
やること
筆者は宗教上の都合でAWSに触ることができないのですが、仕事ではそうも言ってられず、S3にファイルをアップするくらいの作業は行います。(なぜそんな宗教に入信したかについてはまたどこかで説明しなければならないと思いますが)
皆さん思うでしょう。「ファイルのアップロードくらいは問題ないだろう」と。
しかしAWSはそんな甘い世界ではありません。もしあなたがそんな甘い考えでAWSに触れようとしているのであれば(自主規制)
今回はS3に大量の画像ファイルをアップロードしてブラウザからアクセスする方法をメモします。
環境
Windows10(64bit版)
何が問題なのか?
ブラウザを開き、AWSのマネジメントコンソールからS3に入ります。
バケットに入ります。初めて使う場合はバケットを作成します。
フォルダやファイルが並んでいます。ここに新しく「result_save」という約1.4GBのフォルダをアップロードしたいと思います。
「アップロード」ボタンから手続きを進めます。このとき「160GBよりも大きいファイルをアップロードするにはCLIを使用します」という注意書きが見えますが、1.4GBなので「次へ」でアップロードを実行します。
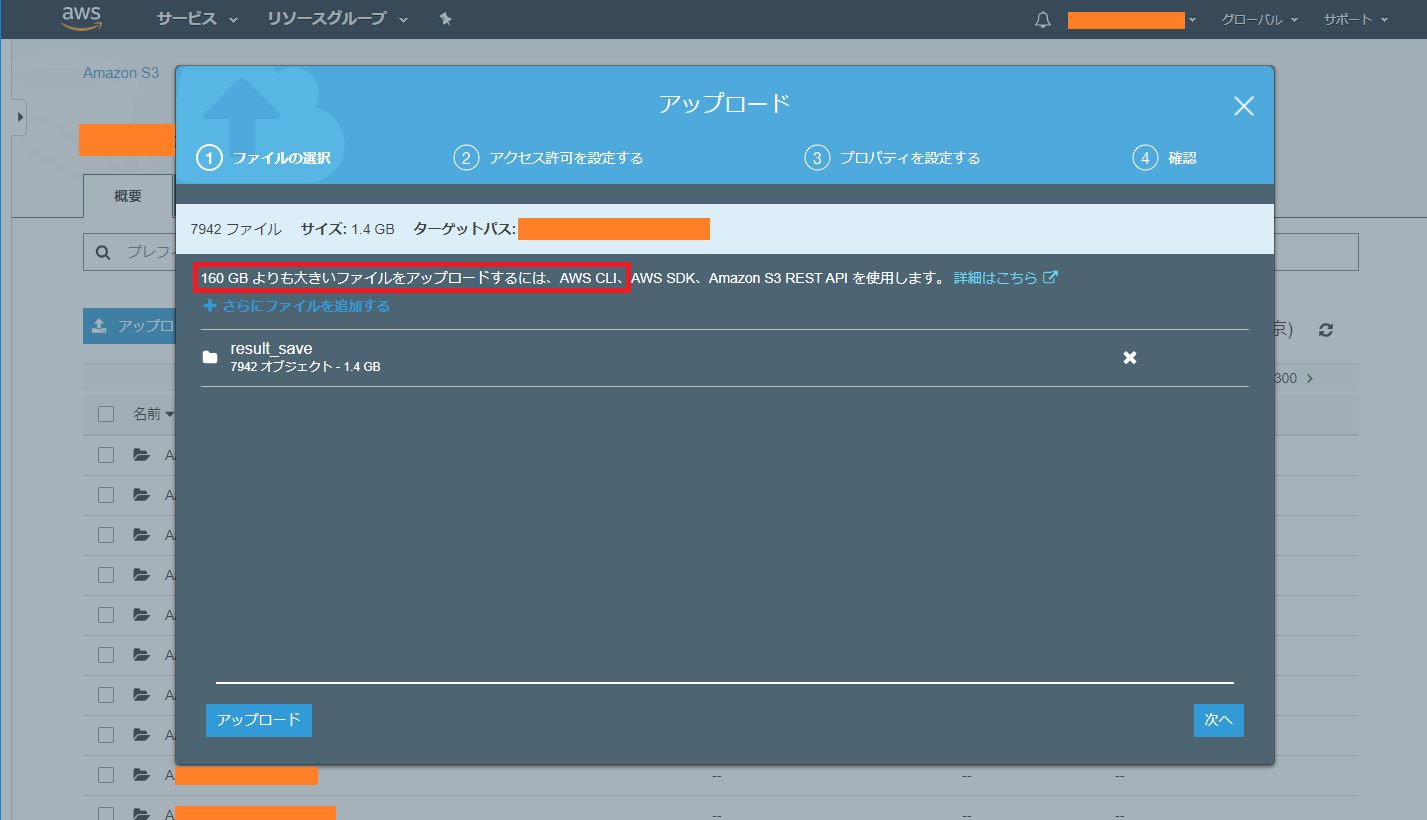
画面下部にアップロードの途中経過が表示されます。
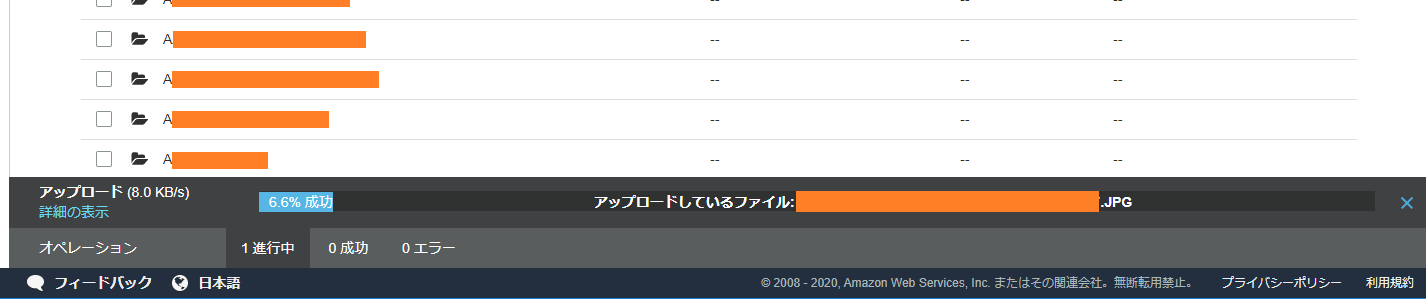
さて、結論から言うとアップロードは失敗します。通信環境にもよりますが、速度が10~100KB/sのため「一晩放置しておけば終わるか」と思っていると、なぜかだんだん速度が落ちてきて、朝起きても20%台で油を売っていることがよくあります。あるいはページがクラッシュして失敗しています。
AWSエンジニアの方に泣きついたところ、CLIを使用せよとのこと。何MB以上のファイルでCLIを使用すべきかの基準は分かりませんが、プロがそう言っているのだからそうなのです。
FTPクライアントソフトを使うことも考えましたが、プロがCLIと言うからにはCLIです。AWS関係のトラブルを自分の考えで解決しようとするのはナンセンスです。百戦錬磨のサーバー担当者もボロボロ躓きます。それくらい、AWSはその辺の仮想サーバーとは質的に異なります。AWSエンジニアの言うことには絶対的に従うべきです。
CLIのインストール
正直なところ、CLIが何を意味しているのかはよく分かりません。ただ、理解する必要はありません。AWSには特殊な用語が星の数ほどあって、意味を調べてもキリがないからです。CLIとかIAMとかの略語はもちろん、S3やEC2といったサービス名もすべて固有名称です。
Windows10へのCLIのインストールは次のページのステップ1~3に従います。

CLIの設定
手元のPCと遠くにあるS3を紐付けて、ファイルをアップロード可能な状態にします。
次のページの「aws configure を使用したクイック設定」に従います。アクセスキーIDとシークレットアクセスキーの取得方法も載っています。

フォルダのアップロード
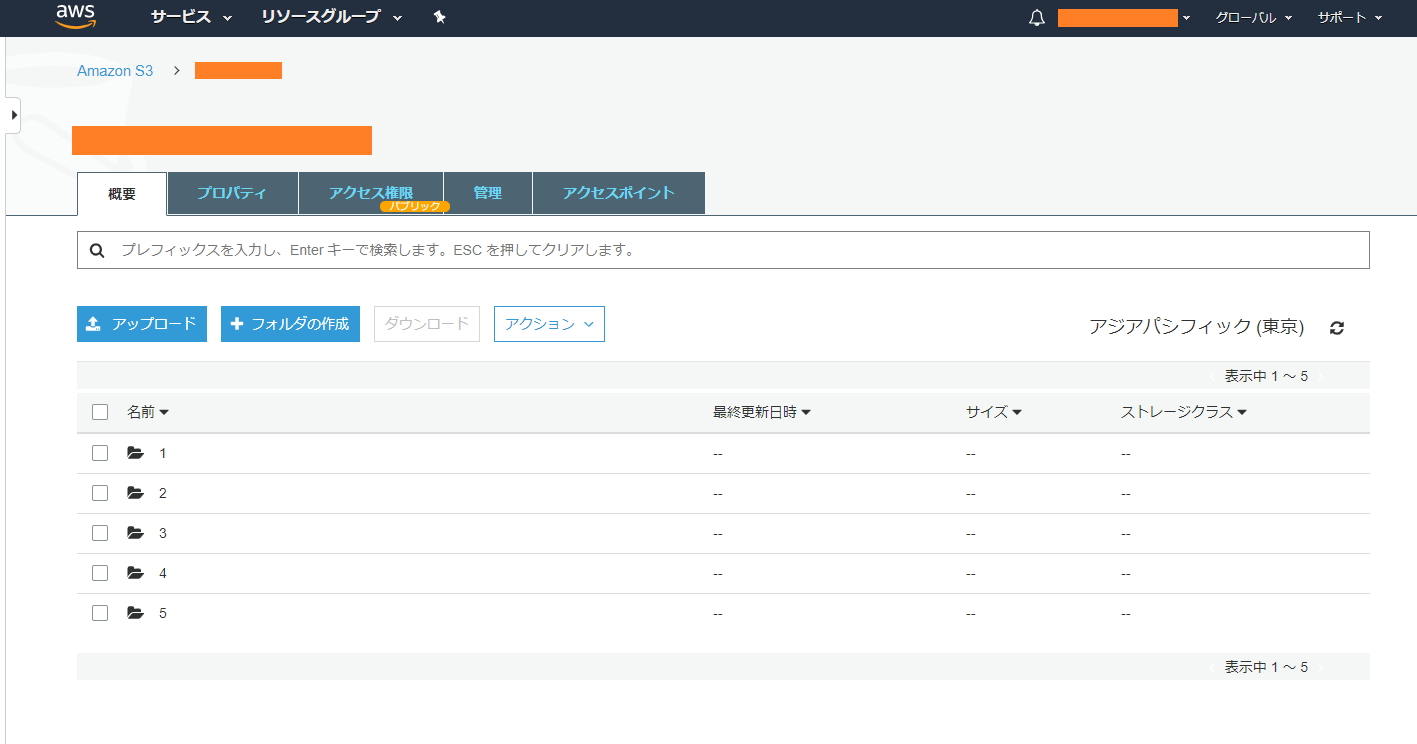
指定の親フォルダの中身をアップロードします。ここでは「result_save」の中にある5つのフォルダをアップロードします。
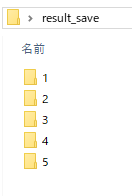
Windowsのコマンドプロンプトを開き、対象の親フォルダがある場所に移動します。親フォルダのプロパティからパスをコピーし、cdのあとに貼り付けると楽です。
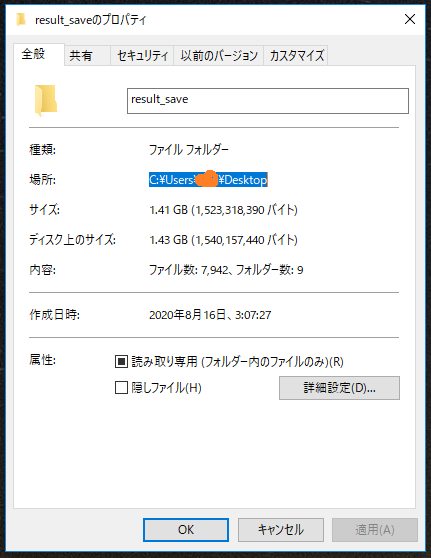
cd パスアップロードのコマンドです。親フォルダより下の内容をアップします。バケット内のさらに下の階層にアップしたい場合はそのようにパスを指定すれば良いのではないかと思います。
aws s3 sync result_save/ s3://あなたのバケット名/通信環境にもよりますが、私の場合は1.4GBが8分程度で完了しました。※追記:120GBだと6時間程度でした。
パブリックアクセスとバケットポリシーの設定
画像ファイルにはURLが割り当てられていますが、このままではブラウザからアクセスできません。URLを叩くとこんな感じ。

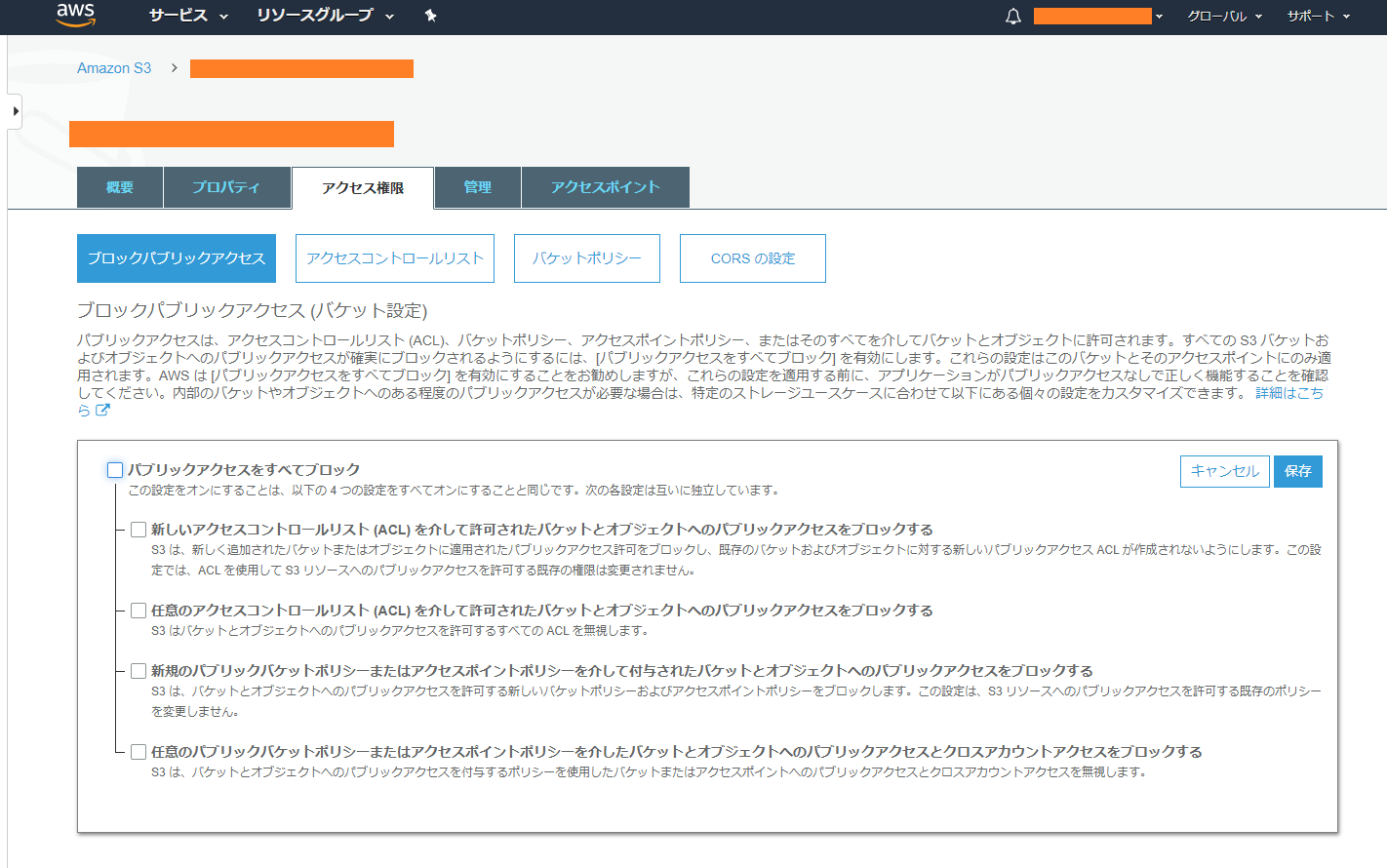
アクセス権限>ブロックパブリックアクセスから、すべてのブロックを解除して保存します。
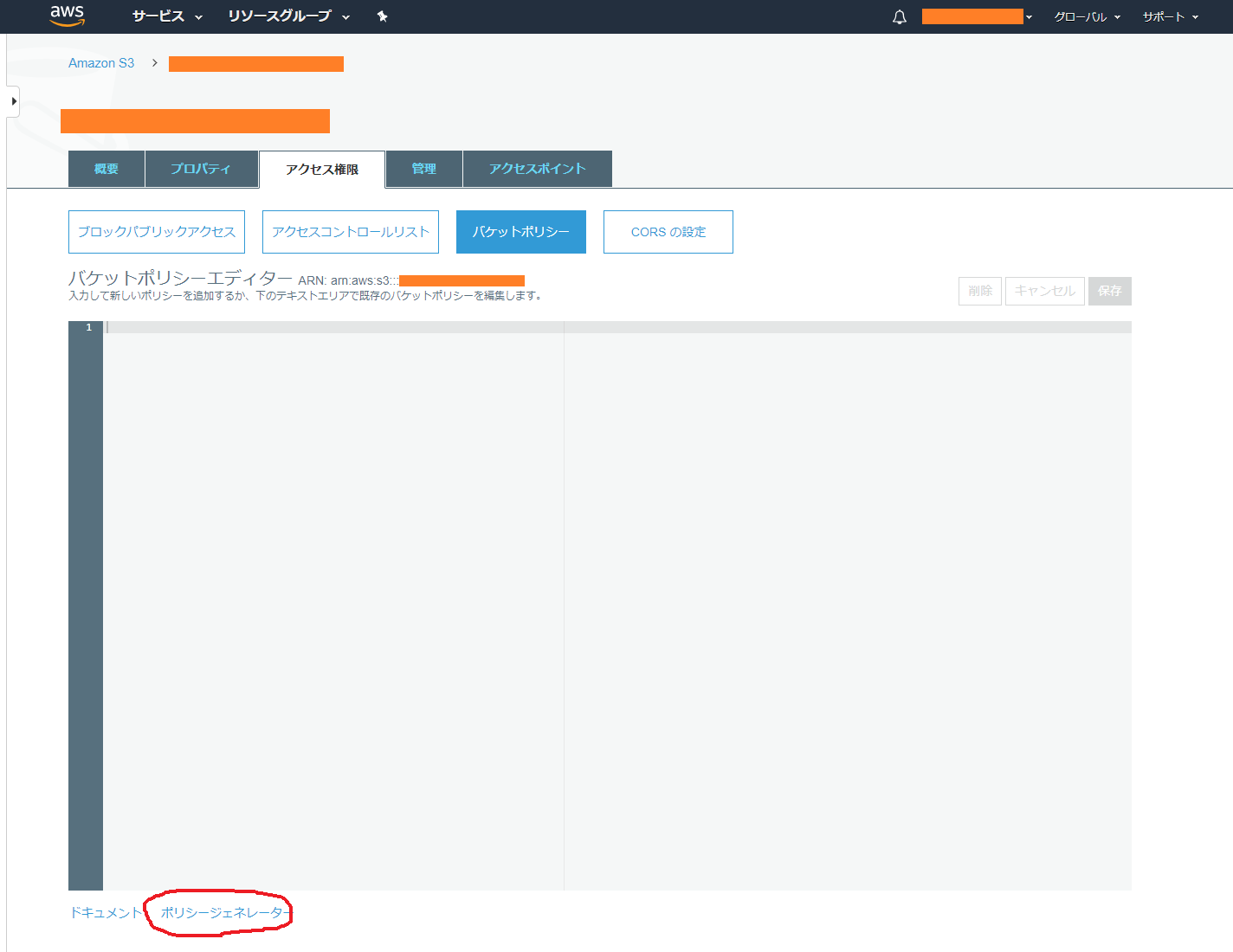
アクセス権限>バケットポリシーから、ポリシージェネレーターに飛びます。
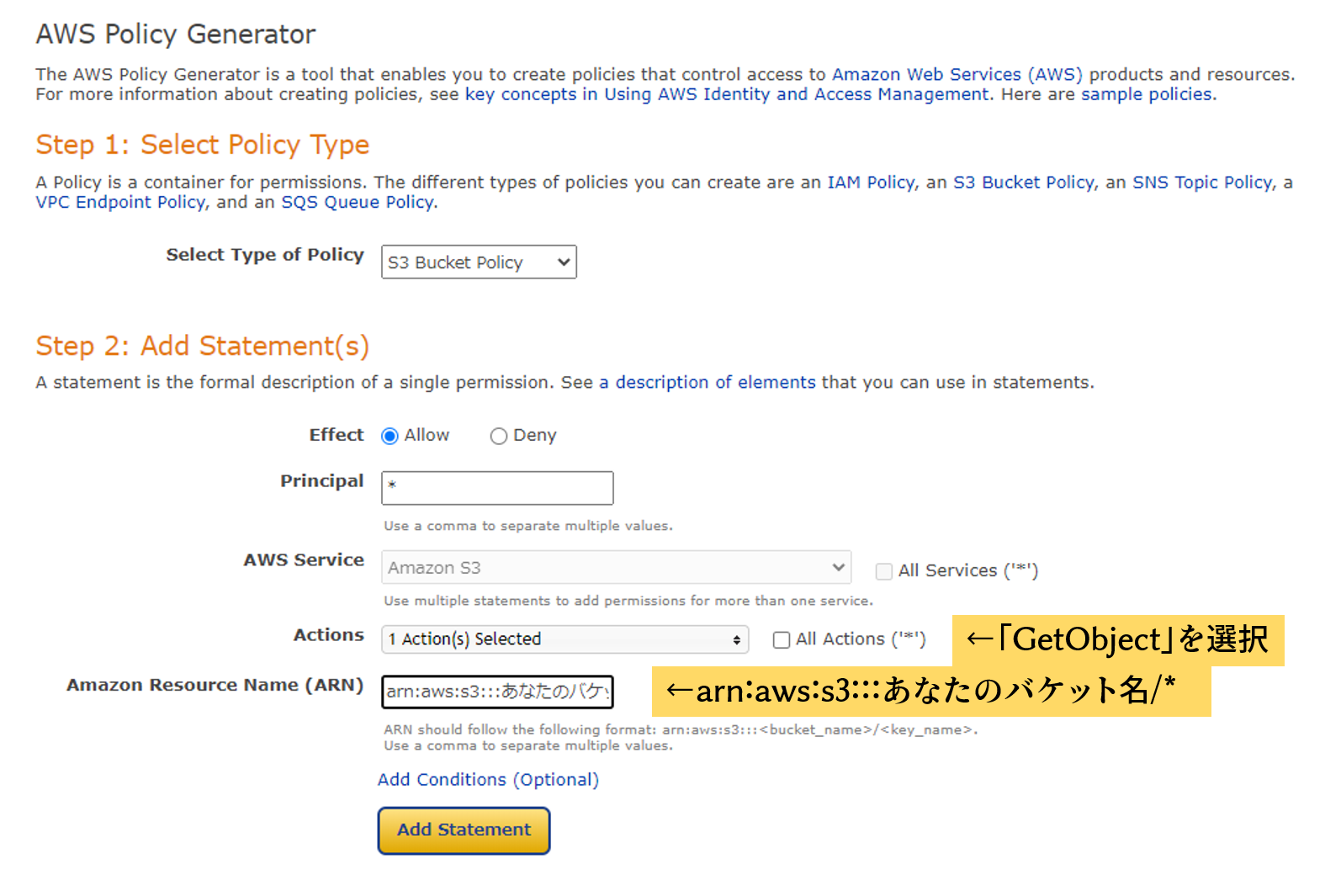
次の内容で「Add Statement」を押し、さらに「Generate Policy」を押します。
記述部分はこんな感じ
arn:aws:s3:::あなたのバケット名/*生成されたおまじないを先ほどのバケットポリシーエディターに貼って保存します。
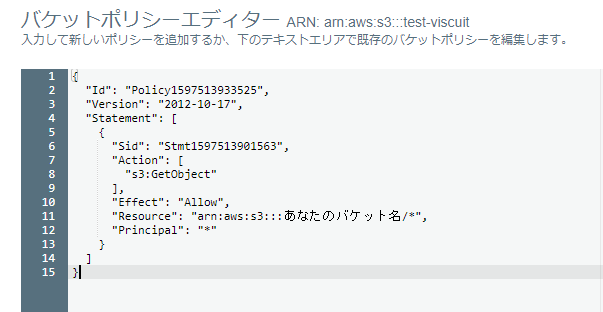
こんなおまじないです。
{
"Id": "Policy1597513933525",
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1597513901563",
"Action": [
"s3:GetObject"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::あなたのバケット名/*",
"Principal": "*"
}
]
}これでブラウザからS3上の画像にアクセスできるようになりました。バケット名や配下のフォルダ構造、ファイル名が流出したら誰でもアクセスできる状態ですので、このあたりのアクセス権限の設定は別途がんばってください。
まとめ
「AWSなんて数ある仮想サーバーの一つでしょ」と思っていると痛い目に遭います。AWSはあなたがコツコツと積み上げてきたサーバーの知識やテクニックが通用しない領域です。分からないときは素直にAWSエンジニアにお願いしましょう。