
vcscrapingとは
概要
Webページ上の文字列をスクレイピングするための無料のPythonパッケージです。読み方は「ぶいしーすくれいぴんぐ」です。
- 1つのページから一連の(類似の)要素をすべて取得したい
- 複数のページから似た要素を取得したい
このような場合に使えると思います。
通常Webスクレイピングをするときは「取得したい文字列に共通するhtmlタグや要素名で検索する」と思いますが、検索条件が厳しいと取りこぼしてしまったり、検索条件が緩いと余計なものまで取得されてしまったりと、調整に苦労します。このパッケージではhtmlソースを解析して、「どんな文字列で挟むと欲しい要素が必要十分に取れるか」を自動探索してくれます。うまく行けば一度もhtmlソースを見ることなくスクレイピングができます。
利用環境&インストール方法
WinPython3.6をおすすめしています。

Google Colaboratoryが利用可能です。

pipでインストールできます。
pip install vcscrapingサンプルコード①(1つのページから)
ここでは、1つのページから一連の(類似の)要素をすべて取得する例を見てみます。ポケモンWikiの「ポケモン一覧」ページから図鑑番号(001, 002, …)を取得してみます。

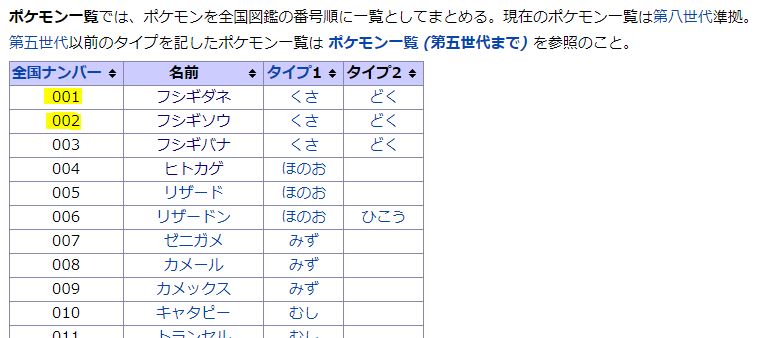
まず、ページURLと取得したい要素の1番目と2番目を用意します。このURLを1つだけ入れてインスタンスを初期化すると、シングルページモードで起動したと表示されます。
from vcscraping import vcscraping
#URLとクエリ
url = 'https://wiki.xn--rckteqa2e.com/wiki/%E3%83%9D%E3%82%B1%E3%83%A2%E3%83%B3%E4%B8%80%E8%A6%A7'
query1 = '001'
query2 = '002'
#インスタンス初期化(シングルモード)
myscraping = vcscraping(url)mode = <single page>次に、求める要素を挟み込む文字列(それぞれprefix, suffixと呼びます)を解析します。条件によりますが長い場合で十数秒かかります。
#prefix, suffixの解析
pre, suf = myscraping.find_presuf(query1, query2)-------------- setting --------------
@ single
max_text_len = 6
min_text_num = 2
max_text_num = 1000
max_presuf_len = 40
--------------- start ---------------
try 1/1 |>
---------------- end ----------------
found = 986
pre = 'r>\n<td>'
suf = '\n'
-------------------------------------結果を見ると「r>\n<td>」と「\n」(htmlソース上での表記)で挟まれた文字列を取得すると良いようで、986ヶ所が該当するようです。ポケモンは905番までですがリージョンフォーム等で重複があって986ヶ所になっています。(2022/02/27現在)
最後に、解析で得られたprefix, suffixを指定してページ内の要素を取得します。
#要素をすべて取得
texts, starts, ends = myscraping.get_between_all(pre, suf)
#始めの10個を表示
print(texts[:10])
#異なる表示方法(html中の位置を指定して表示)
print(myscraping.html[starts[0]:ends[0]])found = 986
['001', '002', '003', '004', '005', '006', '007', '008', '009', '010']
001986個が返ってきました。「texts」は取得したテキストの配列、「starts」はhtml内での各テキストの開始インデックス配列、「ends」は同終了インデックス配列(ただし1文字分後ろ)です。
サンプルコード②(複数のページから)
ここでは、複数のページから似た要素をすべて取得する例を見てみます。先程のポケモンWikiの001番フシギダネと002番フシギソウのページから、赤・緑バージョンの図鑑説明の文章を取得してみます。


まず、2つのページURLとそれぞれの要素を用意します。2つのURLを入れてインスタンスを初期化すると、マルチページモードで起動したと表示されます。
from vcscraping import vcscraping
#URLとクエリ
url1 = 'https://wiki.xn--rckteqa2e.com/wiki/%E3%83%95%E3%82%B7%E3%82%AE%E3%83%80%E3%83%8D'
url2 = 'https://wiki.xn--rckteqa2e.com/wiki/%E3%83%95%E3%82%B7%E3%82%AE%E3%82%BD%E3%82%A6'
query1 = 'うまれたときから せなかに しょくぶつの タネが あって すこしずつ おおきく そだつ。'
query2 = 'つぼみが せなかに ついていて ようぶんを きゅうしゅうしていくと おおきな はなが さくという。'
#インスタンス初期化(マルチモード)
myscraping = vcscraping(url1, url2)mode = <multi page>次に、prefix, suffixを解析します。
#prefix, suffixの解析
pre, suf = myscraping.find_presuf(query1, query2)-------------- setting --------------
@ multi
max_text_len = 98
max_presuf_len = 40
--------------- start ---------------
try 1/1 |>
---------------- end ----------------
pre = 'dd>'
suf = '<'
-------------------------------------結果、「dd>」と「<」で挟まれた文字列(のうち最初に出現するもの)を取得すると良いようです。
最後に、003番フシギバナと004番ヒトカゲの図鑑説明を取得してみます。
#新しいURL
url3 = 'https://wiki.xn--rckteqa2e.com/wiki/%E3%83%95%E3%82%B7%E3%82%AE%E3%83%90%E3%83%8A'
#インスタンス初期化
myscraping = vcscraping(url3)
#要素を1つ取得
text, start, end = myscraping.get_between(pre, suf)
#表示
print(text)
print(myscraping.html[start:end])
#新しいURL
url4 = 'https://wiki.xn--rckteqa2e.com/wiki/%E3%83%92%E3%83%88%E3%82%AB%E3%82%B2'
#インスタンス初期化
myscraping = vcscraping(url4)
#要素を1つ取得
text, start, end = myscraping.get_between(pre, suf)
#表示
print(text)
print(myscraping.html[start:end])mode = <single page>
はなから うっとりする かおりが ただよい たたかうものの きもちを なだめてしまう。
はなから うっとりする かおりが ただよい たたかうものの きもちを なだめてしまう。
mode = <single page>
うまれたときから しっぽに ほのおが ともっている。ほのおが きえたとき その いのちは おわって しまう。
うまれたときから しっぽに ほのおが ともっている。ほのおが きえたとき その いのちは おわって しまう。うまく取得できました。for文を使って全ポケモンに適用できると思います。
オプション
find_presuf(query1, query2) に付けられるオプション
| オプション | デフォルト | 意味 |
| max_text_len | ※ | 検出する文字列の最大長。デフォルトは入力クエリのうち長い方の2倍であり、それよりも長い文字列は検出されない。取得したい文字列の最大長が見積もれるのであれば指定しておくと安心。 <例> max_text_len=3(”001″のように3桁だと分かっている場合) max_text_len=1000(論文アブストのように長い文章の場合) |
| min_text_num | 2 | シングルページモードのみで有効。想定される最低検出数。これ以上の検出数に限って探索が行われる。取得したい要素が少なくとも何個以上あることが分かっている場合は指定しておくと安心。 <例> min_text_num=500(ポケモンが500種以上いることが分かっている場合) |
| max_text_num | 1000 | シングルページモードのみで有効。想定される最大検出数。これ以下の検出数に限って探索が行われる。取得したい要素が多くとも何個以下だと分かっている場合は指定しておくと安心。 <例> max_text_num=1000(ポケモンが1000種以下しかいないことが分かっている場合) |
| max_presuf_len | 40 | 探索するprefix, suffixの最大長。prefix, suffixは1文字から順に伸ばしながら探索される。デフォルトでprefix, suffixが得られない場合は少し大きくしてみる。探索時間はこれの2乗に比例するため注意。 <例> max_presuf_len=50 |
get_between(pre, suf), get_between_all(pre, suf) に付けられるオプション
| オプション | デフォルト | 意味 |
| max_text_len | 1000 | 検出する文字列の最大長。取得したい文字列の最大長が見積もれるのであれば指定しておくと安心。 <例> max_text_len=3(”001″のように3桁だと分かっている場合) max_text_len=1000(論文アブストのように長い文章の場合) |
役に立つTips
htmlの取得
インスタンスの初期化後「.html」で取得できます。このhtmlはブラウザにデコードされた状態であるため、よくある「Pythonの”requests”や”BeautifulSoup”でhtmlを取得したがブラウザ上のhtmlと微妙に異なる!スクレイピングがうまく行かない!」というトラブルを軽減しています。ただしタブ(\t)は削除してあります。実はこれだけで利用価値があるとかないとか。(→参考文献)
myscraping = vcscraping(url)
print(myscraping.html)うまくprefix, suffixが取得できない場合のコツ
例えばサンプルコード①においてフシギダネ、フシギソウといったポケモン名を指定してprefix, suffixを解析すると、失敗して「not found」と表示されます。
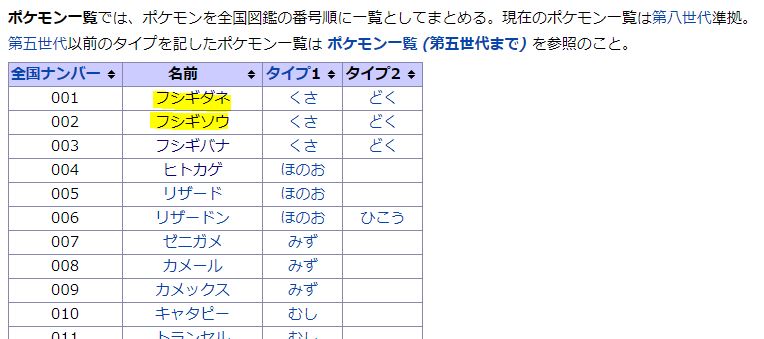
失敗の原因は次のようなことです。
- 類似箇所が多すぎる(ポケモン名だけを抽出できるpre, sufが見つからない)
- html上でポケモン名がhtmlタグやURLで分断されている(例:フシ<b>ギ</b>ダネ)
こういった場合は、ブラウザでhtmlソースを開き、書かれている内容をそのまま指定したり、あるいは少し広く指定してやります。html上に改行コードが表示されていない場合は\nを付け足す必要があることに注意してください。

#解析失敗する場合はクエリを少し広め指定するとよい
#改行場所には改行コード\nを挿入すること、ダブルクオーテーションはエスケープすること
url = 'https://wiki.xn--rckteqa2e.com/wiki/%E3%83%9D%E3%82%B1%E3%83%A2%E3%83%B3%E4%B8%80%E8%A6%A7'
#query1 = 'フシギダネ' #失敗する
#query2 = 'フシギソウ' #失敗する
query1 = '001\n</td>\n<td><a href=\"/wiki/%E3%83%95%E3%82%B7%E3%82%AE%E3%83%80%E3%83%8D\" title=\"フシギダネ\">フシギダネ'
query2 = '002\n</td>\n<td><a href=\"/wiki/%E3%83%95%E3%82%B7%E3%82%AE%E3%82%BD%E3%82%A6\" title=\"フシギソウ\">フシギソウ'
myscraping = vcscraping(url)
pre, suf = myscraping.find_presuf(query1, query2)
texts, starts, ends = myscraping.get_between_all(pre, suf)
print(texts[:5])mode = <single page>
-------------- setting --------------
@ single
max_text_len = 190
min_text_num = 2
max_text_num = 1000
max_presuf_len = 40
--------------- start ---------------
try 1/1 |>
---------------- end ----------------
found = 986
pre = 'r>\n<td>'
suf = '</a'
-------------------------------------
found = 986
['001\n</td>\n<td><a href="/wiki/%E3%83%95%E3%82%B7%E3%82%AE%E3%83%80%E3%83%8D" title="フシギダネ">フシギダネ',
'002\n</td>\n<td><a href="/wiki/%E3%83%95%E3%82%B7%E3%82%AE%E3%82%BD%E3%82%A6" title="フシギソウ">フシギソウ',
'003\n</td>\n<td><a href="/wiki/%E3%83%95%E3%82%B7%E3%82%AE%E3%83%90%E3%83%8A" title="フシギバナ">フシギバナ',
'004\n</td>\n<td><a href="/wiki/%E3%83%92%E3%83%88%E3%82%AB%E3%82%B2" title="ヒトカゲ">ヒトカゲ',
'005\n</td>\n<td><a href="/wiki/%E3%83%AA%E3%82%B6%E3%83%BC%E3%83%89" title="リザード">リザード']
その後、文字列の処理によってポケモン名や子ページのURLをあぶり出して使用してください。ダブルクオーテーションのエスケープに注意してください。
#ポケモン名あぶり出し
url_start = texts[0].find('title=\"') + len('title=\"')
url_end = texts[0].find('\">')
print(url_start, url_end)
print(texts[0][url_start:url_end])
#urlあぶり出し
url_start = texts[0].find('href=\"') + len('href=\"')
url_end = texts[0].find('\" title')
print(url_start, url_end)
print(texts[0][url_start:url_end])83 88
フシギダネ
23 74
/wiki/%E3%83%95%E3%82%B7%E3%82%AE%E3%83%80%E3%83%8D
ライセンス
不明点はお気軽にお問い合わせください。
「vcscraping を使ってみたブログを書く」○(著作権表示が必要)
「みんなも vcscraping 使おうよ!」○
「vcscraping を利用した商品を売る」○(著作権表示が必要)
「vcscraping は私が作りました!」×
「vcscraping のソースコードを修正する」×
「vcscraping のラッパーを作成する」○(著作権表示が必要)
著作権表示
vcscrapingを使用してできた著作物(商品、論文、設計、プログラム、ブログ記事等)を不特定多数の人々が閲覧できる場所に公開する際には、vcscrapingが直接的または間接的に貢献したかにかかわらず、必ず著作権表示をしなければなりません。ただしこれは、
- vcscrapingがビネット&クラリティ(=ビネクラ)によって作られたことが明示されていること
- ビネット&クラリティのURL(https://vigne-cla.com/ または同/vcscraping-tutorial/)が明示されていること
の両方が満たされていれば良いこととし、端的には
※vcscrapingはビネクラ(https://vigne-cla.com/)のソフトです
といった注釈を、十分な視認性を保って記載すれば良いこととします。また、二次的な営利利用にも本ライセンスを適用しなければなりません。例外として、vcscrapingの名称や機能のみを紹介した場合や、vcscrapingの名称や機能のみをデータベースの一要素として列挙した場合はこの限りではありません。
できること
個人利用、商用利用、創作物(商品、論文、設計、プログラム、ブログ記事等)の公開
禁止事項
ソースコードの修正・複製、pipを経由しないソースコードの配布、vcscrapingそのものやvcscrapingを利用した技術にかかる特許の出願・取得、トレードマークの主張
免責事項
vcscrapingを用いたことで生じたいかなる損害の補償もしかねます。
更新予定
とりあえずなし
更新履歴
| 1.0.3 | ステータスコードが200ではない場合の表示 |
| 1.0.2 | 安定版公開 |