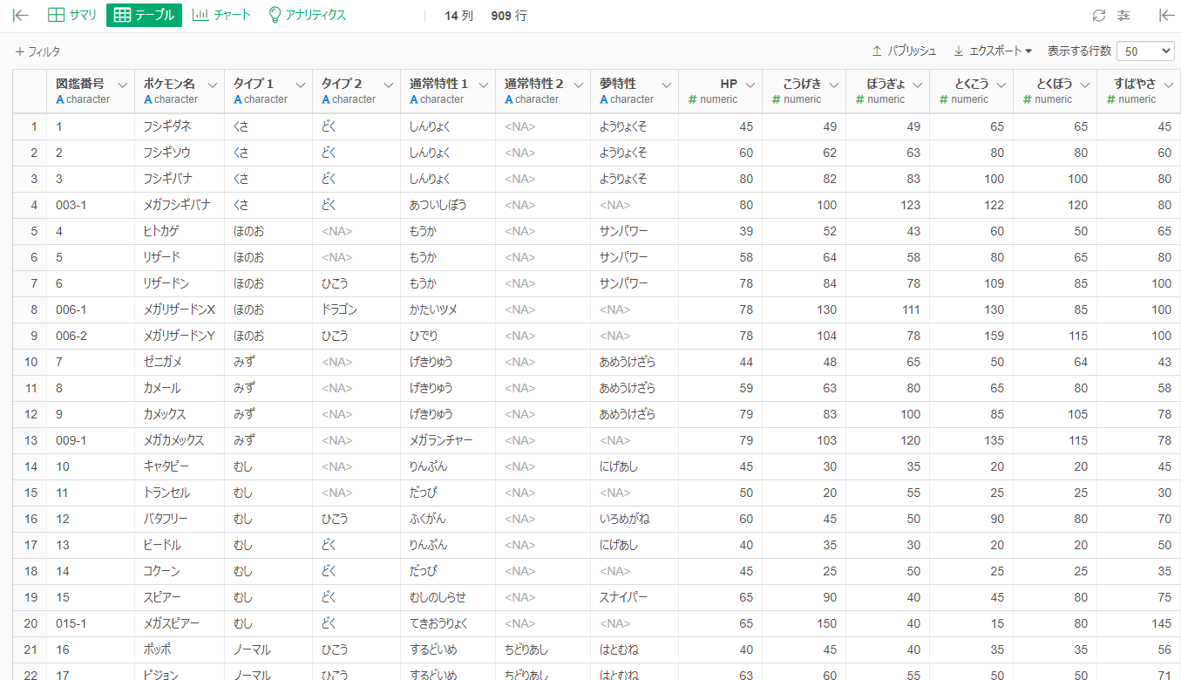
さて、718番目のポケモンのデータがおかしいはずなので確認してみます。


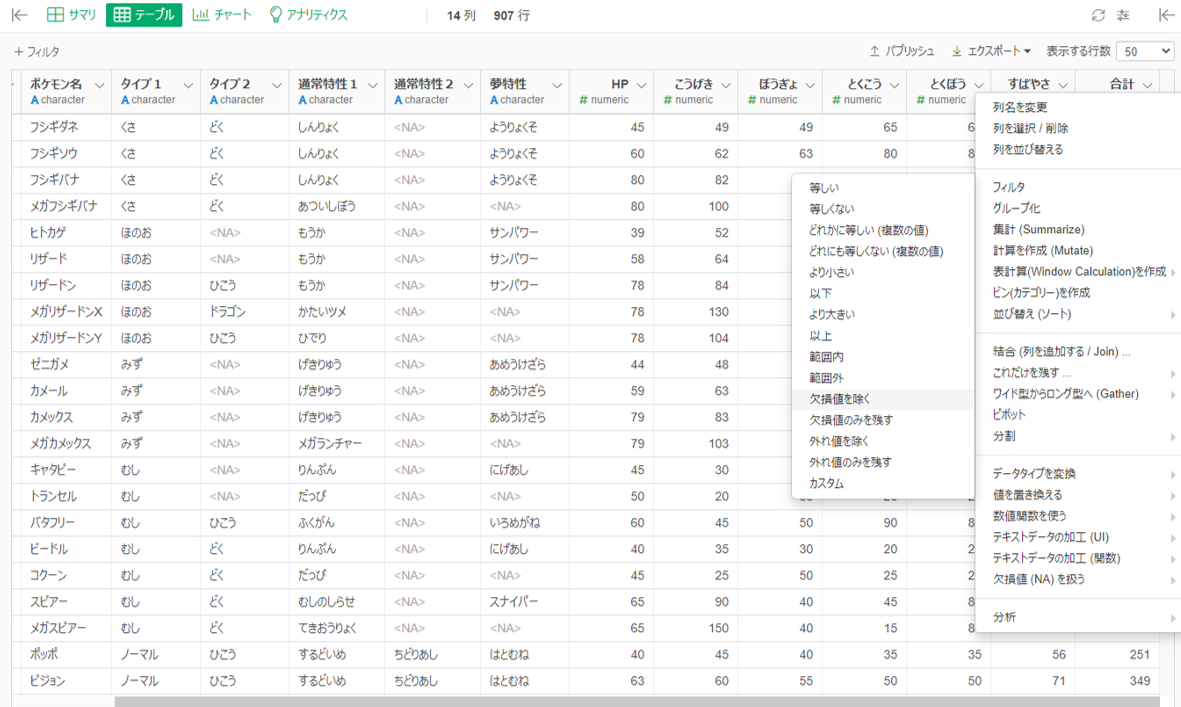
やはりそのまま読み込まれています。このままでは正しい統計解析ができないので、「合計」列を選択して「フィルタ」>「欠損値を除く」を行います。909行だったのが907行になったので、うまく除けたことがわかります。
グラフの作成
説明書なしでここまでこれたのは、正直なところ好感触です。どこまでいけるでしょうか。
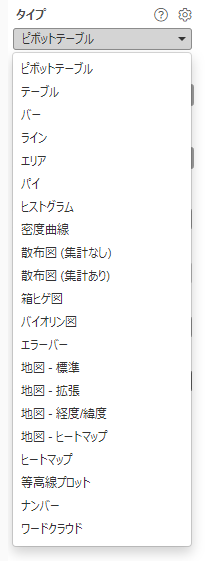
グラフにはこのような種類があります。
円グラフ
とりあえずポケモンのタイプ1で円グラフを作ってみます。
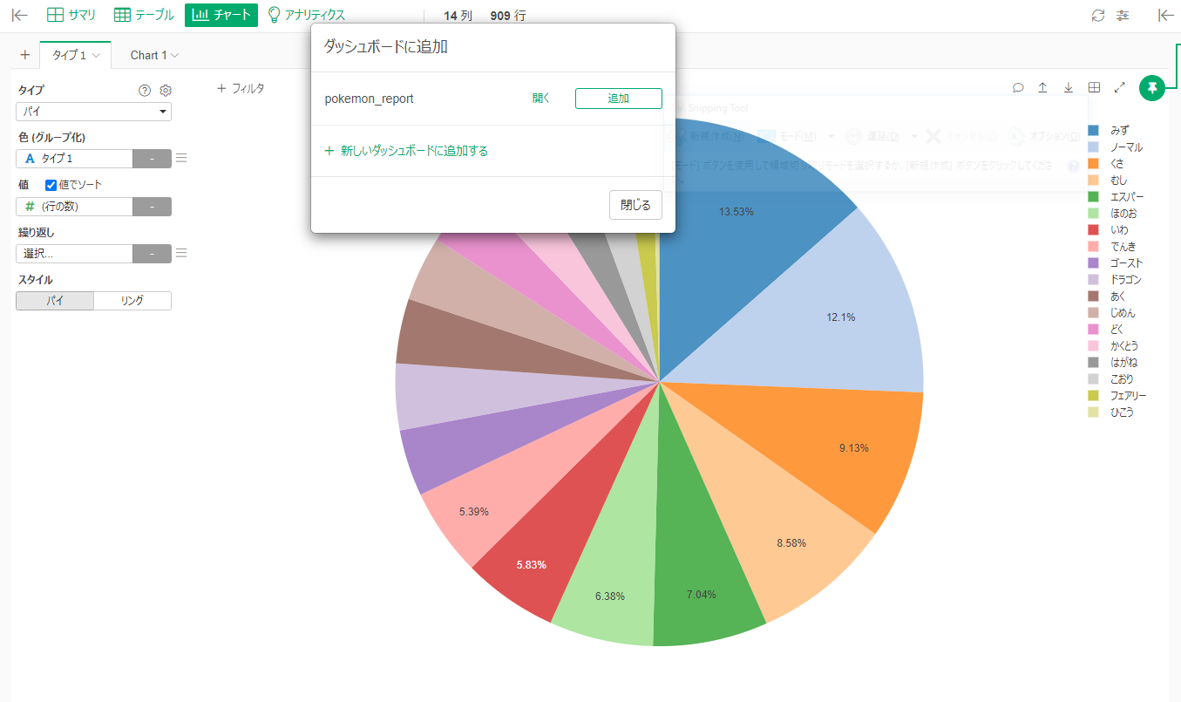
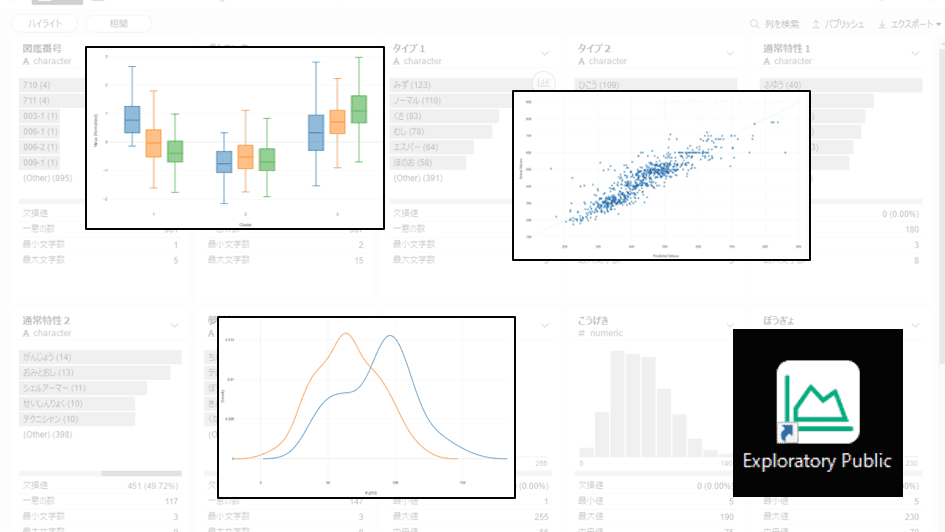
みずタイプがもっとも多い(ただしタイプ1に限る)ことや、ポケモンの約半数は、みず・ノーマル・くさ・むし・エスパーのいずれかをタイプ1に持つことがわかります。
ちなみに「3D円グラフは人を騙すときに使うもの」なので、3D機能は当然ありません(→テレビの印象操作を集めてみた(その1))。そんな機能があったら速攻でアンインストールするレベルです。
作成したグラフは「ダッシュボードに追加」から報告書的な場所に置いておけるようです。また、「エクスポート」から個別のグラフを画像として保存もできます。
積み上げ棒グラフ
タイプ1別の種族値の積み上げ棒グラフを作成しました。左側にオプションが並んでいて、どんどんクリックして試せます。
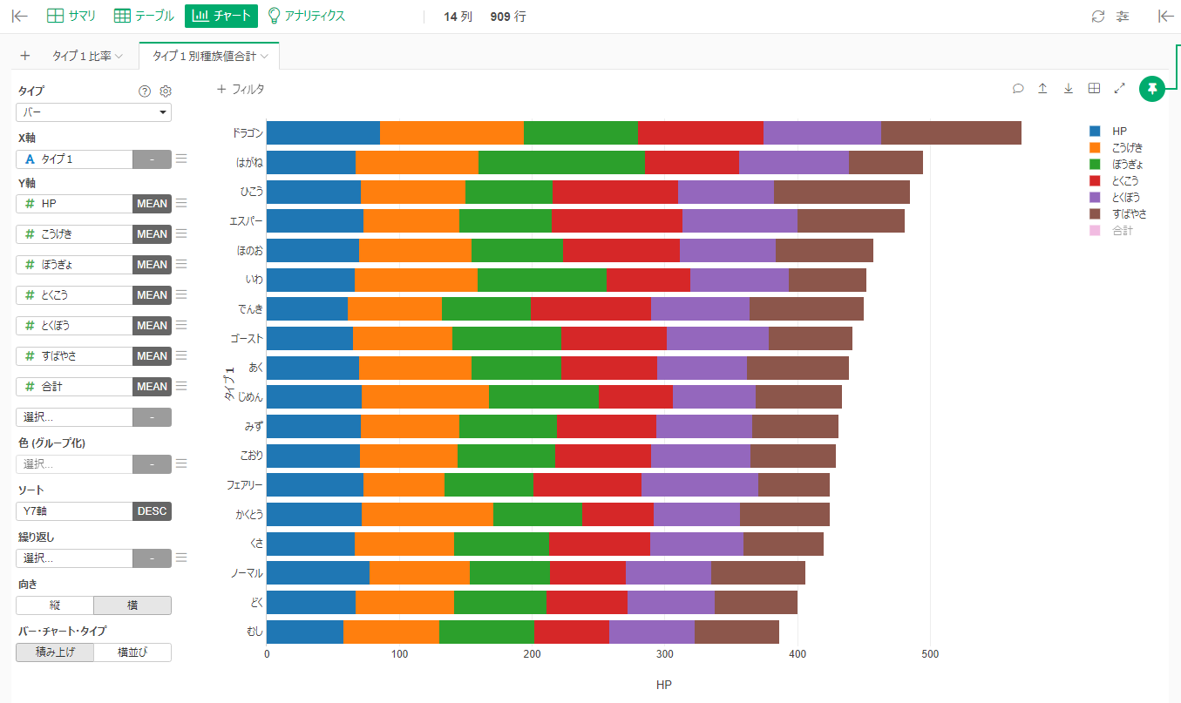
ドラゴンが高い合計値を持つことや、はがねのぼうぎょが高いことが分かります。
箱ひげ図やバイオリン図もある
グラフ機能は「ExcelでできることがExcelより簡単にできる」といった印象です。バイオリン図はExcelにはないので嬉しいです。
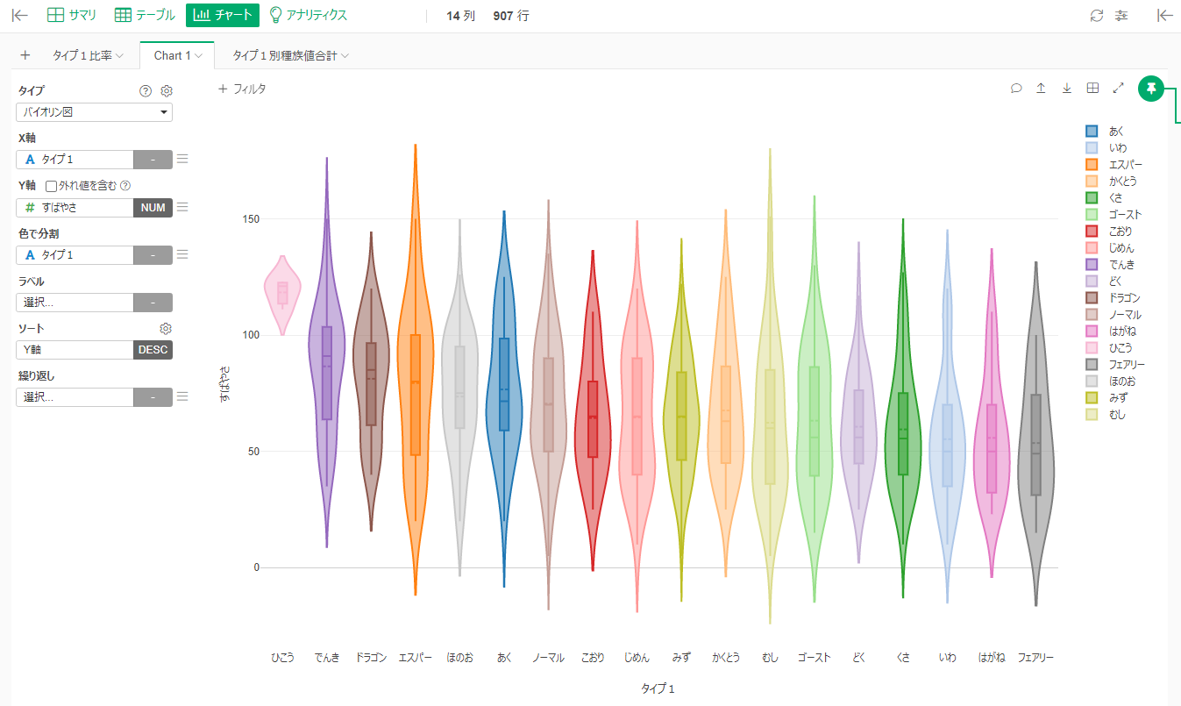
2022/1/20追記:タイプ1がひこうのポケモンは4匹しかおらず、彼らのすばやさが大きいため浮いているように見えます。タイプ2がひこうは109匹と最多のため、ひこうは基本的にタイプ2に入っていることになります。
さまざまな統計解析(その1)
統計解析にはこのような種類があります。
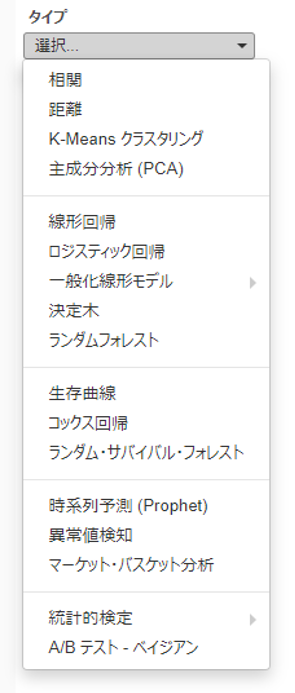
相関関係
こうげき・とくこう・すばやさの3つを指定して相関を調べます。6パターンの組み合わせで表示されました。
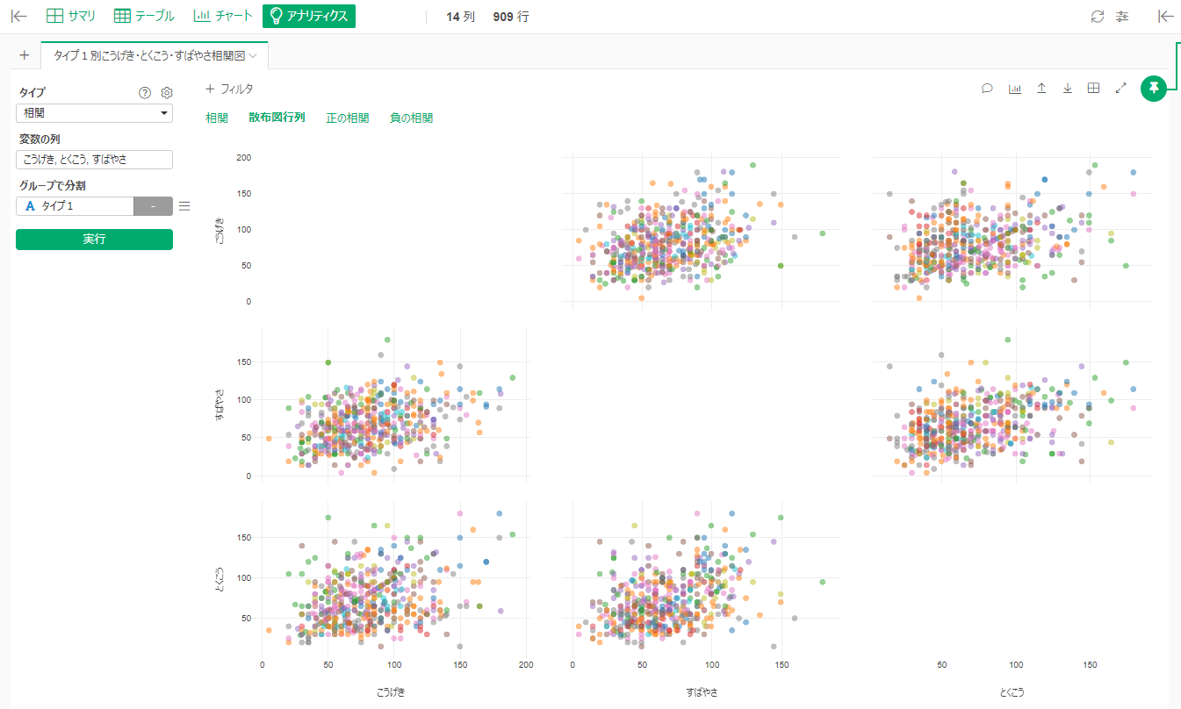
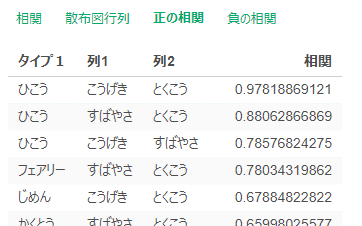
タイプ1別に見るように指定すると相関係数ランキングが出てきました。タイプ1がひこうのポケモンはこうげき・とくこう・すばやさの相関が高く、いわゆる「両刀アタッカー型」の傾向があります。
2022/1/20追記:タイプ1がひこうのポケモンは4匹しかいないため極端な相関係数が出やすいです。
K-means
こうげき・とくこう・すばやさでK-meansクラスタリング(3クラス指定)をしました。K-meansにはいつもお世話になっています(→K-meansタグ)。
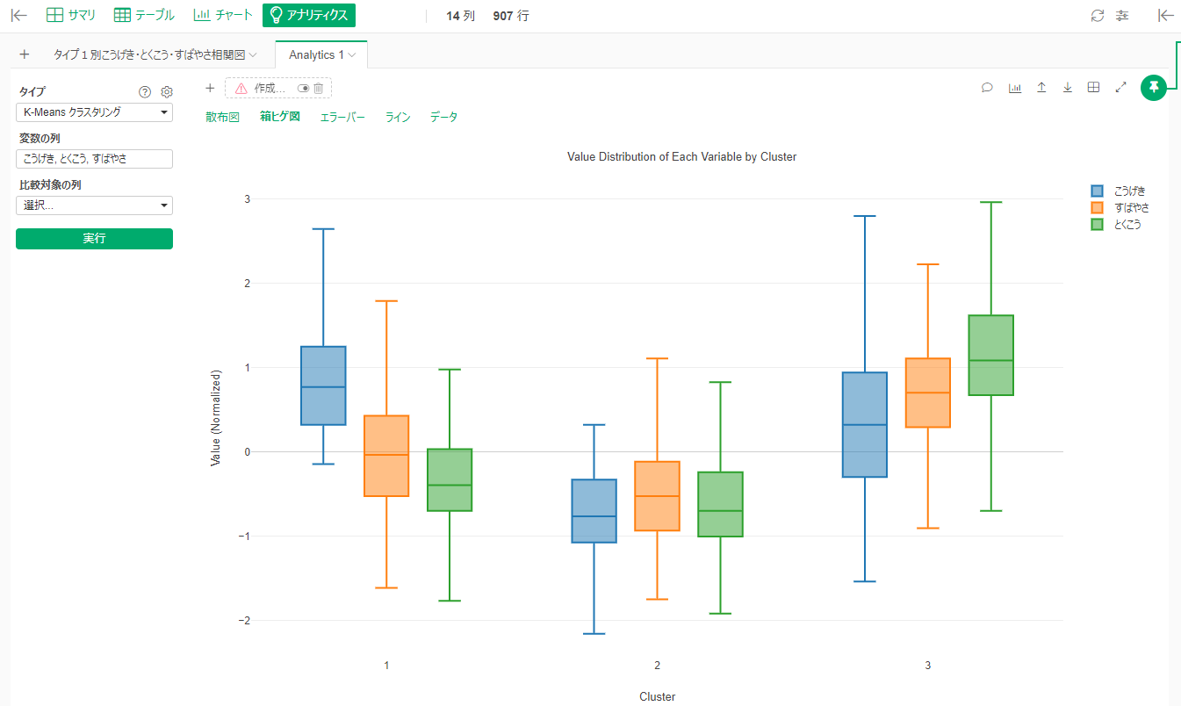
こうげき>すばやさ>とくこうグループ、とくこう>すばやさ>こうげきグループ、3つとも低いグループに分かれました。こうげきととくこうのどちらかを選ぶとすれば、とくこうグループの方がわずかにすばやさで優るようです。
線形回帰
こうげき・とくこう・すばやさの3つから種族値の「合計値」が推定できるか、線形回帰してみました。
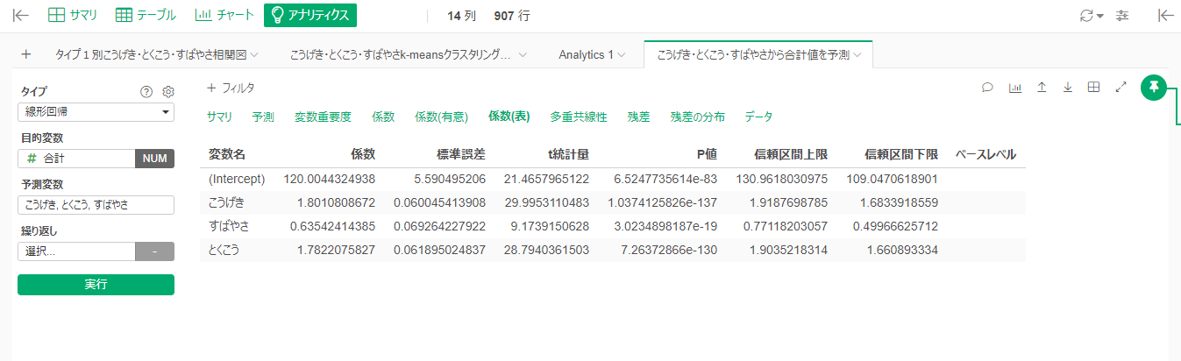
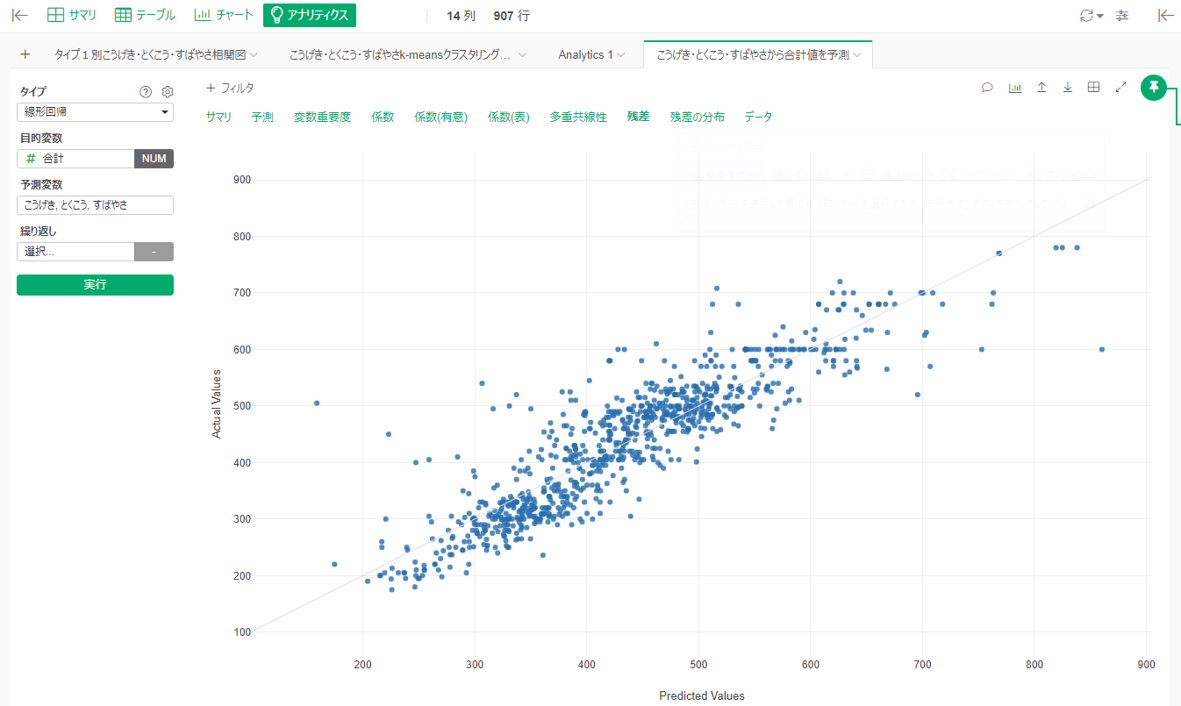
「合計値=1.80*こうげき+1.78*とくこう+0.64*すばやさ」で推定できるようです。
さまざまな統計解析(その2)
ここからはみずタイプとでんきタイプに絞って行います。データのところで「タイプ1がみずまたはでんきに一致するものだけ残す」ようにしてデータを削減します。
決定木
決定木を使って、こうげき・とくこう・すばやさの3つからみず・でんきタイプを分離してみました。
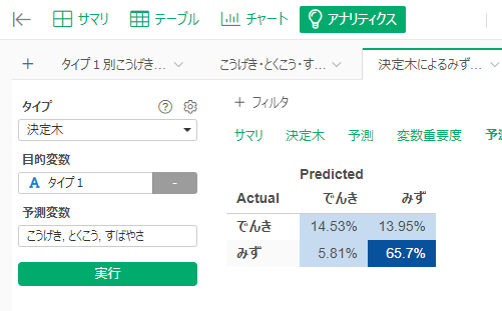
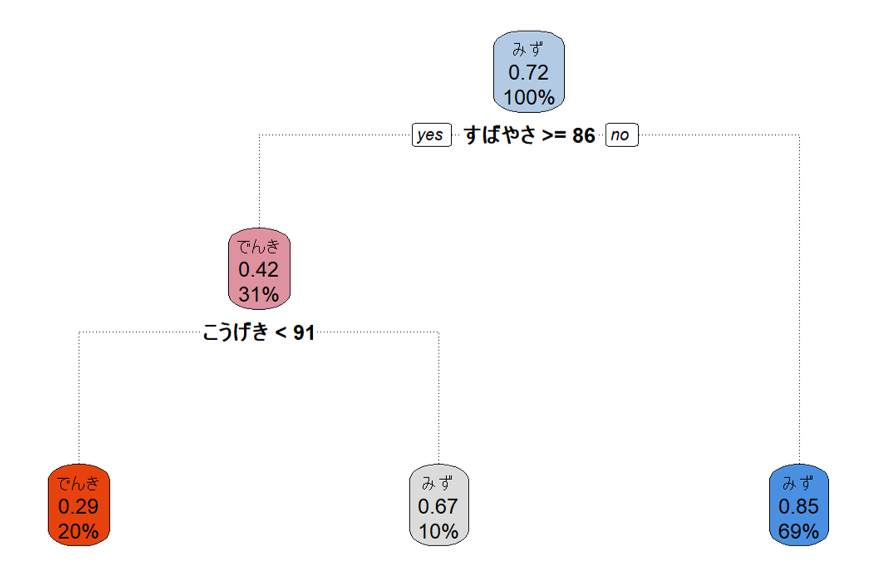
まず、すばやさ86未満であればみずタイプとする。そうでないグループは、こうげきが91以上であればみずタイプとする。残りがでんきタイプです。この方法でF値=0.80だそうです。
2022/1/20追記:タイプ1がみずのポケモンのほうが2倍くらいいるため、「データの不均衡を調整する」オプションを使ってもよいでしょう。
t検定
基本のt検定です。決定木では1番目にすばやさで分けましたが、「みずタイプとでんきタイプはすばやさに差がある」をt検定にかけてみます。
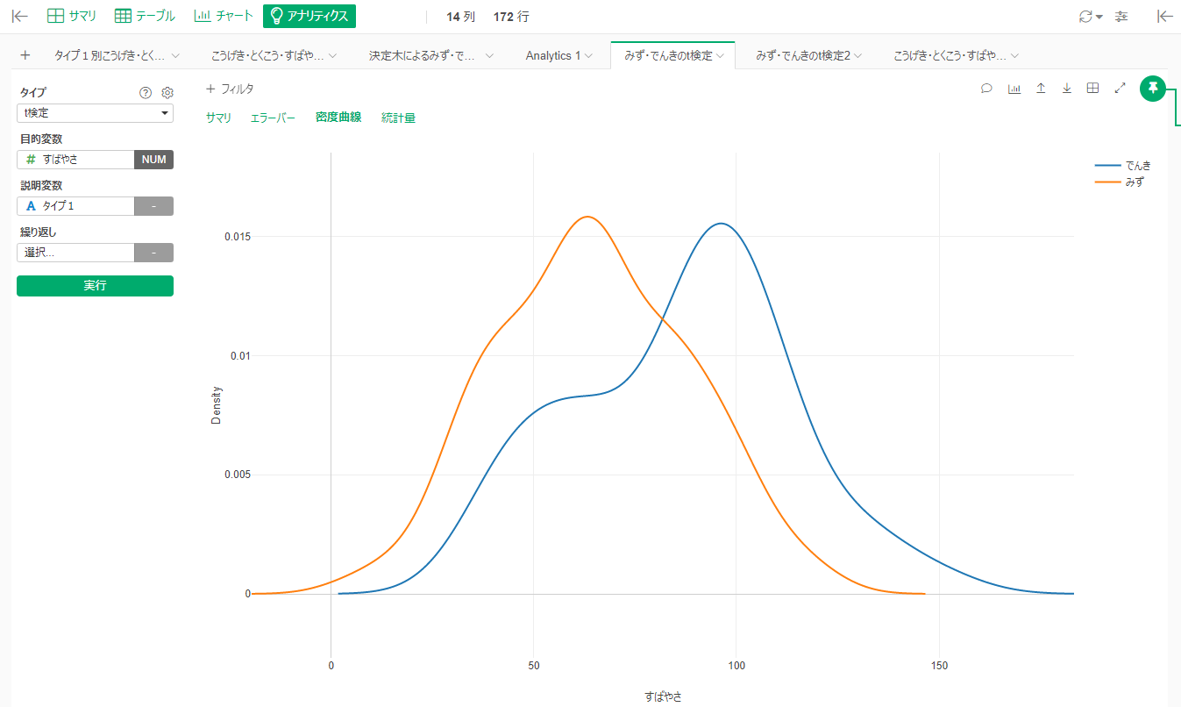
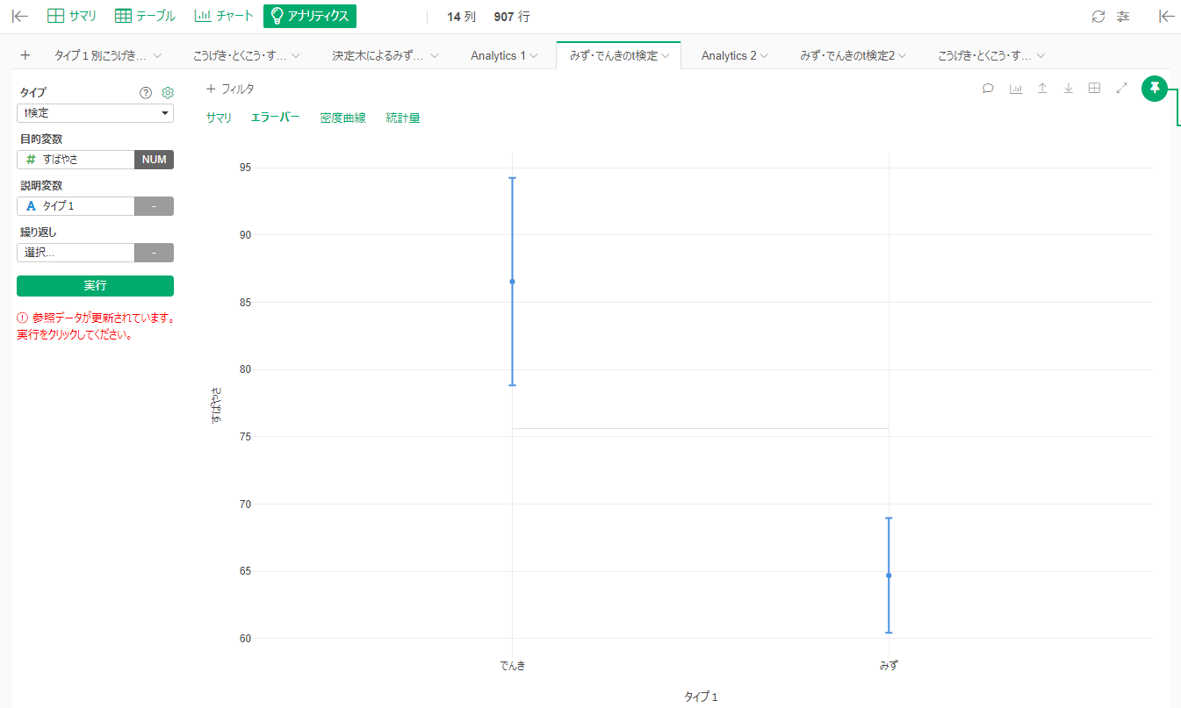
P値=0.000004(<0.05)なので「有意な差がある」と言ってよさそうです。ちなみにこうげきはP値=0.54で「有意な差があるか分からない」でした。「差がない」ではないことに注意が必要です(→ポケモンで分かる二項検定とZ検定の違い)。
レポート出力
ダッシュボードに溜まったグラフたちをhtmlなどで出力できます。

使い勝手・感想
すべての機能を試していないので、あまりフェアなことは言えないですが。記事を書く時間を除くとインストールから1時間半程度しか経っていません。ここまでの一連の流れを説明書も検索もなしにできたのは、ソフトウェアとして素晴らしいことですね。
利用規約の確認
設定さえ間違えなければ、データの秘匿性は保たれるようです。個人情報が売り飛ばされることもなさそうです。


データの用意、クレンジング
何らかのシステムから吐き出されたデータベースを用いる場合は、すぐにExploratoryに入れて前処理して良いでしょう。「テキストデータの加工」から文字列の置換は容易なので、表記ゆれの修正はできます。他にも数え切れないくらいの機能があります。
一方でExcel等で加工中のデータは可能な限りExcel等で整理しておくと良いでしょう。Exploratoryに入れてしまうと、フィルタリングでデータを絞ることはできますが、列の追加などはできません(たぶんできるけどとても面倒)。セルを指定して何かするとか、ここからここまでをコピーして貼り付けるとか、そういったセル単位の指定や操作はできないか、かなり面倒なようです。
データの整理まではExcel、可視化と統計解析はExploratoryと切り替えると良いと思います。
2021/1/20追記:データのクレンジング、加工も慣れたら結構かんたんでした!
グラフ描画に関して
Excelと比較したメリット
- Excelより簡単にグラフを描ける(より直感的な操作)
- Excelにはない種類のグラフがある(バイオリン図、ワードクラウドなど)
Excelと比較したデメリット
- データの一部を選択してグラフを描き辛い
Exploratoryの方が簡単で美しいと思いますが、データの一部を選択してグラフを描くにはそこをフィルタする条件を考えてフィルタしなければいけません。次に別の一部をグラフ化する場合は、前のフィルタを解除して新しくフィルタする必要があり、また前のグラフをいじろうとしたらまたフィルタをやり直さなければいけません。超めんどくさいです。(データフレームを複製すればExcelのSheetのように別々に処理できます)
2021/1/20追記:フィルタのON/OFFやブランチの分岐(頭痛が痛いみたいですが)ができるので大丈夫な印象です!
さまざまな統計解析
Exploratoryは基本的な統計解析が数クリックでできます。これはさすがに圧倒的な強みと言えます。一方で「誰でもExploratoryを使えば統計解析ができるようになるか」といえば、考え方にもよりますがそれは難しいです。基本のt検定ひとつとってもこれだけのパラメータがあります。
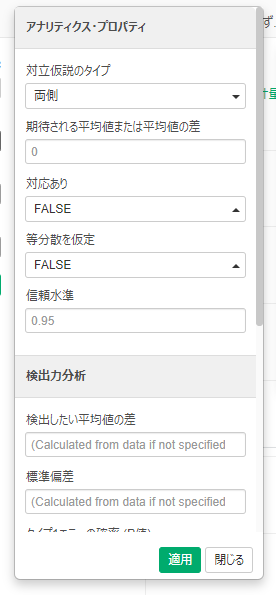
得られた統計量やP値は何なのか。相関係数はどう解釈すればよいのか。正解率、適合率、再現率、特異度、F値は何を意味していて、どういう場面でどれを重視すればよいのか。K-meansのクラスタ数は結局いくつがいいのか。このような結果の解釈はユーザーに任されます。
デフォルトのままでもそれらしい結果は出てきますので、個人利用にはバッチリです。しかし、研究や仕事で使用する場合にはこのような条件を理解して選択し、さらに発表の際には条件を明記しなければなりません。条件が明記されていなければ必ずツッコまれ、「なんとなく決めた」とか「デフォルトのまま」なんて答えてしまえば観客は去ります。
ですから、見た目だけでなく真に統計解析ができるためにはそれなりにデータサイエンスのリテラシーが必要です。ExcelもExploratoryもあくまでツール(道具)ですから、それを使う人の育成とセットで考える必要があります。これはExploratoryに限った話ではなく、すべての統計ソフトに共通して言える課題だと思います。Exploratory社はそういった教育も行っているようです。
悲観
ただ、昨今の社会状況を見ると、「真に統計解析ができる必要はない」という判断もあるかと思います。例えばテレビのワイドショーで使われるグラフなんかは正しい統計解析である必要がなく、お茶の間のおじいちゃんおばあちゃんにそれっぽいと思わせて納豆やイソジンを買いに行かせられれば成功(=正しいグラフ)なのです。そうなるとExploratoryよりもPhotoshopのスキルの方が大事になります。データサイエンティストの育成にはコストがかかります。その割にお茶の間のおじいちゃんおばあちゃんたちには伝わらないので、発信するテレビ局も重視しませんし、下請け会社もテキトーになります。
今の世の中は「何を発信したか」よりも「誰が発信したか(どんな肩書の人間が発信したか)」が重視されます。Twitterでいくら適切で有用なデータがポストされても、無名な人のツイートであれば何の効果も生みません。一方で大手企業やインフルエンサーは何を言っても「ああ、あの人が言うなら本当だろう」と信用されます。ですから自分が何者なのかということをまず理解すべきです。
結局のところ
そもそも優れているのですが、将来「ああ、Exploratoryで得られた結果なら本当だろう」とか「Exploratory社が育成した人材なら信用できそうだ」といった追い風が来るといいですね。限られた教育時間でそれなりにいい感じのデータを出すにはもってこいのツールなので、データサイエンスの裾野を底上げしてくれるのではないかと思います。RやPythonが書けるような玄人にとっては、時短になるか、他のデータサイエンティストとの共通言語の役割を果たすのではないでしょうか。

