
初心者でもできちゃった
今回は、勉強会によく参加してくださっているkokido様に提供していただいた内容を記事にしています。
「はじめて自分でPython書いたのに最適化できちゃいました。プログラミングは初心者で、10年以上前にPHPを触ったくらいで」

「でもコピペしてググればだいたいできますね」
初心者でも最適化できるのがvcoptです。
やること
商品が20種類ある。でも棚には10種類しか置けない。どの商品を置いたら売上が最大になるだろう?

自動販売機にどの飲み物を置くか、やっぱり迷いますよね。単に人気の飲み物を並べれば良いわけではありません。第1希望の飲み物がなかった場合も考慮して、できるだけ売上の期待値が大きくなる組み合わせを見つけたいです。
20種の商品から10種を選ぶ組み合わせは184,756通りです。総当たりでも行けそうですが、より複雑な問題を視野に入れて、遺伝的アルゴリズムを使って最適化してみましょう。
消費者の購入ルール
消費者は次のルールにしたがって商品を購入するとします。
- 第1希望の商品が置いてあれば1つ買います
- 第1希望の商品が置いていない場合は、代わりに買ってもよい商品(代替商品)を1つ買います
- 代替商品も置いていない場合は何も買いません
購入意向率のデータ(第1希望の商品)
アンケート調査を行ったと仮定して、こちらのサンプルデータを用意しました。
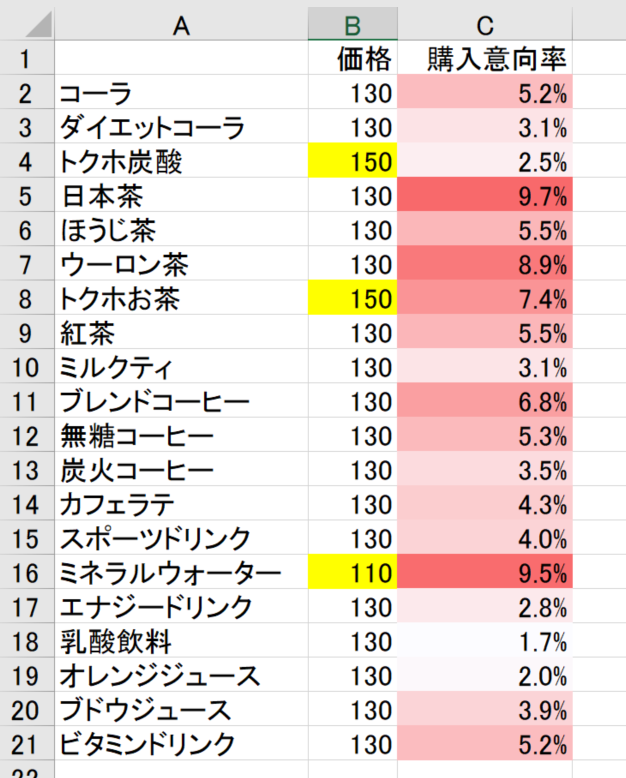
「人類の5.2%はコーラを第1希望に選ぶ」といったイメージです。
やはり日本茶と烏龍茶の人気は不滅ですね。ミネラルウォーターも価格メリットがあって人気です。一方で、乳酸飲料は自動販売機ではイマイチのようです。
ちなみに、これら全商品(20種)を置くと期待売上は130.1円になります(ほとんど130円だから…)。
代替購入率のデータ(第2希望の商品)
こちらもサンプルデータを用意しました。
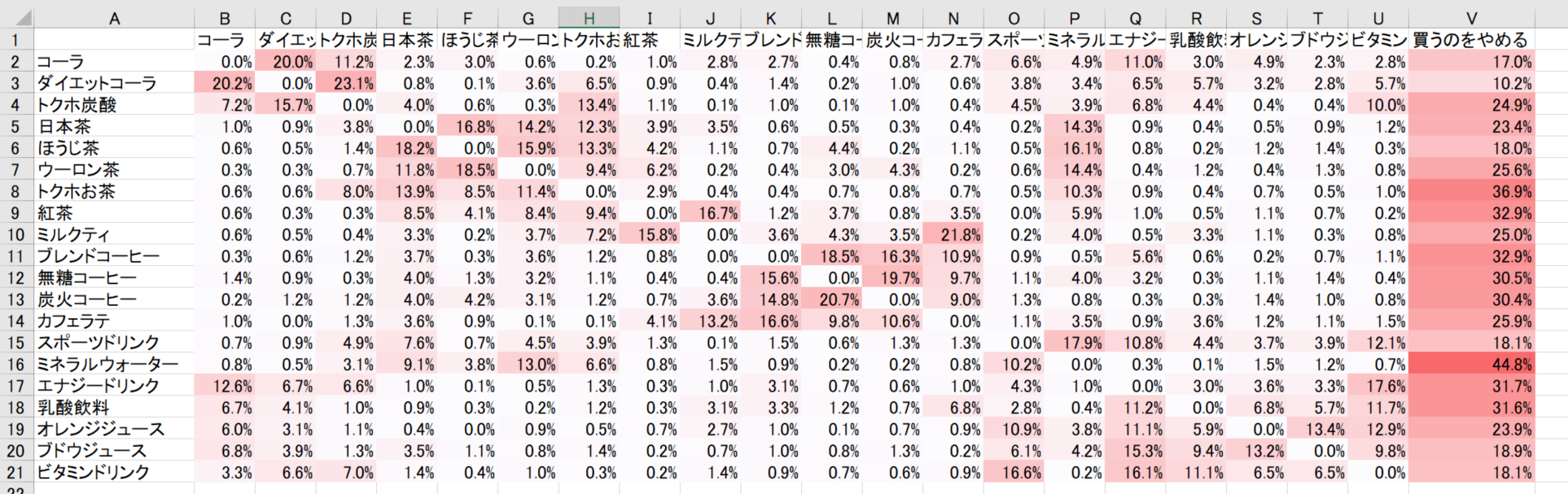
コーラを買いたかったのにコーラがない場合、20%の人がダイエットコーラ、11%の人がトクホ炭酸を選ぶようです。同様に、紅茶対ミルクティ、各種コーヒー間も関連が高いですね。
一方でミネラルウォーター派はストイックです。妥協しても烏龍茶、いや、45%の人が買うのをやめるようです。
ジュース派はジュースがなければエナドリを買うようですが、エナドリ派はエナドリがないからといってジュースは買わず、コーラかビタミンドリンクに行くようです。このデータ、リアリティ高すぎません?
実行環境
WinPython3.6をおすすめしています。

vcoptの使い方についてはチュートリアルをご参照ください。

vcoptの仕様については最新の仕様書をご参照ください。本記事執筆時とは仕様が異なる場合があります。

pip, import
今回使うパッケージをインポートします。
import copy
import numpy as np
from vcopt import vcopt
import matplotlib.pyplot as pltパラメータ設定とデータの読み込み
並べる商品の数は変えられるようになっています。購入意向率と代替購入率のデータを読み込みます。
#============================
#パラメータ
#============================
#購入意向商品ファイル
p_file = 'p_rate.txt'
#代替意向商品ファイル
ap_file = 'ap_rate.txt'
#並べる商品の数
space=10
print('並べる商品の数:{}'.format(space))
#============================
#購入意向率の読み込み
#============================
#ファイル名
file = open(p_file, 'r')
#1行目はラベルなのでカラ読み
file.readline()
#2行目以降を読み込む
p_data = []
while 1:
tmp = file.readline().split()
if len(tmp) > 1:
p_data.append(tmp)
else:
break
file.close()
print('購入意向率リスト数:{}'.format(len(p_data)))
print('購入意向率リスト:{}'.format(p_data))
#============================
#代替購入率の読み込み
#============================
#ファイル名
file = open(ap_file, 'r')
#1行目のラベルを読み込む
ap_label = file.readline().split()[:20] #空の一列目はsplit()で除かれる
#2行目以降を読み込む
ap_data = []
while 1:
tmp = file.readline().split()[1:] #一列目は商品名なので除く
if len(tmp) > 1:
ap_data.append(tmp)
else:
break
file.close()
print('代替購入率リスト数:{}'.format(len(ap_data)))
print('代替購入率リスト:{}'.format(ap_data))並べる商品の数:10
購入意向率リスト数:20
購入意向率リスト:[['コーラ', '130', '0.052108315'], ['ダイエットコーラ', '130', '0.03097605'], ['トクホ炭酸', '150', '0.024860904'] (以下略)
代替購入率リスト数:20
代替購入率リスト:[['0', '0.200141834', '0.112154408', '0.02278213', (以下略)数字も文字列として読み込みました。あとで計算時に数字に戻します。
評価関数
売上の期待値を算出します。
#============================
#評価関数
#============================
def p_score(para):
#paraは商品IDが並んだ[1,5,9,11,18]のような形で与えられる
#並ばない商品のリストを作っておく
#全商品IDリスト
all = list(range(1, len(p_data) + 1)) #全商品ID
#並ばない商品IDのリスト
non_s = list(set(all) - set(para)) #paraに含まれない商品ID
#重複は除く
para = list(set(para))
#スコア計算
score = 0
for i in para:
#意向商品売上計算
score += (float(p_data[i-1][1]) * float(p_data[i-1][2]))
#代替商品売上計算 (価格×j商品を買いたい割合×その人がi商品を買う割合)
for j in non_s:
score = score + (float(p_data[i-1][1]) * float(p_data[j-1][2]) * float(ap_data[j-1][i-1]))
return score
#テスト用
para = [1,15]
score = p_score(para)
print(score)27.239935431509817試しにコーラとミネラルウォーターだけを置いてみると、27.2円が返ってきました。
紙とペンで計算すると、第1希望としての売上期待値は、コーラが130円×5.2%=6.8円、ミネラルウォーターが110円×9.5%=10.5円。他の商品が欲しかったけど第二希望でコーラに流れてきたお客さんは全体の2.3%(要計算)なので、第2希望コーラは130円×2.3%=2.9円。同様に第2希望ミネラルウォーターは110円×6.4%=7.0円。よってこれらの合計は27.2円で合っています。
(任意)可視化関数
poolを受け取って、100体まで評価値をプロットします。
#============================
#poolの可視化関数
#============================
def p_show_pool(pool, **info):
#GA中の諸情報はinfoという辞書に格納されて渡されます
#これらを受け取って使用することができます
gen = info['gen']
#best_index = info['best_index']
best_score = info['best_score']
mean_score = info['mean_score']
#mean_gap = info['mean_gap']
time = info['time']
#各poolのスコアを計算(100体まで)
scores = []
for para in pool[:100]:
scores.append(p_score(para))
#棒グラフでプロット(100体まで)
plt.figure(figsize=(12, 6))
plt.bar(range(len(pool[:100])), scores)
#タイトルをつけて表示
plt.title('gen={}, best={} mean={} time={}'.format(gen, best_score, mean_score, time))
plt.ylim([0, 130])
#plt.savefig('save/{}.png'.format(gen))
plt.show()
print()まずはランダムでがんばる
まずはランダムな組み合わせを1000回試して、平均期待売上と最大期待売上を表示してみます。
#============================
#ランダムに1000回施行したときのベスト
#============================
scores = []
score_best = 0
para_best = []
for i in range(1000):
para = np.random.choice(range(1, len(p_data) + 1), 10, replace=False)
score = p_score(para)
scores.append(score)
if score > score_best:
para_best = copy.deepcopy(para)
score_best = copy.deepcopy(score)
#結果表示
print('平均期待売上:{:.3f}円'.format(np.mean(scores)))
print('最高期待売上:{:.3f}円'.format(score_best))
para_best.sort() #並べ替え
for i in para_best:
print('{}.{} '.format(i, ap_label[i - 1]), end='')
print()平均期待売上:90.059円
最高期待売上:104.100円
1.コーラ 6.ウーロン茶 7.トクホお茶 8.紅茶 10.ブレンドコーヒー 11.無糖コーヒー 13.カフェラテ 15.ミネラルウォーター 16.エナジードリンク 20.ビタミンドリンクつまり何も考えずに商品を置くと期待売上90円で、ものすごいベテランが珠玉の10商品をセレクトするとだいたい期待売上104~105円くらいになるということでしょうか。
GAで最適化
GAを実行します。
#============================
#最適化実行
#============================
#パラメータ範囲
para_range = [[i for i in range(1, len(p_data) + 1)] for j in range(space)]
#GAで最適化
para, score = vcopt().dcGA(para_range, #para_range
p_score, #score_func
99999, #aim
show_pool_func=p_show_pool, #show_para_func=None
seed=None, #seed=None
pool_num=200) #個体数を指定
#結果表示
print('期待売上:{:.3f}円'.format(score))
para.sort() #並べ替え
for i in para:
print('{0}.{1} '.format(i,ap_label[i - 1]), end='')
print()実行結果

期待売上:108.273円
1.コーラ 4.日本茶 6.ウーロン茶 7.トクホお茶 8.紅茶 10.ブレンドコーヒー 11.無糖コーヒー 13.カフェラテ 15.ミネラルウォーター 20.ビタミンドリンク 期待売上は108円となりました。お見事です。
きちんと解析してみないと詳しいことは言えませんが、エナジードリンクを不採用とした点がポイントでしょうか。エナドリは第2希望として優秀ですが、コーラ、ジュース系、ビタミンドリンクの代替ですので、このラインナップにおいては力を発揮しづらいようです。
実用に向けて
アンケートデータがあれば一応最適化できるようになりました。
今後は以下のようなことをして実用に近づけていきたいですね。
- 代替商品を複数設定したい(第3希望以降も考慮したい)
- 代替商品だと消費者の満足度が下がるので、それも考慮したい
- 実際の売り場の商品数(50商品から20商品選ぶとか)でも最適化できるか確認したい
追記
vcopt().setGA()が実装されました!dcGA()よりも数倍早く最適化できます。
#============================
#最適化実行
#============================
#パラメータ範囲
para_range = [i for i in range(1, len(p_data) + 1)]
#GAで最適化
para, score = vcopt().setGA(para_range, #para_range
space, #set_num
p_score, #score_func
99999, #aim
show_pool_func=p_show_pool, #show_para_func=None
seed=None, #seed=None
pool_num=200) #個体数を指定
#結果表示
print('期待売上:{:.3f}円'.format(score))
for i in para:
print('{0}.{1} '.format(i,ap_label[i - 1]), end='')
print()