2020/11/30追記あり
やること
株式会社MatrixFlowが提供するAI構築Webサービス「Matrixflow」は画像のCNNもできるらしいと聞いて、無償版の使い勝手を試してみました。説明書はあえてほとんど読まずに行きます!本家サイトでは「プログラミング不要の」とうたっていますが、そのあたりも検証させていただきます。
※筆者とMatrixFlowとは一切の利害関係がありません。
MatrixFlowとは
GUI(マウスクリック)でサクサクとAIができるWebサービスです。回帰、分類などの基本的な機械学習に加え、画像のCNNや自然言語処理にも対応しているようです。
使用したデータ
過去の勉強会で何回かお世話になっている、10種のケーキ画像のデータセットを後半で使います。

データ管理
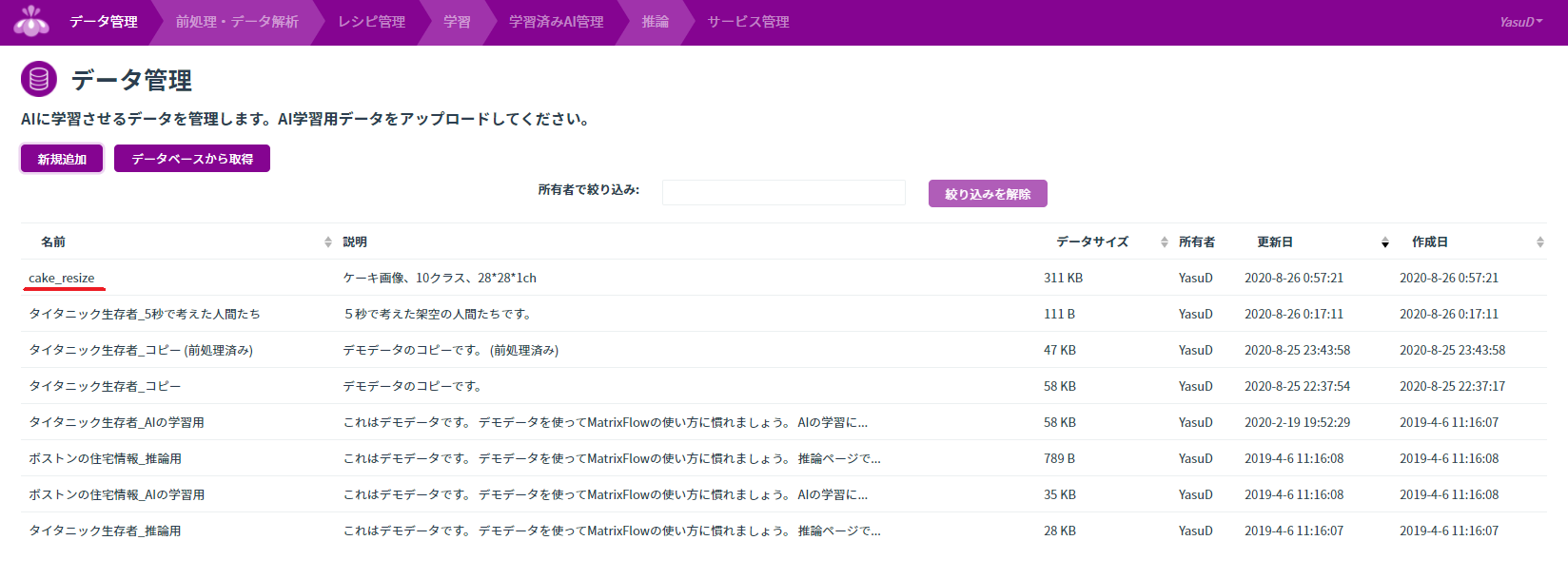
無料で会員登録してログインすると、「データ管理」タブにデモ用のデータセットが4つ用意されています(下4つ)。
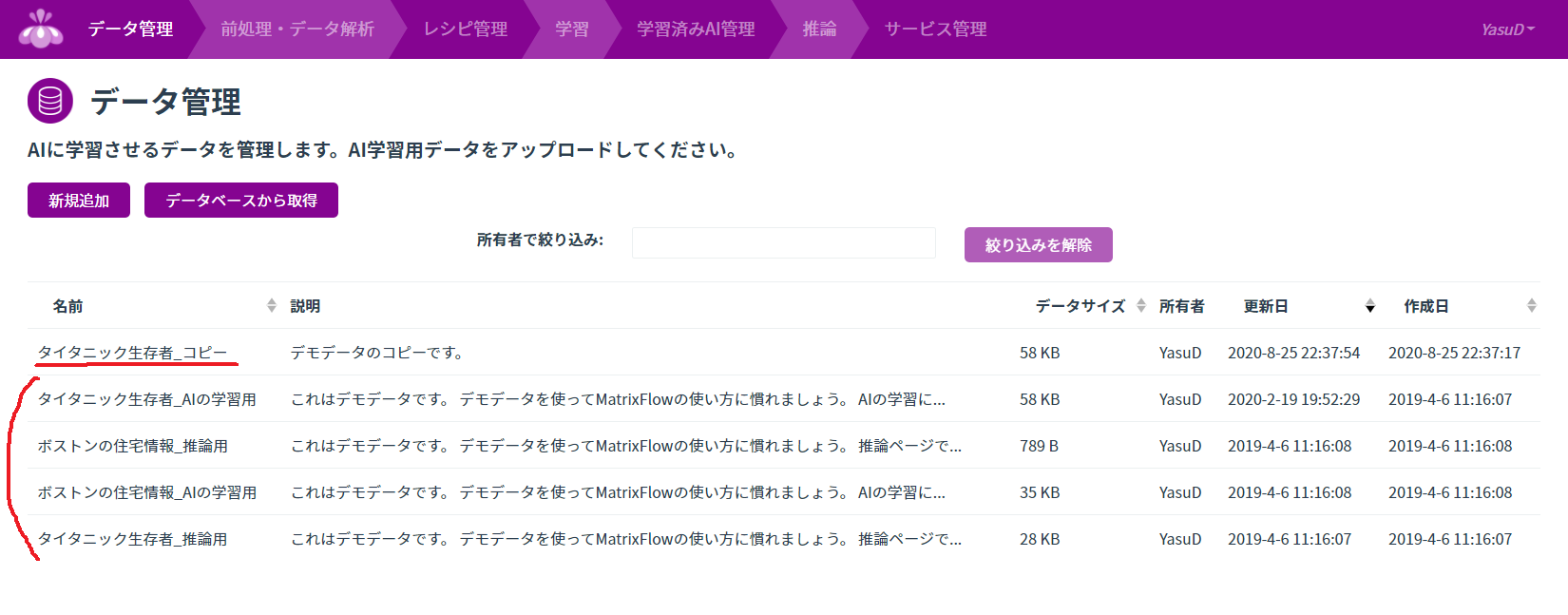
とりあえず「タイタニック生存者_AIの学習用」を一旦ダウンロードして、「タイタニック生存者_コピー」としてアップロードしました(一番上)。回帰や分類に使うデータセットはcsv形式のみ対応です。
前処理
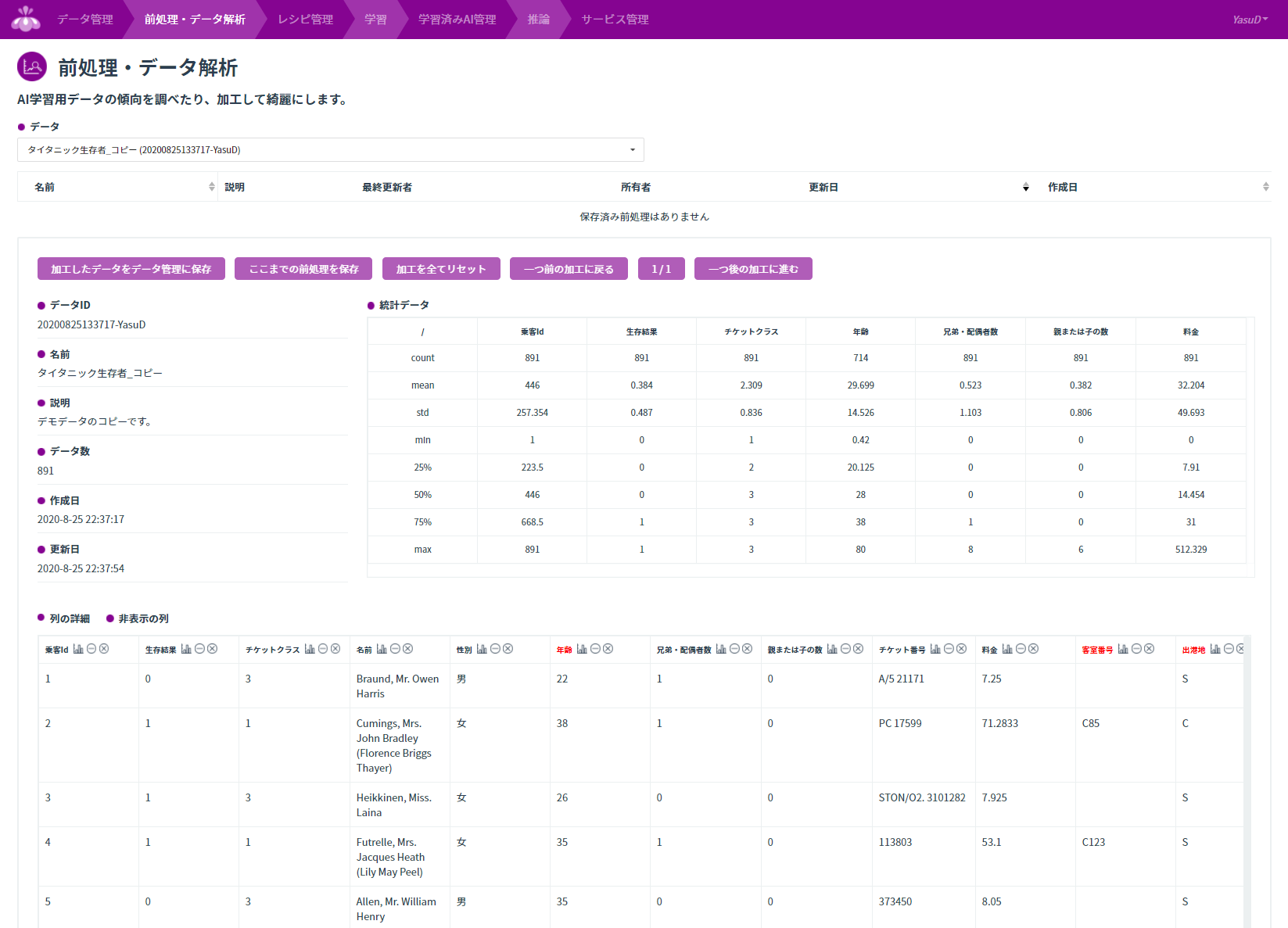
前処理のタブに移動して「タイタニック生存者_コピー」の前処理を始めます。基本的な統計情報を見ながら、どの列を処理していくか考えます。
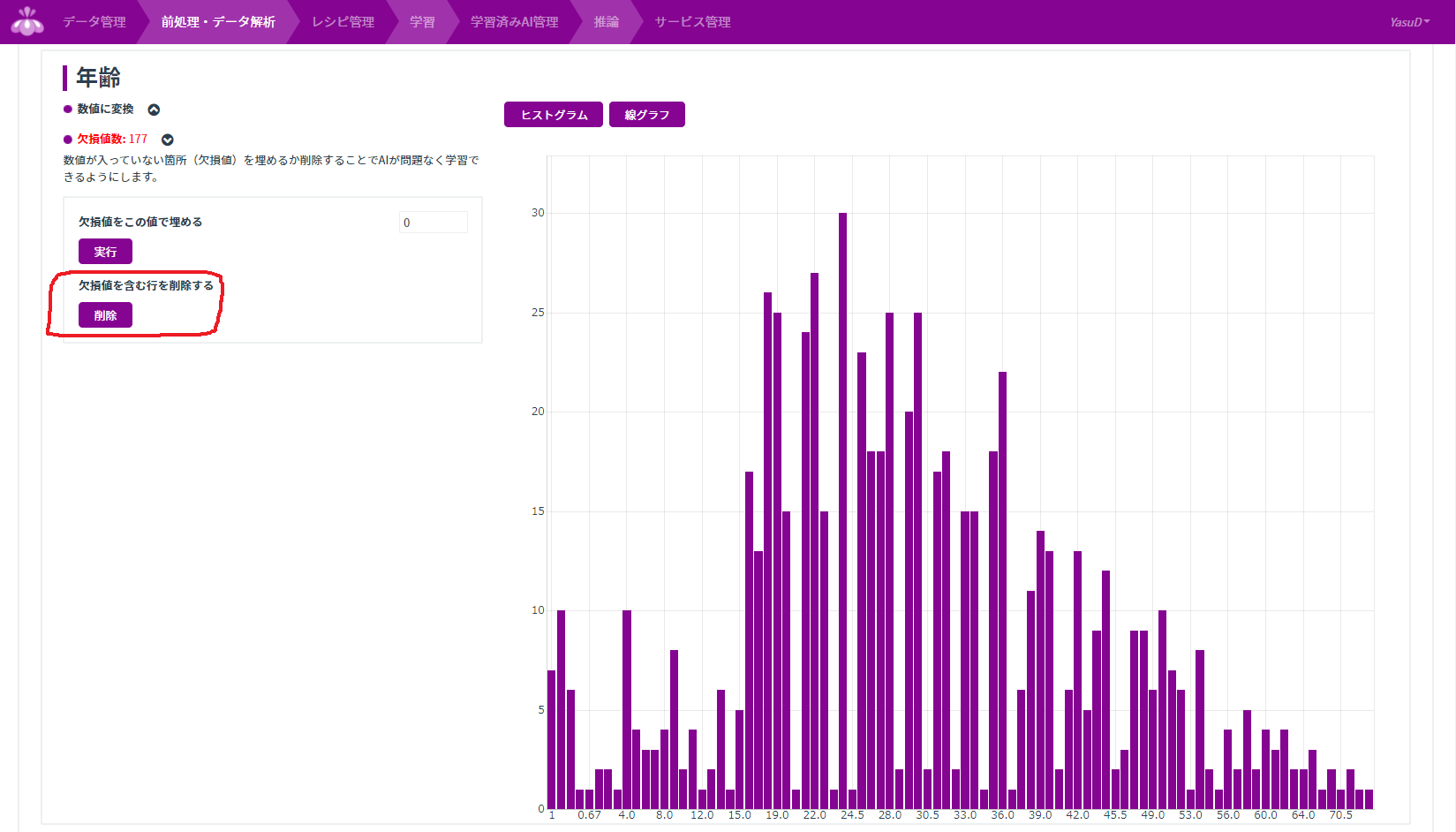
欠損値は学習に使用できないので、「年齢」に欠損値がある行を削除します。
また、数値データ以外は学習に使えないので、「性別」を数値ラベルに修正します。ここれは女→1、男→0にしました。
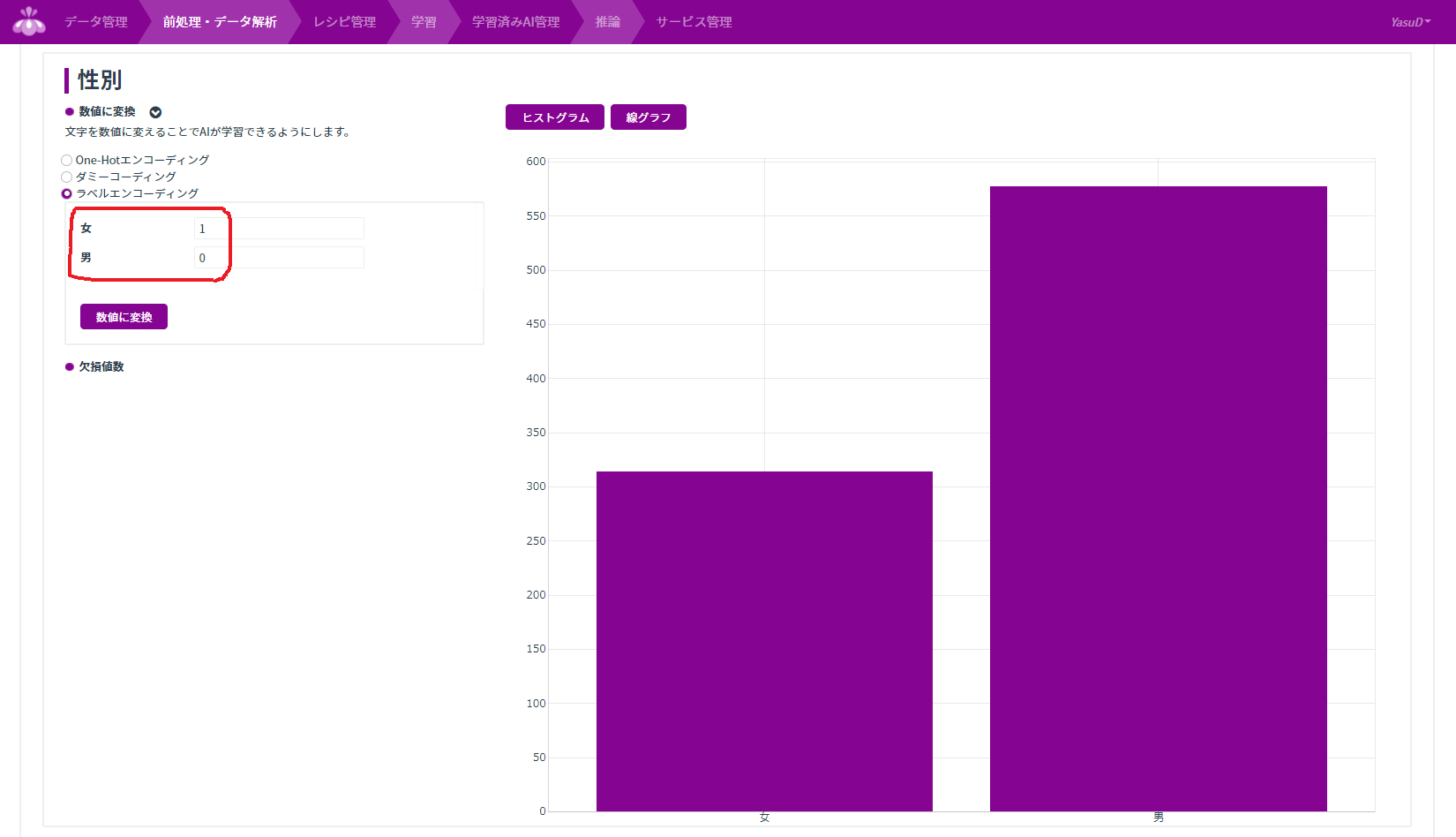
前処理したデータは(前処理済み)を付けて保存しました。前処理の手続きを保存しておいて、他のデータに適用させることもできるようです。
レシピ管理
デモ用に6つのレシピが用意されています。無償版ではレシピの編集や追加ができませんので、この中から2つ試したいと思います。
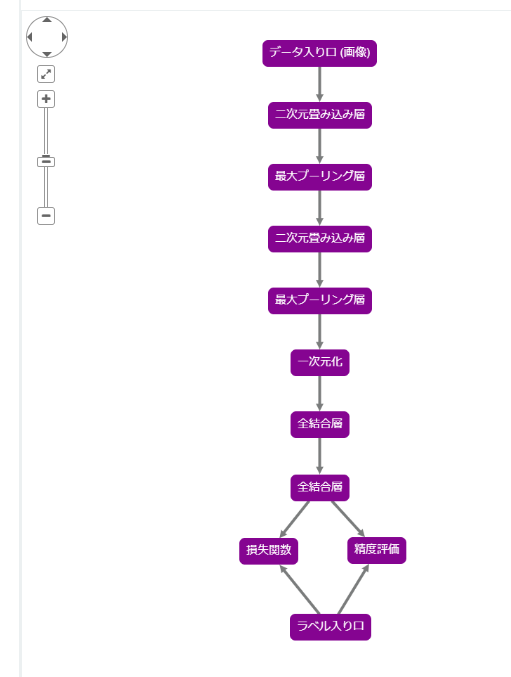
「白黒画像の10分類CNN」はこんなレシピです。
「分類LightGBM・SVM・ロジスティック回帰」はこんなレシピです。3つ同時にやってくれるのは親切ですね。
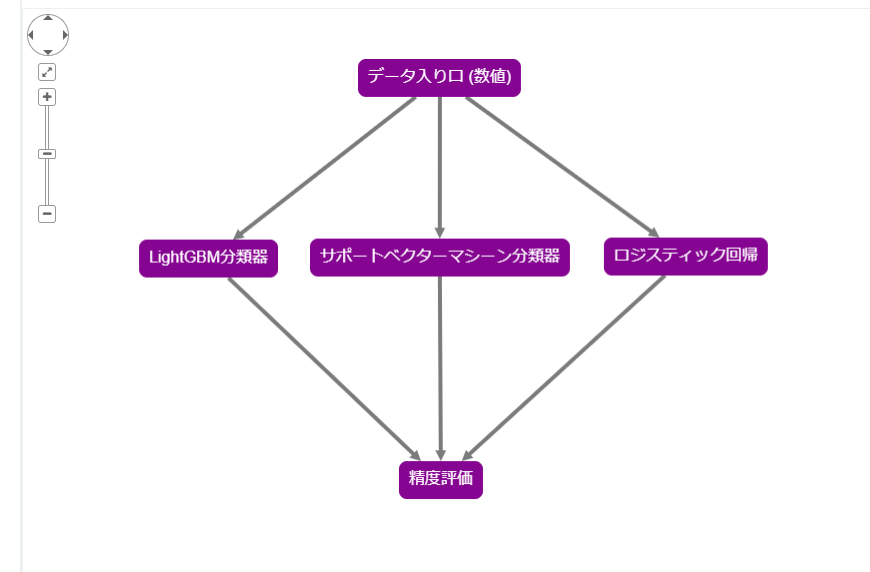
学習
ここでデータとレシピを混ぜて学習を行います。「タイタニック生存者_コピー(前処理済み)」と「分類LightGBM・SVM・ロジスティック回帰」を選択して、チケットクラス・性別・年齢から「生存したかどうか」の2値分類を行います。
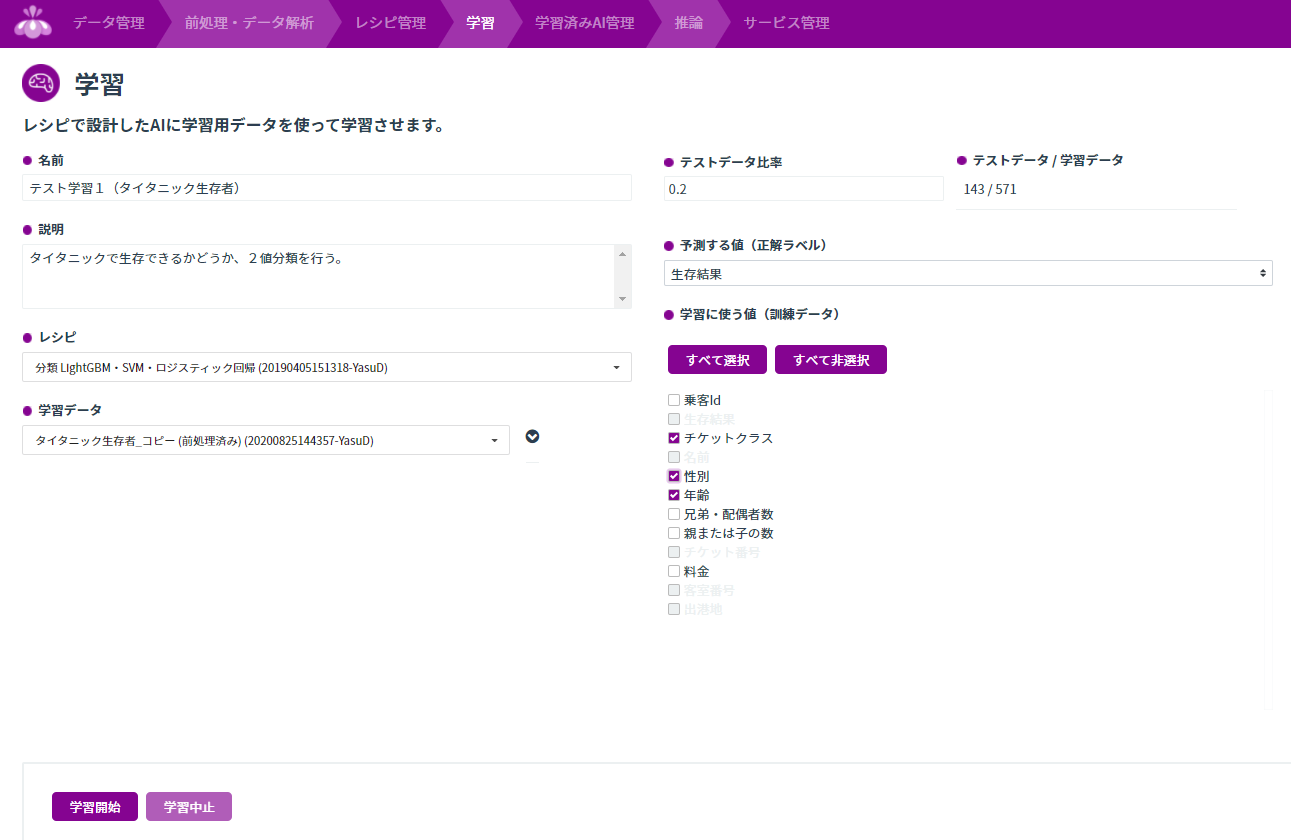
テストデータ比率を指定して自動で分けてくれるのは当然必要な機能ですが、やはり親切ですね。学習に使う値(訓練データ)には、欠損値がある列や数値データでない列は指定できません。
学習は0秒で終わりました。(通信に数秒かかります)

レシピ通り3種の方法でやってくれています。学習結果のマトリックスを見ると、どのクラスがどう間違われたのかが分かります。LightGBMはさすが、もっとも高いF値=0.85を出しました。何回か実行するとロジスティック回帰が勝つこともあります。
LightGBMの重要度を表示すると、学習に使用した各列の重要度やSHAP valueが見られます。
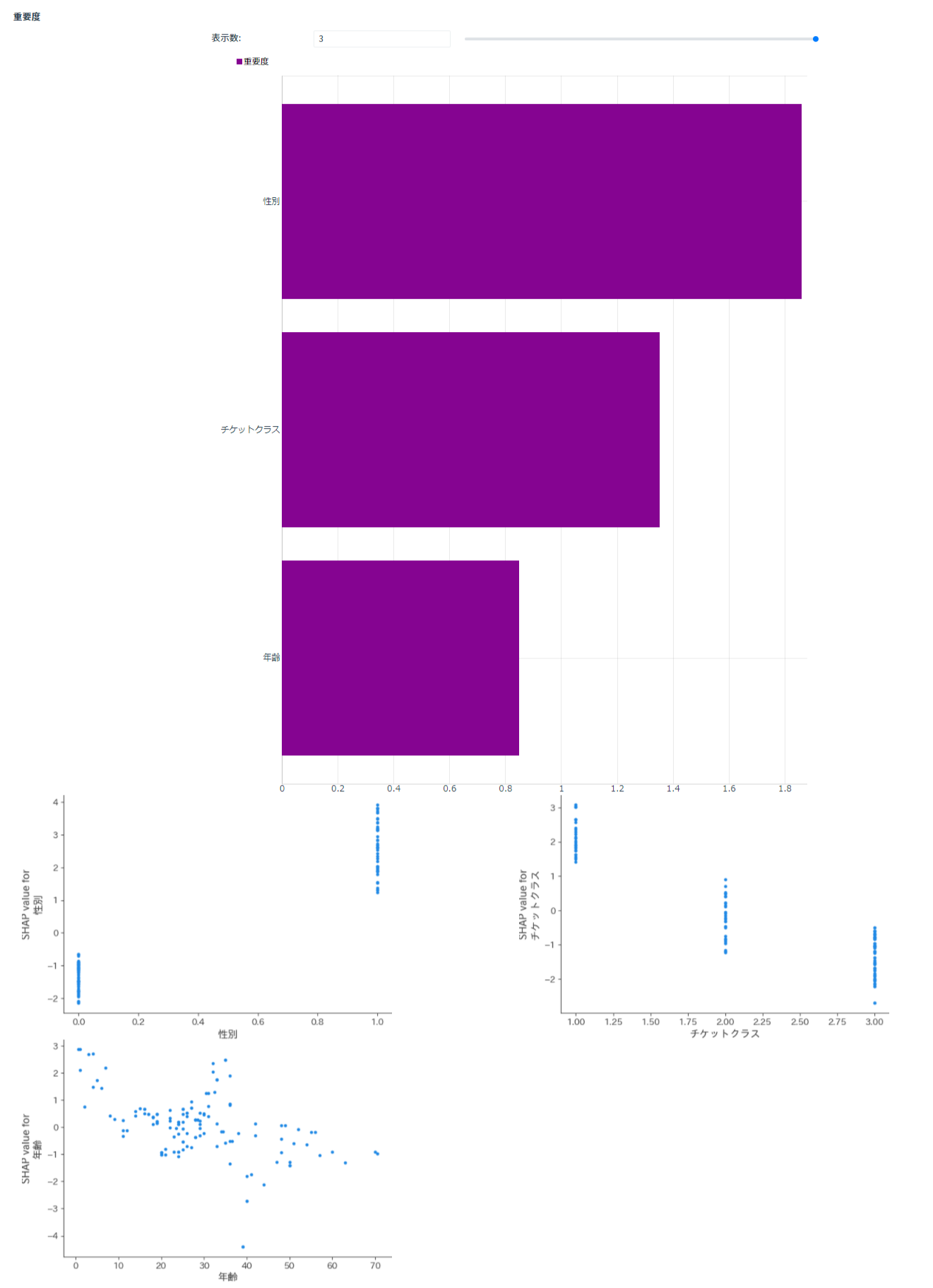
性別がもっとも「生存したかどうか」に関わるようです。
ちなみに「分類AutoFlow」のレシピを使った場合も似たような精度で、F値=0.88が出ることもありました。
学習済みAI管理
ここには過去の学習結果が並んでいます。重みは取り出せないようなので、有償版を途切れさせたら学習結果は消える感じですね。
推論の前に
5秒で考えた推論用データ(本番データ)を作成してアップロードしました。
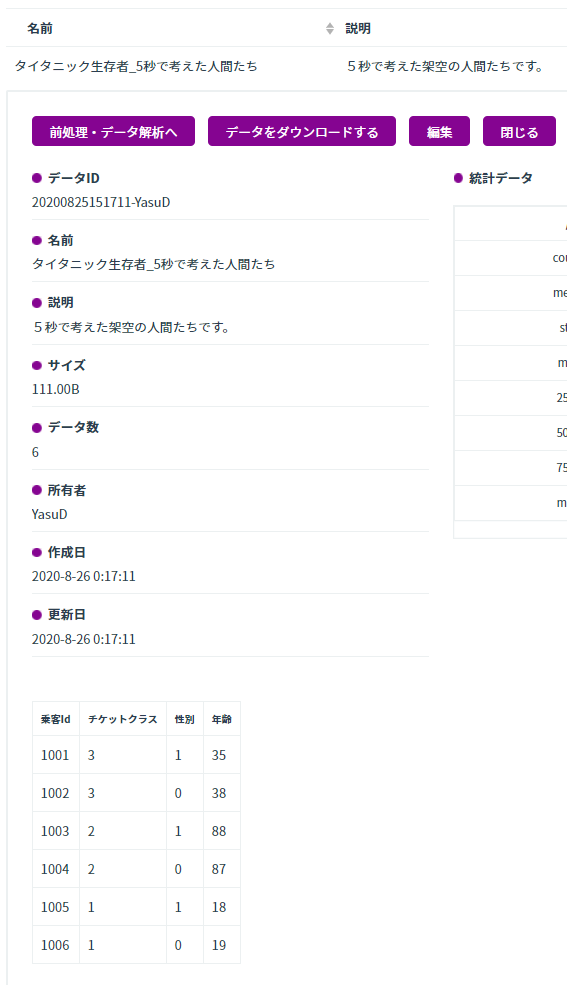
ちなみにチケットクラスは1が上級国民、3が労働階級です。性別は1が女です。30代の労働階級夫婦、米寿の中流階級夫婦、10代のボンボンカップルを想定しています。
推論
先の6人が生存できるか、学習済みのLightGBMを指定して推論してみます。列名は完全に一致していないと認識してくれません。
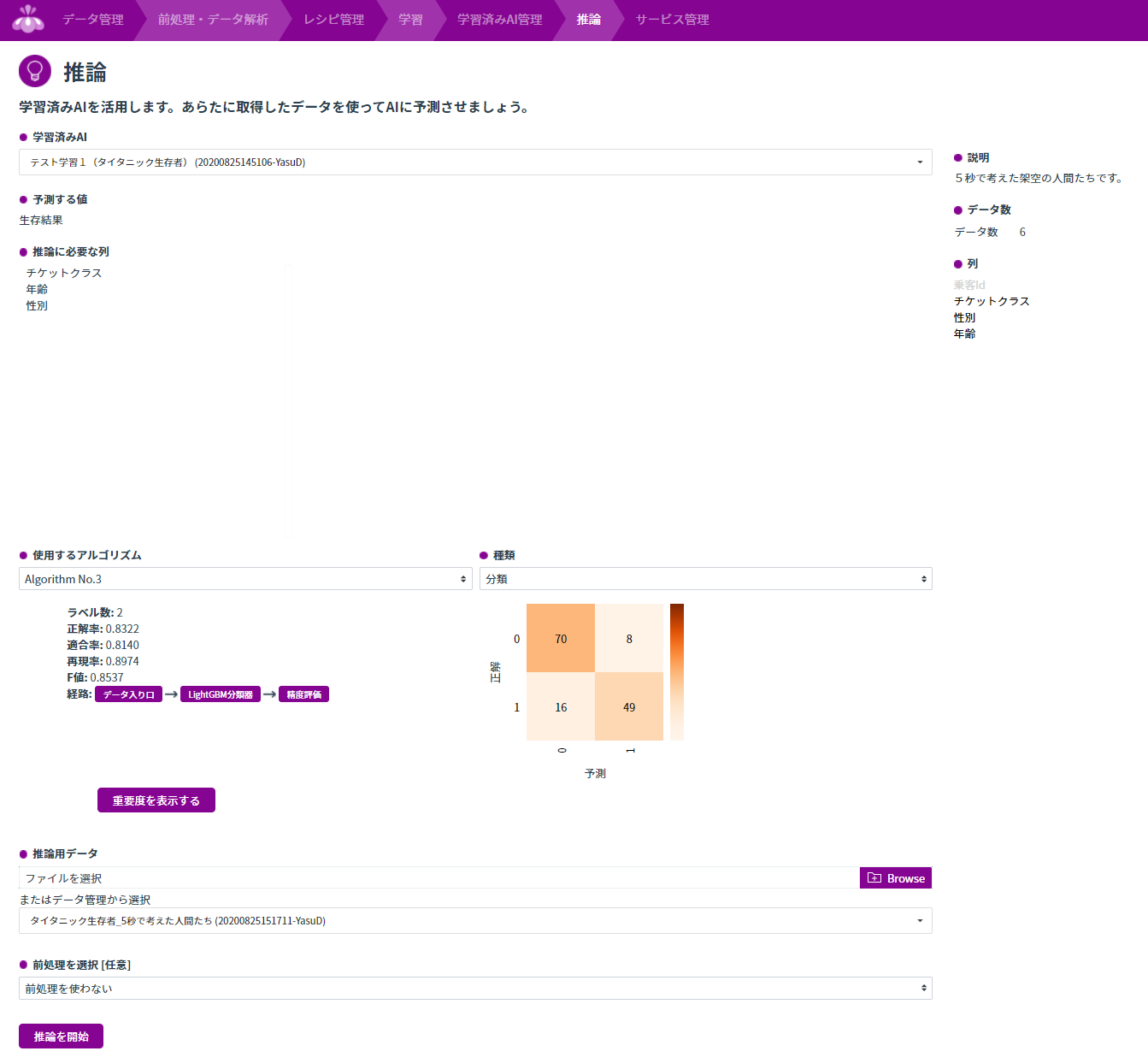
はい、想像通り女性は生存、男性は死亡です。興味深いことに、中流階級の男性よりもボンボンの男性のほうが生存期待値が少し高いです。まあ若くてお金持ちのほうが未来が
以上、サクッと2値分類ができました。
ケーキ画像の10クラス分類(前処理~学習)
次に、CNNによるケーキ画像の10クラス分類を試してみます。
画像の前処理
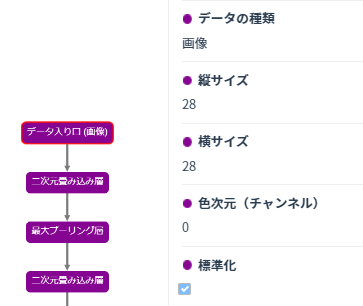
どうやら画像データの前処理はできないようなので、あらかじめ手元で適切に前処理する必要があります。無償版は学習レシピの編集や追加ができないので、デモ用の「白黒画像の10分類CNN」で指定されている28*28*1chにリサイズしました。(私がもっているリサイズプログラムを使用しました)(ちなみにこのサイズはMNISTを想定していますね)
画像データのフォルダ構成はマニュアルで確認しました。親フォルダ内にimagesフォルダを用意し、その中にクラス名のフォルダを並べます。
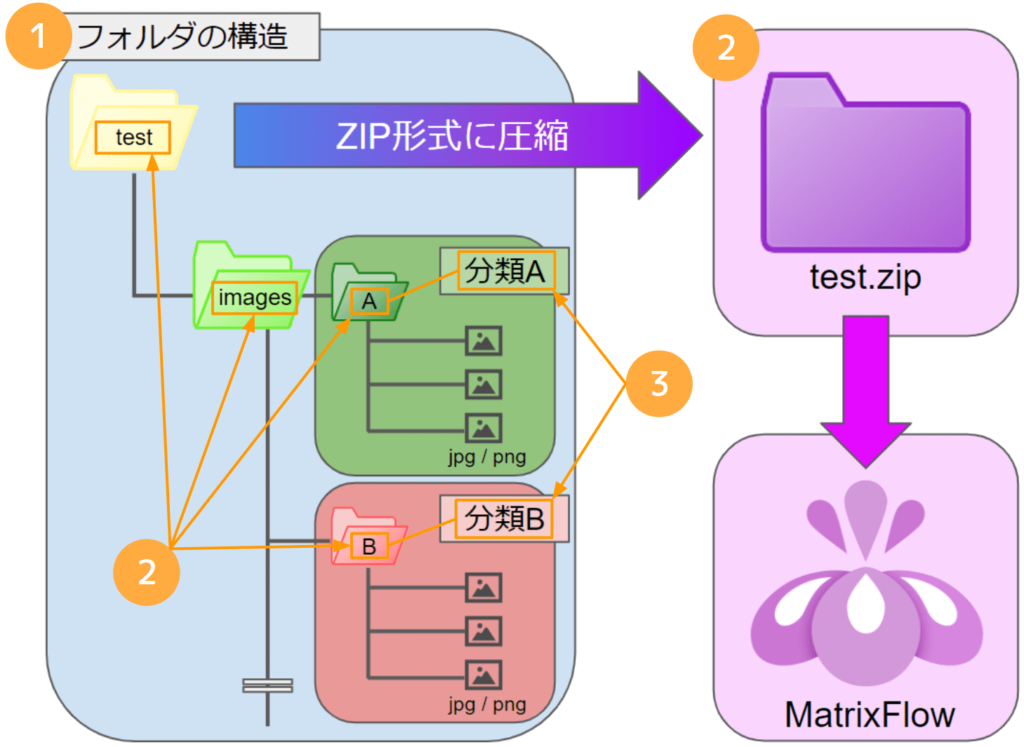
ケーキ画像は次のような10クラスです。
このサイズのグレースケールなので、精度は期待しません。
ZIP化してアップできました。フォルダ構成が間違っていると怒られます。
画像のCNN学習
CNNによるケーキ画像の10クラス分類を試してみます。設定は以下のとおりです。エポック数を記入するところで嫌な予感がしましたが、果たして・・・
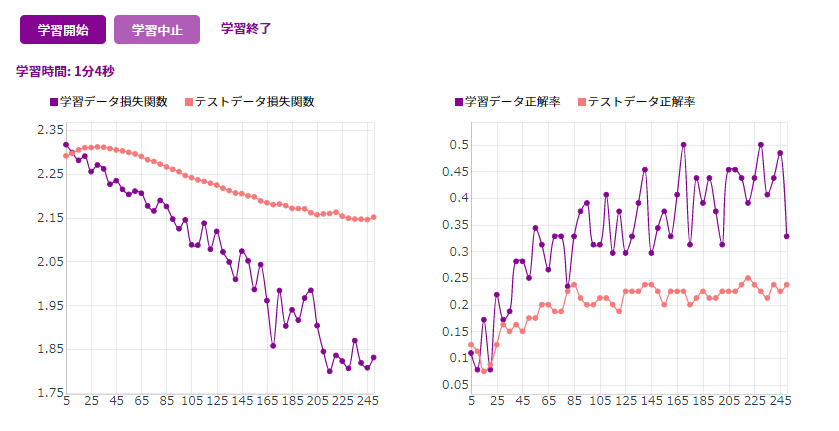
50エポックの学習は約1分で終わりました。学習曲線が表示されました。
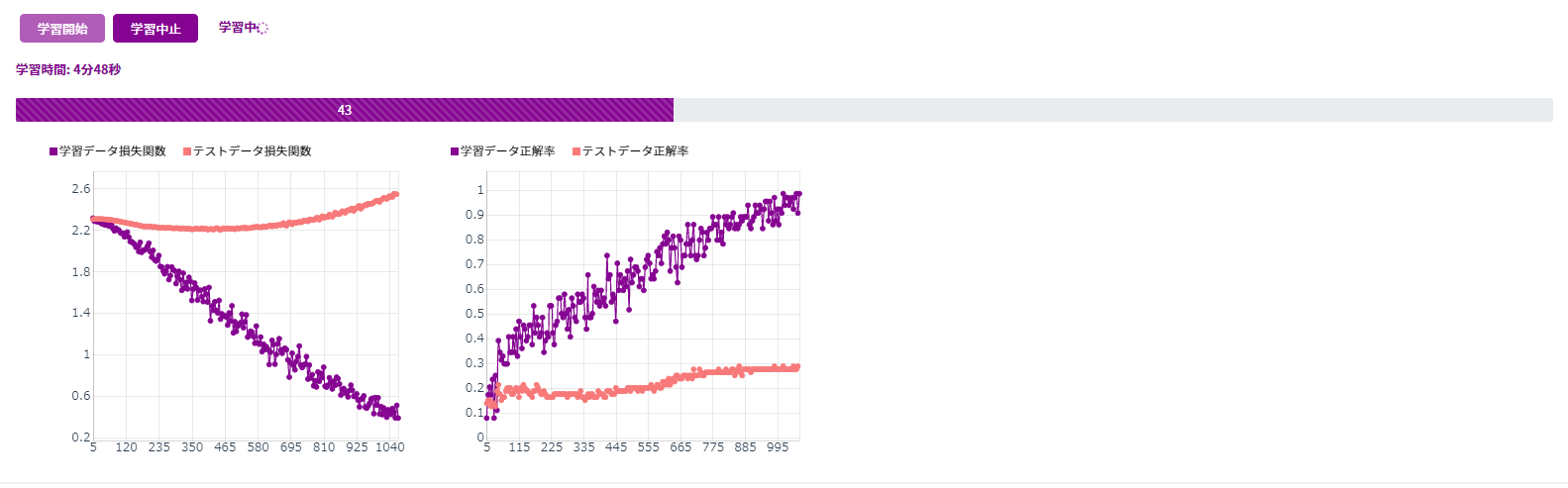
ふむ。嫌な予感を確かめるために500エポックでも学習してみます。進捗バーが進んでいきます。
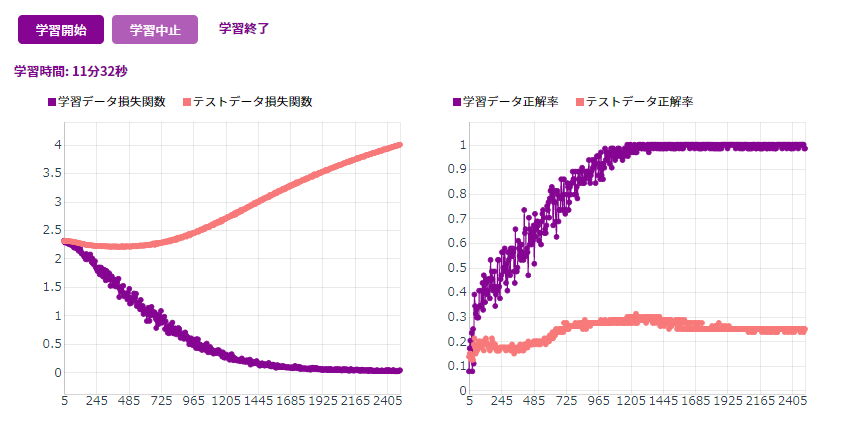
進捗を見ながら手動で中断できるようですが、待ってみると約11分で終わりました。なるほどこれは、過学習を防ぐ機能はなさそうです・・・!
ケーキ画像の10クラス分類(推論)
未知のケーキを10枚入れてみました。これらも同様に前処理しておきます。推論用画像のフォルダ構成はマニュアルにも書いてありませんでしたが、空気を読んで「親フォルダ/images/適当なフォルダ/10枚」にしたらいけました。

判定結果と各クラスの期待度が棒グラフで見られます。いいですね。
使い勝手・感想
無償版はしっかり制限がかかっていて最初のお試しという感じです。ごく一部しか試していないので、あまりフェアなことは言えないです。インストールから1時間程度で、しかもマニュアルをほとんど見ずにここまでの一連の流れができたのは、サービスとして素晴らしいことだと思います。
利用規約の確認
利用規約は変わりますので常に最新版をご確認ください。
(2020/10/08追記)あたかも個人情報が自由に利用・売却され得るかのような誤解を与える表現を掲載してしまいましたが、そのように個人情報が取り扱われることは一切ありません。謹んでお詫びを申し上げます。第17条(個人情報等の取扱い)第2項は、「個人情報については、個人が特定されないよう匿名化した上で、統計情報としてサービス向上のために利用することがある」という趣旨です。その他「プライバシーポリシー」もご参照ください。
(2020/11/30追記)ユーザーのデータやレシピの権利帰属に関する規約が改定されました。第10条(権利帰属)は「ユーザーがアップロードしたデータやユーザーが独自に創作したレシピの権利は当該ユーザーに帰属する」という趣旨です。
業務でも信頼して使うことができそうです。バックアップだけはしっかり取っておきましょう!
データの用意、クレンジング
欠損値の削除とテキストの数値ラベル化ができますが、ちょっと足すとか列を追加するとかはできません。あらかじめExcel等で「前前処理」をしておく必要があるでしょう。
画像の前処理はできません。画像の深層学習には通常1万枚以上が必要なため、前処理にはプログラミングがほとんど必須です。よって「プログラム不要のAI構築」は過言です。
学習に関して
学習レシピはGUIで組み立てられるようなので非常に簡単です(有償版のみ)。しかし、例えば深層学習用のパーツを見てみると、
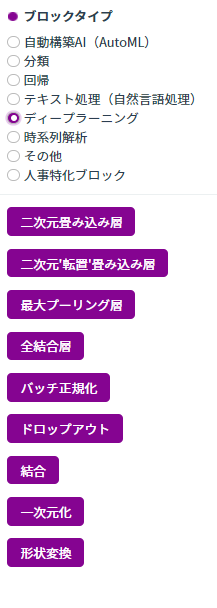
これしか用意されていません。経験者なら分かると思いますが、仕事にはならないです。。
また学習時間に関して、28*28*1chの400枚の画像を500エポック進めるのに11分かかりました。CPU使用率は上がっていなかったのでクラウド計算してくれていますが、例えば200*200*3chの1万枚の画像を500エポック進めるに何時間かかるでしょうか。。有償版だとより高速になるかもしれませんが、プランの比較が無いので分かりません。
その他さまざまな制限
短い時間でしたが、私がほしいと思った機能を列挙します。
- 分類において、テキストラベルも許容してほしい
- 深層学習において、過学習を防止してほしい(自動停止とか基本的な)
以下はなくてもいいと言えばいいのですが、現状の結果だけ見せられてもどう活用していいか微妙な感じがするので・・・
- 分類において、しきい値を変えたい
- 深層学習の結果をもう少し可視化してほしい(間違えたサンプル一覧など)
中間層を可視化したい!とか自動でハイパーパラメータのチューニングをして!とか面倒なことは申しません。しかし上で挙げた基本的な機能は、定食メニューで言えばおしぼりやお味噌汁かなと思います。
総評
外野のくせに生意気言って大変申し訳ないですが、お世辞にも利用したいサービスとは言えません。いろいろなAI学習を広く浅くという印象で、サービスとして発展途上です。社内でちょっとデータ分析やAI学習を試すには良いと思いました。ただし2020年8月現在形だけのAI学習です。
想定される用途として、AI学習の雰囲気を掴んで専門家との議論に備えるのに最適だと思います。
また、他のサービスにも共通して言えることですが、得られた正解率、適合率、再現率、F値は何を意味していて、どういう場面でどれを重視すればよいのか。深層学習の各パーツはどう選べばいいのか。このような解釈や判断はユーザーに任されます。
今後の発展に期待大といったところです。

