
やること
プログラミング不要のAI構築Webサービス「Matrixflow」の有料版を使って過去ツイートのワードクラウドを作成する手順を備忘録として残しておきます。過去ツイートのワードクラウドを作成するサービスはいくつかあるようですが、ワードクラウドの見た目が好みなのでMatrixflowを選びました。
※ワードクラウドの作成は無料版でもできますが、有料版ではレシピの編集ができるためパラメータがいじれます。
※ワードクラウドを作成するためだけに有料版を契約する人なんているわけがない←
過去ツイートの取得
Twitterを次のサービスと連携させ、過去ツイートが含まれるcsvファイルを取得します。

https://analytics.twitter.com/
analytics.twitter.com
1ヶ月間ずつしか取得できないので、繰り返し頑張ります。
テキストの前処理
次のPythonコードで、Matrixflowに入力可能な形式に自動処理します。コードは整理していません。
import numpy as np
import os
#この階層にあるcsvを読む
files = os.listdir('./')
print('files:\n{}'.format(files))
data = []
for file in files:
if file[-4:] == '.csv':
print(file)
with open(file, 'r', encoding='utf_8') as f:
#1行目はラベルなのでカラ読み
f.readline()
#一時行
line = ''
while 1:
#真の1行を見極める処理
#改行コードまで読む
tmp = f.readline()
#空なら終了
if len(tmp) < 1:
break
#一時行に合体
line += tmp
#カンマを数えて39個あれば
if line.count(',') >= 39:
#改行コードを置き換える
line = line.replace('\n', ' ')
#ツイート部分を取得
line = line.split(',')
data.append(line[2])
#一時行をリセット
line = ''
else:
#39個なければさらに読み進める
pass
data = np.array(data)
print('len(data):\n{}'.format(len(data)))
print('data[:5]:\n{}'.format(data[:5]))
#保存ディレクトリ作成
if not os.path.isdir('text_train/'):
os.makedirs('text_train/')
if not os.path.isdir('text_train/texts/'):
os.makedirs('text_train/texts/')
if not os.path.isdir('text_train/texts/twitter/'):
os.makedirs('text_train/texts/twitter/')
#保存
count = 0
for i in range(len(data)):
path = 'text_train/texts/twitter/{}.txt'.format(count)
with open(path, mode='w', encoding='utf-8') as f:
text = data[i].split('"')[1]
print(text)
f.write(text)
count += 1この状態で実行すると、
このフォルダが生成されます。各ファイルに個別のツイートが入っています。
Matrixflowでワードクラウドの作成
先ほど生成された「text_train」フォルダをZipにしてアップします。
レシピは最小構成で、ストップワードに彼/彼女とか良さげなワードも含まれてしまっていますがとりあえずデフォルトのまま。赤丸のところは試してみたところ0.01%や0.02%が良さそうでした。

結果
お二方にご協力いただきました。
F. I.さん
10751ツイートを使用。
0.01%。がんばってください!
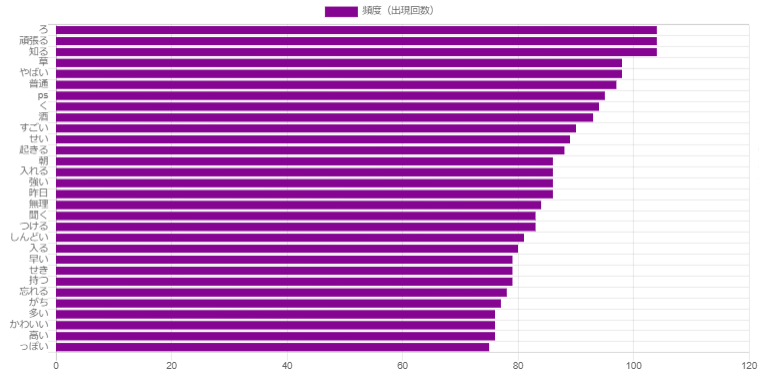

0.02%。やっぱりおやすみなさい!
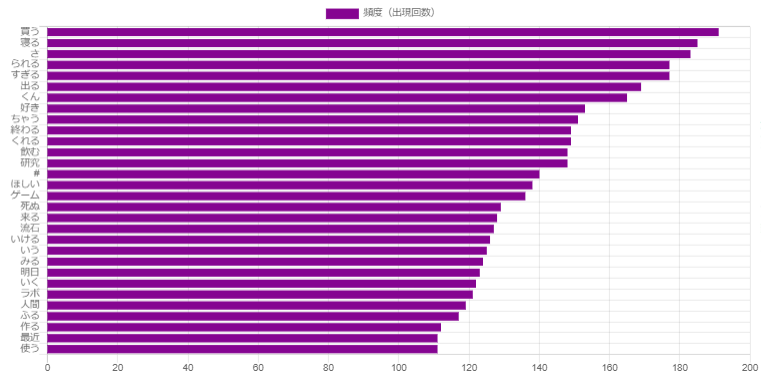

M. H.さん
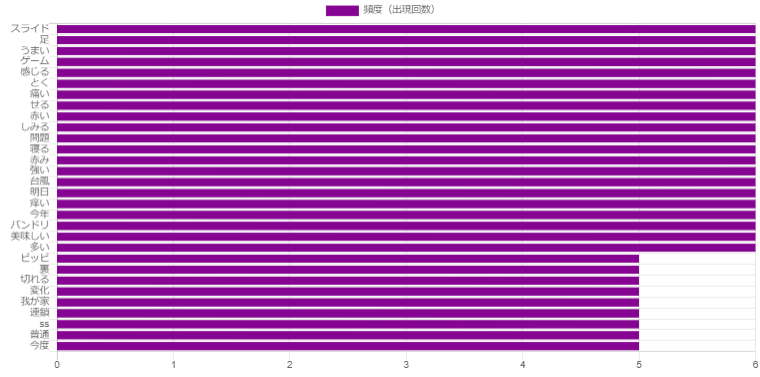
624ツイートを使用。
0.01%。ス ラ イ ド

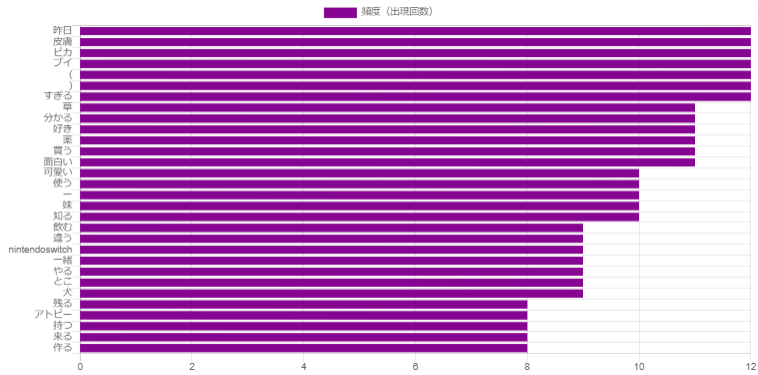
0.02%。ピカブイはかわいい(かわいい)

まとめ
本来はTwitter用にストップワードを工夫したほうが良いと思います。急ぎで見た目の良いワードクラウドを作成しました。

